The raw data layer contains the one-to-one copies of files from the source systems. The copies are stored to make sure that any data that arrives is preserved in its original form. After storing the raw data, some checks can be done to make sure that the data can be processed by the rest of the ETL pipeline, such as a checksum.
Security
We'll look at data security first. All modern software and data systems must be secure. By security requirements, we mean all aspects related to ensuring that the data in a system cannot be viewed or deleted by unauthorized people or systems. It entails identity and access management, role-based access, and data encryption.
Basic Protection
In any data project, security is a key requirement. The basic level of data protection is to require a username-password combination for anyone who can access the data: customers, developers, analysts, and so on. In all cases, the passwords should be evaluated against a strong password policy and must be changed on a regular basis. Passwords should never be stored in plain text; instead, they should always be in a salted and hashed form so that even system administrators cannot retrieve the actual passwords. The security levels themselves depend on the Availability, Integrity, and Confidentiality (AIC) rating, which we'll explain in the following paragraph. Suffice to say that highly secure data should not only be protected with a username and password. Multi-factor authentication is a way of adding a security layer by making use of a second or even third authentication method alongside password protection, such as an SMS message on your phone, a fingerprint ID, or a dedicated security token generator.
The AIC Rating
Data security in organizations can be classified with the AIC rating (sometimes the CIA rating is also used, but this causes confusion with the abbreviation for the Central Intelligence Agency). Each data source and application should be categorized into three dimensions:
- A = availability: The level of protection against data loss in cases of system failure or upgrades. If data loss must be prevented at all times, for example, for payment transactions, the level is high. If data loss is annoying but not terrible, for example, spam emails, the level is low.
- I = integrity: The level of consistency and accuracy that the dataset must uphold during its life cycle. Some data might be removed or updated without any consequences; those datasets will receive a low integrity rating. However, if it's crucial that data records are preserved for a long time, for example, tax records, the rating will go up.
- C = confidentiality: The level of personal details of a person or company that is included in the dataset. If personal details such as names or addresses are stored, it's likely that the rating is high. The highest level of confidentiality is reserved for datasets that contain very private data, such as credit card numbers or passwords.
Each of these dimensions gets a rating from 1 to 3. Thus, a dataset with an AIC rating of 111 is considered to be less risky and vulnerable compared to a dataset with a rating of 333. You could argue that when data from a 111 system falls into the wrong hands (a hacker or competing organization), it's no big deal. However, when data from a 333 system ends up "on the street," you're in serious legal trouble and might even be out of business. When it comes to securing data, each category should imply certain measurements within your company. For example, any dataset with a C rating of 3 can only be accessed with multi-factor authentication.
Role-Based Access
In the raw data layer, all data files must be governed with role-based access control (RBAC) to ensure that no data falls into the wrong hands. Every principal (human or machine account) has one or more roles. Each role has one or more permissions to a database, file share, table, or other pieces of data. With the right permissions, files can be read by humans (for example, data scientists that require access to the raw data); write access is only available for software that imports the data from the source systems. Every file must be secured. In many cases, the actual security is inherited from a higher directory. The file structure proposed in Figure 2.6: Sample data lake architecture, allows security to be configured per source system or per period. It should also be possible to give data scientists access to a part of the data store temporarily, for example, to copy data to a machine learning environment. Modern security frameworks and identity and access management systems such as Microsoft Active Directory and Amazon AWS Identity and Access Management (IAM) have these options available. The following figure shows these:
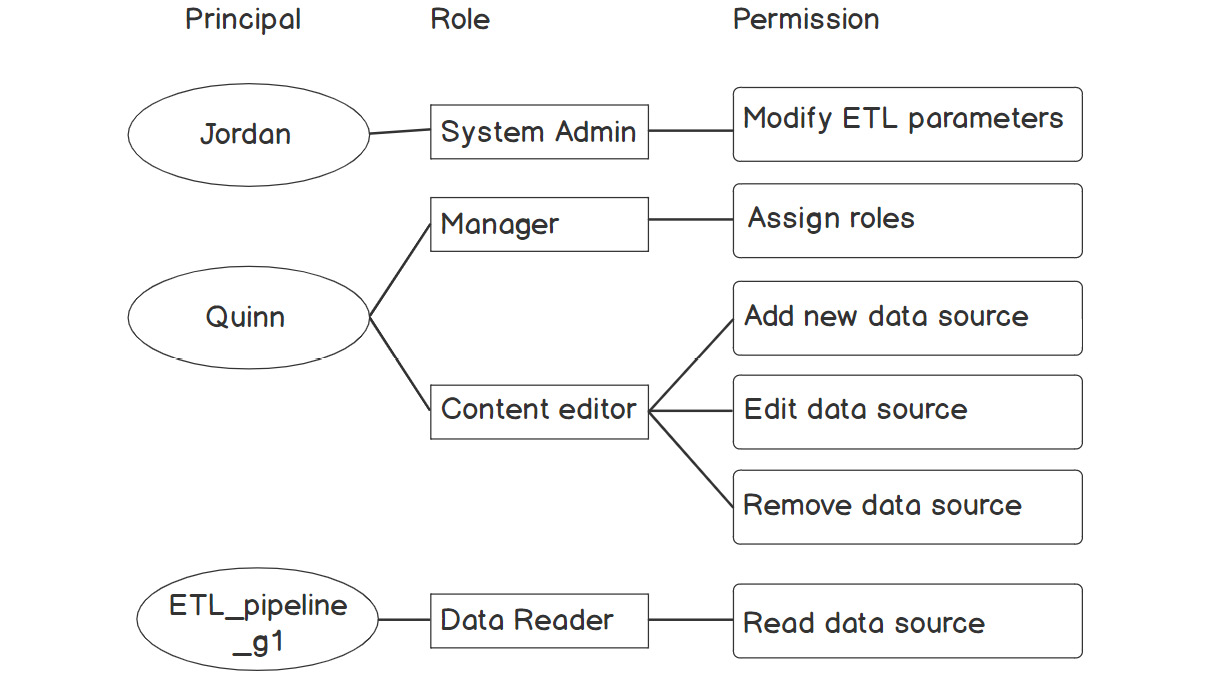
Figure 2.8: Simplified sample of roles and permissions of a data importing system
The preceding figure is a highly simplified role-based access diagram that has been sketched to illustrate the relations between principals, roles, and permissions. In this example, Jordan has the role of System Admin and is therefore allowed to modify the parameters of an ETL pipeline. However, he cannot read the actual contents of the data sources since he has no permissions. Quinn has two roles: Manager and Content Editor. She can assign roles to other principals and add, edit, and remove data sources. ETL_pipeline_g1 is a non-human principal, namely an account that a piece of software uses to access data and execute tasks. It has the role of Data Reader and therefore has permission to read the data from the data sources.
Encryption
Data at rest (stored on disk) and in motion (transferred across a network) should be encrypted to prevent third parties and hackers from accessing it. By encrypting data, a hacker who intercepts the data or reads it straight from disk still cannot get to its content; it will just be a scrambled array of characters. To read the data, you must be in possession of a private key that has a relation to the public key that the data was encrypted with (with asymmetric encryption, which is by far the most popular mechanism). These private keys must, therefore, be kept secure at all times, for example, in a special purpose key store. All modern cloud infrastructure providers have such a key store as a service in their offerings.
There are many types of encryption possible. Advanced Encryption Standard (AES) and Rivest-Shamir-Adleman (RSA) are two examples of popular asymmetric encryption algorithms. These can both be used to encrypt data at rest and in motion, although some performance considerations might apply; RSA is a bit slower than AES. What's more important is to choose the size of the keys; the more bits, the harder it is to break the encryption with a brute-force attack. Currently, 256 bits is considered to be a safe key size.
Keys should never be stored in places with more or less open access, for example, sticky notes or Git repositories. It's good practice to rotate your keys, which means that they alter after a certain period (say, a month). This makes sure that even if keys are accidentally stored in a public place, they can only be used for a limited period of time.
At the core of data security are four basic principles:
- Security starts with basic protection, such as strong and rotating passwords. All users are registered in a central identity and access management system.
- All access to data is regulated with permissions. Permissions can be attached to roles, and roles can be assigned to users. This is called role-based access.
- The data security measurements are related to the AIC rating of a dataset. A higher rating indicates that more security controls should be put into place.
- Data at rest and in motion can be encrypted to protect it from intruders.
Let's understand this better by going through the next exercise.
Exercise 2.02: Defining the Security Requirements for Storing Raw Data
For this exercise, imagine that you are creating a new data environment for an ambulance control room. The goal of the system is to gather as much useful information as possible from government and open data sources in order to direct ambulances on their way to a 911 call once it arrives. The core data sources that must be stored are the 911 calls; this is combined with maps data, traffic information, local news from the internet, and other sources. It's apparent that such systems are prone to hacking and a wrong/fake call could lead to medical mistakes or the late arrival of emergency personnel.
In this exercise, you will create a security plan for the ambulance control room. The aim of this exercise is to become familiar with the security requirements of a system where data protection plays an important role.
Now, answer the following questions for this use case:
- Consider the data source of your application. Who is the owner of the data? Where is the data coming from?
The prime data source is the 911 calls that come from the people who need help. The call data is owned by the person who makes the call.
- What is a potential security threat? A hacker on the internet? A malicious employee of your company? A physical attack on your data center?
Potential security threats are hackers on the internet, fake phone callers, employees who might turn against the company, physical attackers on the data center, terrorists, and many more.
- Try to define the AIC rating of the dataset. What are the levels (from 1 to 3) for the availability, integrity, and consistency of the data?
The phone calls have an AIC rating of 233. The availability is reasonably high but retrieving the data, in retrospect, is not as important as being able to respond to the calls once they arrive; thus, the overall availability is 2. The infrastructure for making the calls has an availability rating of 3. The integrity rating is 3 since the ambulance control room must be able to rely on the data; the location, time, and call quality are all very important aspects of the data. The confidentiality rating is also 3 since the calls themselves will contain many privacy-related details and confidential information.
- Regarding the AIC rating, which measurements should you take to secure the data? What kind of identity and access management should you put in place? What kind of data encryption will you use? Consider the roles and permissions for accessing the data, as well as password regulations and multi-factor authentication.
Considering the high integrity and confidentiality ratings, the security around the call data must be very good. The data should only be accessed by registered and authorized personnel of the control room, who have been given access by a senior manager. The access controls must be audited on a regular basis. Two-factor authentication, a strong password policy, and encryption of all data at rest and in motion must be put in place in order to minimize the risk of security breaches and hacks from outside.
By completing this exercise, you have created a security plan for a demanding system. This helps when setting the requirements for systems in your own organization.
Scalability
Scalability is the ability of a data store to increase in size. Elasticity is the ability of a system to grow and shrink on demand, depending on the need at hand. For the sake of simplicity, we address both scalability and elasticity under one requirement: scalability.
In traditional data warehousing projects, a retention policy was very important in the raw data layer since it prevented the disks from getting full. In modern AI projects, what we see is that it's best to keep the raw data for as long as possible since (file) storage is cheap, scalable, and available in the cloud. Moreover, the raw data often provides the best source for model training in a machine learning environment, so it's valuable to give data scientists access to many historical data files.
To cater for storing this much data on such a large scale, a modern file store such as Amazon S3 or Microsoft Azure ADLS Gen2 is ideally suited. These cloud-based services can be seen as the next generation of Hadoop file stores, where massive parallel file storage is made easily available to its consumers. For an on-premise solution, Hadoop HDFS is still a good solution.
Using the same example of PacktBank, the new data lake for AI must start small but soon scale to incorporate many data sources of the bank.
The architects of PacktBank defined the following set of requirements for the new system:
- The data store should start very small since we will first do a proof-of-concept with only test data. The initial dataset is about 100 MB in size.
- The data store should be able to expand rapidly toward a size where all the data from hundreds of core systems will be stored. The expected target size is 20 TB.
- There will be a retention policy forced on some parts of the data since privacy regulations enforce that certain sensitive data be removed after 7 years. The data store should be able to shrink back to a smaller size (~15 TB) if needed, and the costs associated with the data store should follow proportionally.
Time Travel
For many organizations, it is important to be able to query data in the past. It's very valuable and is often required by laws or regulations to be able to answer questions such as "how many customers were in possession of product 3019 one month ago?" or "which employees had access to document 9201 on 14 March 2018?". This ability is called time travel, and it can be embedded in data storage systems.
Raw data must be stored in a way so that its origins and time of storage are apparent. Many companies choose to create a directory structure that reflects the daily or hourly import schedule, like so:
Figure 2.9: Example of a directory structure for raw data files
In the preceding figure, a file that arrives on a certain date and time gets placed in a directory that reflects its arrival date. We can see that on February 2, 2019, a daily export was stored. There is also a file containing ERROR which possibly indicates a failed or incomplete import. The full import log is stored in a text file in the same folder. By storing the raw data in this structure, it's very easy for an administrator to ask questions about the source data in the past; all they must do is browse to the right directory on the filesystem.
Retention
Data retention requirements define in what way data is stored to meet laws and regulations or to preserve disk space by deleting old files and data records. Since it's often convenient and useful in a modern AI system to keep storing all the data (after all, data scientists are data-hungry), a retention policy is not always necessary from a scalability perspective. As we saw when exploring the scalability requirement, many data stores can store massive amounts of data cheaply. However, a retention requirement (and therefore, a policy) might be needed because of laws and regulations. For example, in the EU's GDPR regulations, it's stated that data must be stored "for the shortest time possible." Some laws and regulations are specific for industries, for example, call data and metadata in a telecom system may only be stored for 7 years by a telecom provider.
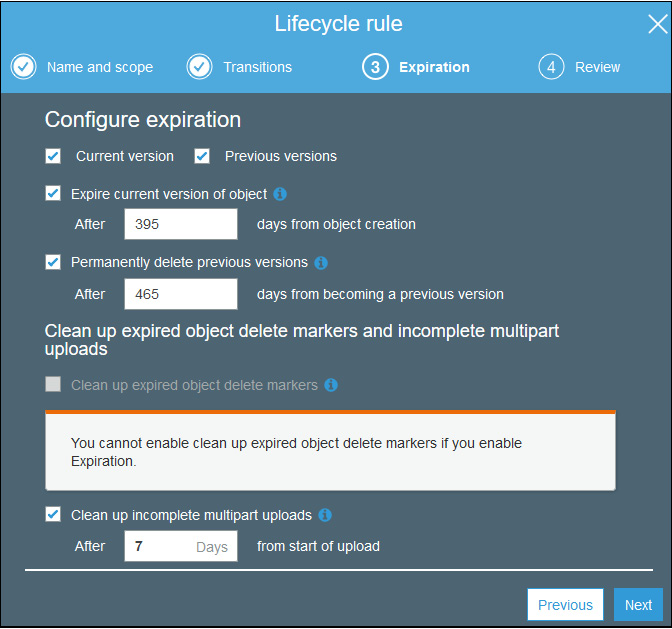
To cater to retention requirements, the infrastructure and software of your data lake should have a means of removing and/or scrambling/anonymizing data periodically. In modern file stores and databases, policies can be defined in the tool itself and the tool automatically implements the retention mechanisms. For example, Amazon S3 supports lifecycle policies in which data owners can specify what should happen with the data over time, as shown in the following figure:
Figure 2.10: Retention rules in Amazon S3
When storing data in an on-premise data store that does not support retention (for example, MySQL or a regular file share), you'll have to write code yourself that periodically runs through all your data and deletes it, depending on the parameters that have been defined for your policy.
Metadata and Lineage
Metadata is data about data. If we store a file on a disk, the actual data is the contents of the file. The metadata is its name, location, size, owner, history, origin, and many other properties. If metadata is correctly and consistently registered for each dataset (a file or database record), this can be used to track and trace data across an organization. This tracking and tracing is called lineage, and it can be mostly automated with modern tooling.
If the requirements for metadata management and lineage requirements are in place, every data point in the pipeline must be traced back to its source if required. This can be requested in audits or for internal data checks. For the raw data layer, it implies that for every data source file, we store a set of metadata, including the following:
- Filename: The name of the file
- Origin: The location or source system where the data comes from
- Date: The timestamp when the data entered the data layer
- Owner: The data owner who is responsible for the file's contents
- Size: The file size
For data streams, we store the same attributes as metadata but they are translated to the streaming world; for example, the stream name instead of a filename. In Chapter 3, Data Preparation, we'll discuss lineage in detail and provide an exercise for building lineage into ETL jobs.
A further extension to the security model and metadata-driven lineage, once in place, is consent management. Based on the metadata of the raw data files, a data owner can select which roles or individuals have access to its files. In that way, it's possible to create a data-sharing environment where each data owner can take responsibility for the availability of their own data.
Now, we have discussed the main requirements for the raw data layer: security, scalability, time travel, retention, and metadata. Keep in mind that these topics are important for any data storage layer and technology. In the next section, we will explore these requirements for the historical data layer and add availability as an important requirement that is most apparent for the technology and data in that layer.






 Free Chapter
Free Chapter