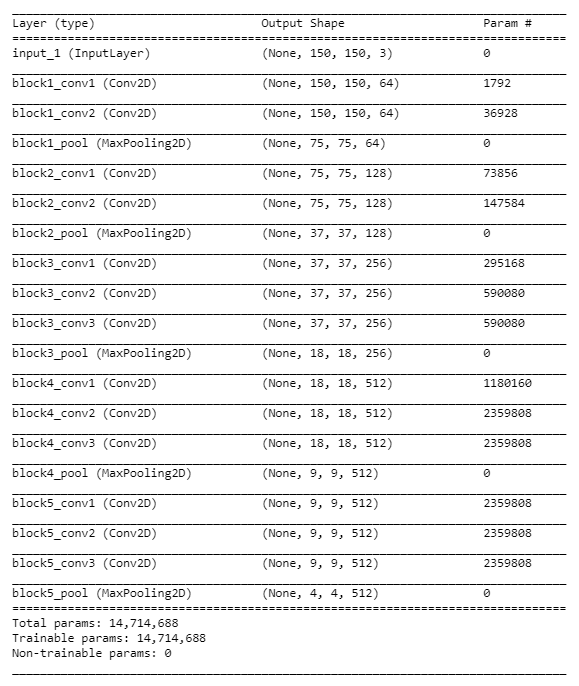
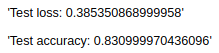
Transfer learning helps us solve a new problem using fewer examples by using information gained from solving other related tasks. It is a technique where we reuse a learned model trained on a different dataset to solve a similar but different problem. In transfer learning, we extend the learning of a pre-trained model in our network and build a new model to solve a new learning problem. The keras library in R provides many pre-trained models; we will be using one such model called as VGG16 to train our network.
-
Book Overview & Buying

-
Table Of Contents

Deep Learning with R Cookbook
By :
Deep Learning with R Cookbook
By:
Overview of this book
Deep learning (DL) has evolved in recent years with developments such as generative adversarial networks (GANs), variational autoencoders (VAEs), and deep reinforcement learning. This book will get you up and running with R 3.5.x to help you implement DL techniques.
The book starts with the various DL techniques that you can implement in your apps. A unique set of recipes will help you solve binomial and multinomial classification problems, and perform regression and hyperparameter optimization. To help you gain hands-on experience of concepts, the book features recipes for implementing convolutional neural networks (CNNs), recurrent neural networks (RNNs), and Long short-term memory (LSTMs) networks, as well as sequence-to-sequence models and reinforcement learning. You’ll then learn about high-performance computation using GPUs, along with learning about parallel computation capabilities in R. Later, you’ll explore libraries, such as MXNet, that are designed for GPU computing and state-of-the-art DL. Finally, you’ll discover how to solve different problems in NLP, object detection, and action identification, before understanding how to use pre-trained models in DL apps.
By the end of this book, you’ll have comprehensive knowledge of DL and DL packages, and be able to develop effective solutions for different DL problems.
Table of Contents (11 chapters)
Preface
Understanding Neural Networks and Deep Neural Networks
 Free Chapter
Free Chapter
Working with Convolutional Neural Networks
Recurrent Neural Networks in Action
Implementing Autoencoders with Keras
Deep Generative Models
Handling Big Data Using Large-Scale Deep Learning
Working with Text and Audio for NLP
Deep Learning for Computer Vision
Implementing Reinforcement Learning
Other Books You May Enjoy