-
Book Overview & Buying

-
Table Of Contents

Data Wrangling on AWS
By :
Data Wrangling on AWS
By:
Overview of this book
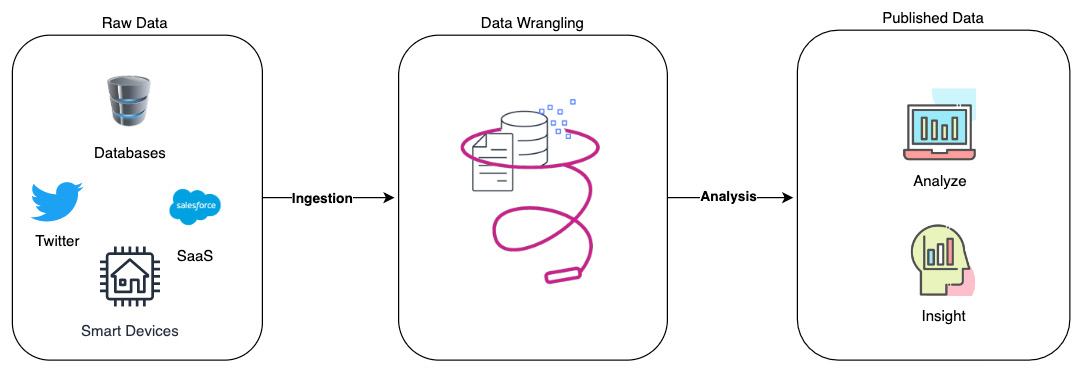
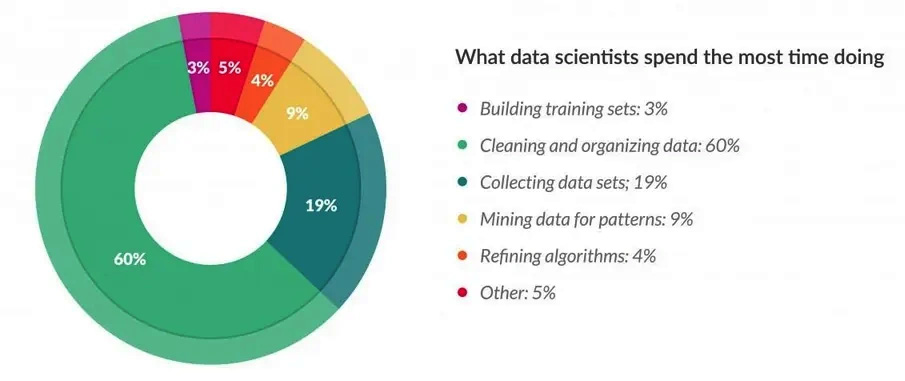
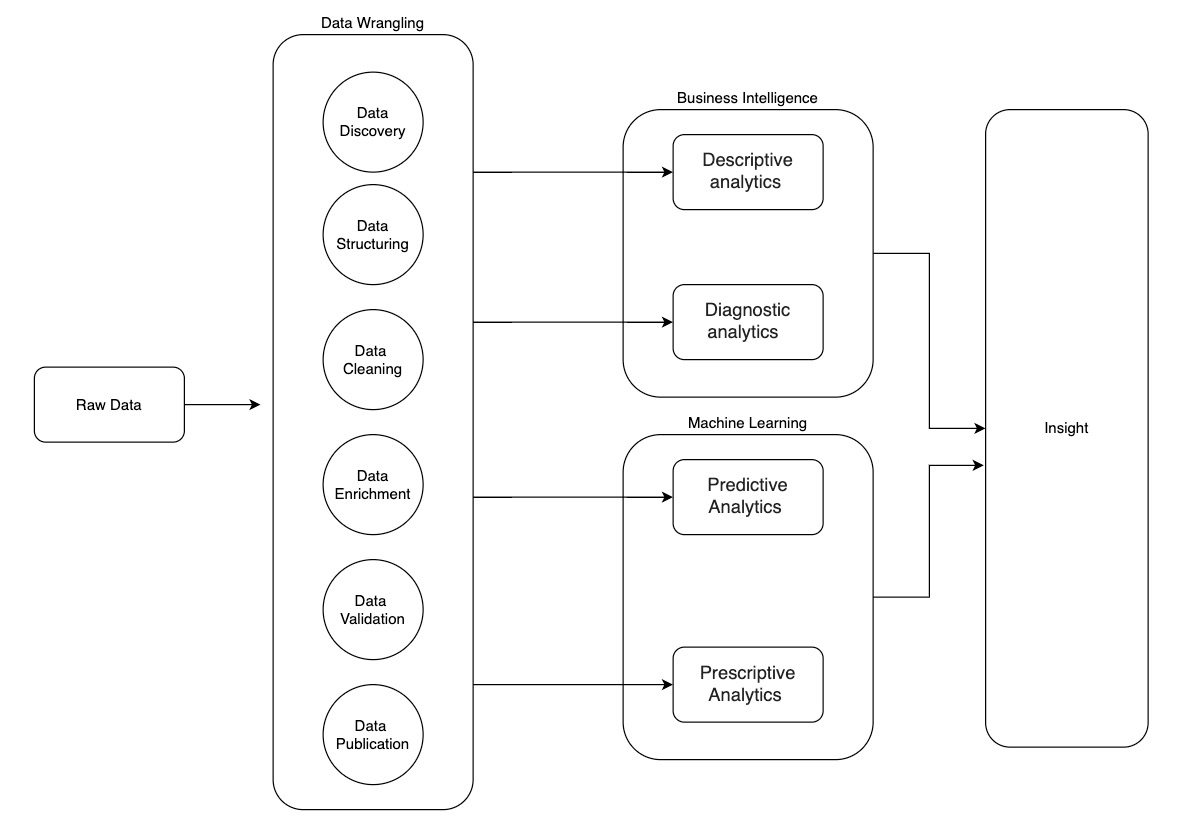
Data wrangling is the process of cleaning, transforming, and organizing raw, messy, or unstructured data into a structured format. It involves processes such as data cleaning, data integration, data transformation, and data enrichment to ensure that the data is accurate, consistent, and suitable for analysis. Data Wrangling on AWS equips you with the knowledge to reap the full potential of AWS data wrangling tools.
First, you’ll be introduced to data wrangling on AWS and will be familiarized with data wrangling services available in AWS. You’ll understand how to work with AWS Glue DataBrew, AWS data wrangler, and AWS Sagemaker. Next, you’ll discover other AWS services like Amazon S3, Redshift, Athena, and Quicksight. Additionally, you’ll explore advanced topics such as performing Pandas data operation with AWS data wrangler, optimizing ML data with AWS SageMaker, building the data warehouse with Glue DataBrew, along with security and monitoring aspects.
By the end of this book, you’ll be well-equipped to perform data wrangling using AWS services.
Table of Contents (19 chapters)
Preface

Part 1:Unleashing Data Wrangling with AWS
 Free Chapter
Free Chapter
Chapter 1: Getting Started with Data Wrangling
Part 2:Data Wrangling with AWS Tools
Chapter 2: Introduction to AWS Glue DataBrew
Chapter 3: Introducing AWS SDK for pandas
Chapter 4: Introduction to SageMaker Data Wrangler
Part 3:AWS Data Management and Analysis
Chapter 5: Working with Amazon S3
Chapter 6: Working with AWS Glue
Chapter 7: Working with Athena
Chapter 8: Working with QuickSight
Part 4:Advanced Data Manipulation and ML Data Optimization
Chapter 9: Building an End-to-End Data-Wrangling Pipeline with AWS SDK for Pandas
Chapter 10: Data Processing for Machine Learning with SageMaker Data Wrangler
Part 5:Ensuring Data Lake Security and Monitoring
Chapter 11: Data Lake Security and Monitoring
Index