

Classifying supervised, unsupervised, and reinforcement learning
ML is a very extensive field of study; that's why it is very important to have a clear definition of its sub-divisions. From a very broad perspective, we can split ML algorithms into two main classes: supervised learning and unsupervised learning.
Introducing supervised learning
Supervised algorithms use a class or label (from the input data) as support to find and validate the optimal solution. In Figure 1.2, there is a dataset that aims to classify fraudulent transactions from a bank:
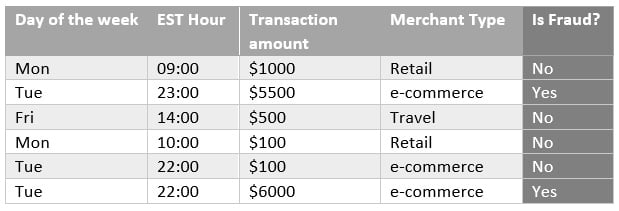
Figure 1.2 – Sample dataset for supervised learning
The first four columns are known as features, or independent variables, and they can be used by a supervised algorithm to find fraudulent patterns. For example, by combining those four features (day of the week, EST hour, transaction amount, and merchant type) and six observations (each row is technically one observation), you can infer that e-commerce transactions with a value greater than $5,000 and processed at night are potentially fraudulent cases.
Important note
In a real scenario, we should have more observations in order to have statistical support to make this type of inference.
The key point is that we were able to infer a potential fraudulent pattern just because we knew, a priori, what is fraud and what is not fraud. This information is present in the last column of Figure 1.2 and is commonly referred to as a target variable, label, response variable, or dependent variable. If the input dataset has a target variable, you should be able to apply supervised learning.
In supervised learning, the target variable might store different types of data. For instance, it could be a binary column (yes or no), a multi-class column (class A, B, or C), or even a numerical column (any real number, such as a transaction amount). According to the data type of the target variable, you will find which type of supervised learning your problem refers to. Figure 1.3 shows how to classify supervised learning into two main groups: classification and regression algorithms:

Figure 1.3 – Choosing the right type of supervised learning given the target variable
While classification algorithms predict a class (either binary or multiple classes), regression algorithms predict a real number (either continuous or discrete).
Understanding data types is important to make the right decisions on ML projects. We can split data types into two main categories: numerical and categorical data. Numerical data can then be split into continuous or discrete subclasses, while categorical data might refer to ordinal or nominal data:
- Numerical/discrete data refers to individual and countable items (for example, the number of students in a classroom or the number of items in an online shopping cart).
- Numerical/continuous data refers to an infinite number of possible measurements and they often carry decimal points (for example, temperature).
- Categorical/nominal data refers to labeled variables with no quantitative value (for example, name or gender).
- Categorical/ordinal data adds the sense of order to a labeled variable (for example, education level or employee title level).
In other words, when choosing an algorithm for your project, you should ask yourself: do I have a target variable? Does it store categorical or numerical data? Answering these questions will put you in a better position to choose a potential algorithm that will solve your problem.
However, what if you don't have a target variable? In that case, we are facing unsupervised learning. Unsupervised problems do not provide labeled data; instead, they provide all the independent variables (or features) that will allow unsupervised algorithms to find patterns in the data. The most common type of unsupervised learning is clustering, which aims to group the observations of the dataset into different clusters, purely based on their features. Observations from the same cluster are expected to be similar to each other, but very different from observations from other clusters. Clustering will be covered in more detail in future chapters of this book.
Semi-supervised learning is also present in the ML literature. This type of algorithm is able to learn from partially labeled data (some observations contain a label and others do not).
Finally, another learning approach that has been taken by another class of ML algorithms is reinforcement learning. This approach rewards the system based on the good decisions that it has made autonomously; in other words, the system learns by experience.
We have been discussing learning approaches and classes of algorithms at a very broad level. However, it is time to get specific and introduce the term model.