





As mentioned previously, the Elastic Stack consists of four components—Elasticsearch, Kibana, Logstash, and Beats. To understand the architecture of the stash, let's look in more detail at some important terms. Please refer to the following diagram to learn more about these components:
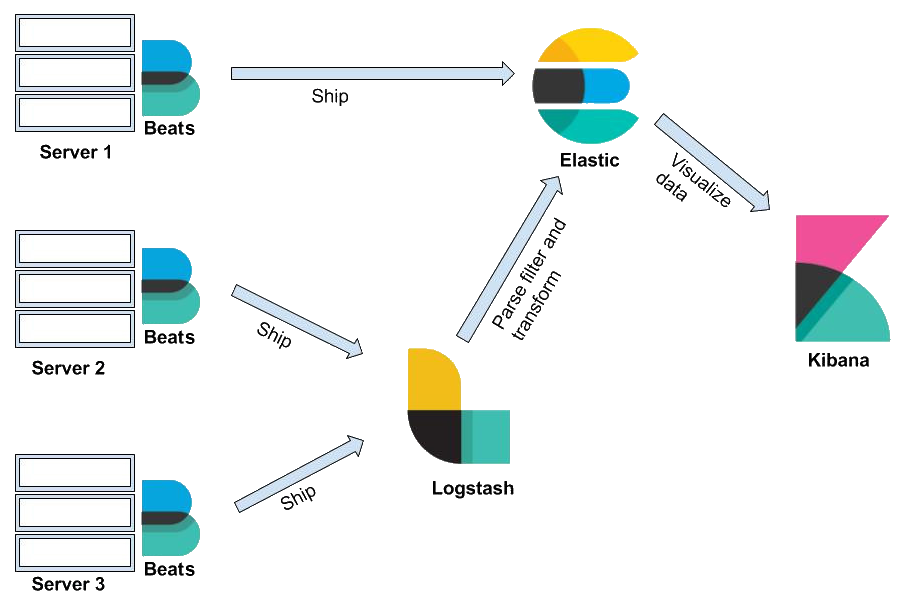
As you can see, in Elastic Stack, Beats and Logstash send data to Elasticsearch, where the data is stored. Kibana is the UI of Elastic Stack; it reads the Elasticsearch data to create graphical charts and more. Now, let's cover each of the components in detail, so let's start with Elasticsearch.







