

Suppose we are given documents and would like to classify other documents based on their word frequency counts. For example, the 120 most frequently occurring words found in the Project Gutenberg e-book of the King James Bible are as follows:
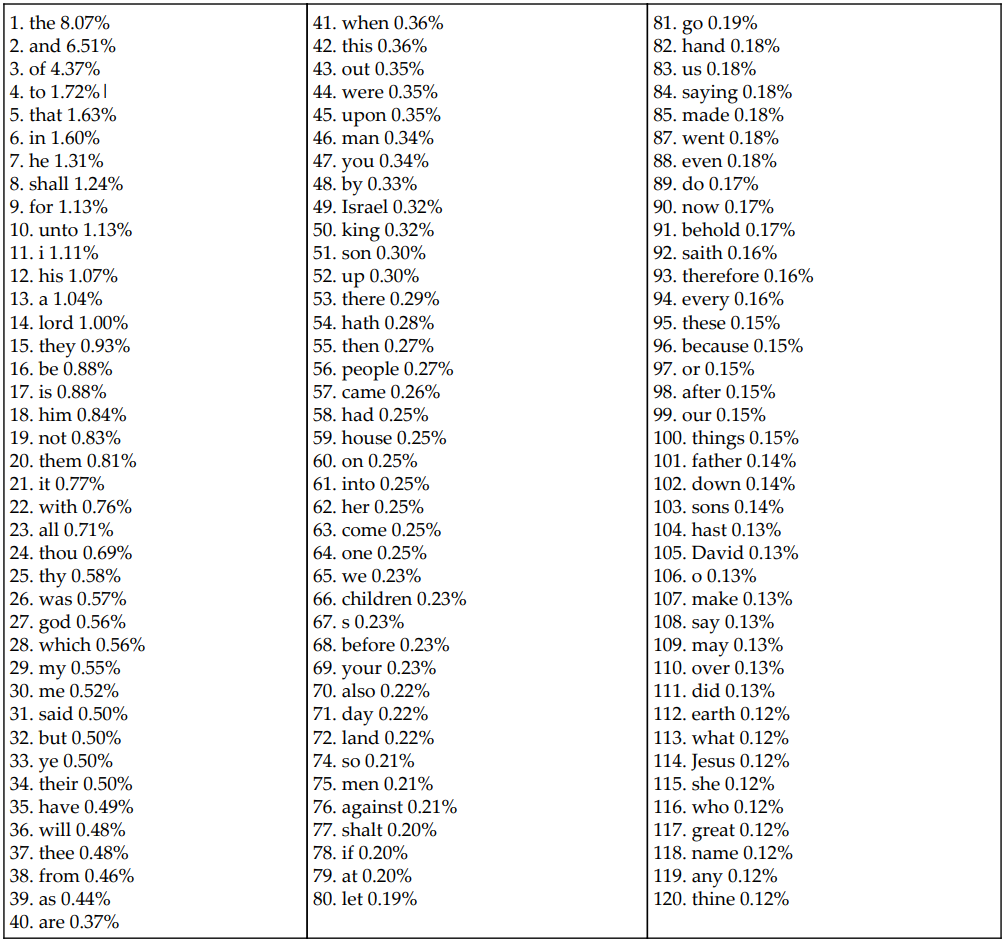
The task is to design a metric that, given the word frequencies for each document, would accurately determine how semantically close those documents are. Consequently, such a metric could be used by the k-NN algorithm to classify the unknown instances in the new documents based on the existing documents.
Suppose that we consider, for example, N most frequent words in our corpus of documents. Then, we count the word frequencies for each of the N words in a given document and put them in an N-dimensional vector that will represent that document. Then, we define a distance between two documents to be the distance (for example, Euclidean) between the two-word frequency vectors of those documents.
The problem with this solution is that only certain words represent the actual content of the book, and others need to be present in the text because of grammar rules or their general basic meaning. For example, out of the 120 most frequently encountered words in the Bible, each word is of different importance. In the following table, we have highlighted the words that have both a high frequency in the Bible and an important meaning:
|
|
|
These words are less likely to be present in mathematical texts, for example, but more likely to be present in texts concerned with religion or Christianity.
However, if we just look at the six most frequent words in the Bible, they happen to be less useful with regard to detecting the meaning of the text:
|
|
|
Texts concerned with mathematics, literature, and other subjects will have similar frequencies for these words. Differences may result mostly from the writing style.
Therefore, to determine a similarity distance between two documents, we only need to look at the frequency counts of the important words. Some words are less important—these dimensions are better reduced, as their inclusion can lead to misinterpretation of the results in the end. Thus, what we are left to do is choose the words (dimensions) that are important to classify the documents in our corpus. For this, consultProblem 6.