

What is AI?
AI is a term often used to show that organizations use state-of-the-art technologies. Interestingly, this term has already existed for over 60 years. Back then, it was defined as the science and engineering of making intelligent machines (Professor John McCarthy, Stanford University, accessed June 2021, http://jmc.stanford.edu/artificial-intelligence/what-is-ai/). Unfortunately for us, that leaves a lot open for interpretation, which is also why the term AI has had so many different meanings over the years.
AI often goes hand in hand with data science, which is a field combining science, engineering, mathematics, and statistics. Its purpose is very much in the name: it's the science of extracting insights from data, to make sense out of the very raw data we might get from any applications or databases we have. Using this field, we can get data, clean it up, train a model based on that data, and integrate that model into our applications to generate predictions on new incoming data.
To fully grasp what AI can do, we need to understand a couple of different terms, often used together with AI: machine learning, deep learning, supervised learning, and unsupervised learning. Next to that, it helps to be familiar with a typical structure of the process it takes to create an AI model.
Understanding the definition of AI
We can find many different definitions for AI, which generally have three main aspects in common:
- Computers
- Executing an intelligent task
- Like a human would do it
Computers come in different forms and can mean software or hardware; it can be an application running locally on someone's laptop or an actual robot. The part of the definition of AI which is more open to interpretation is the intelligent task executed like a human would. What do we consider intelligent? If we think about an intelligent task performed by a human, we could also take the example of a calculator. The more expensive calculators are able to make complex calculations within seconds, which would take a mathematician some time to figure out. However, if you asked someone whether a calculator should be considered AI, the answer would most probably be no.
So, then the question arises: what is intelligence? Fortunately, there are many philosophers who are spending their academic life on answering this question, so let's assume that is outside the scope of this book. Instead, let's agree that the threshold of what is considered to be AI evolves over the years. With new developments come new expectations. Whereas we first considered beating the world champion in chess to be the ultimate level of AI, we now wonder whether we can create fully autonomous self-driving cars.
Some of these new developments have been new types of algorithms that allow us to train even more intelligent models. These algorithms are often categorized as machine learning and deep learning algorithms and are important to understand to know when to use what. We will explore both of these terms in more detail.
Understanding machine learning
If we think back to our simple yet high-performing calculator, you can imagine the intelligence of such a machine being created by a rule-based system. Adding one plus one is always two. This kind of mathematical rule and many others can be programmed into a calculator to empower it to count. This approach is also called using regular expressions and can still be very useful today. It is considered the most rudimentary approach to accomplishing AI but can still yield quick and clear results.
If you want smarter AI, however, you might want to work with techniques where a model is not fully programmed based on rules we humans decide on, but instead is self-learning. Because of this term, it is often thought AI is self-improving and will continuously improve over time until it reaches the singularity. What self-learning actually means is that we do not have to explicitly tell AI how to interpret data coming in. Instead, we show AI a lot of examples and, based on those examples, the model we train will decide how a pattern of variable values influence a specific prediction.
For example, what if you sell laptops and you want to advertise the right laptop to the right person? You could work with a rule-based system where you would create groups based on demographic data, such as women younger than 30, women who are 30 or older, and the same for men younger than 30 and men who are 30 or over. We would have four different groups we would use different marketing strategies on, assuming that every woman younger than 30 has the same requirements when buying a new laptop.
Instead of this, we of course want to pick up on patterns we may not have realized ourselves but can still be found in the data. That is when we would use machine learning to have a self-learning model that looks at the data and learns which variables or features make you interested in specific laptop requirements. It could very well be that, based on this self-learning, we find out that we have different groups we should use different marketing strategies on. For example, we may have a subgroup of both men and women under 30 who love to play online games and need different requirements than men and women under 30 who only use their laptop for work.
Compared to regular expressions, using machine learning to accomplish AI is considered a more sophisticated approach. To create a machine learning model, we take our data, and we choose an algorithm to train a model. These terms are visualized in Figure 1.1:

Figure 1.1 – Creating a machine learning model
As seen in Figure 1.1, the data you have and the algorithm you choose are the inputs, and the model you train is the output. The algorithm we select will decide how we want to look at our data. Do we want to classify our data? Do we want to create a regression model where we want to predict a numeric value? Or do we want to cluster our data into different groups? This information is encapsulated in the algorithm you choose when training a model.
Now that we understand what machine learning is, how does it then differ from deep learning?
Understanding deep learning
Machine learning has already opened up a world of possibilities for data scientists. Instead of spending hours and hours exploring data and calculating correlations, covariances, and other statistical metrics to find patterns in the data, we could just train a model to find that pattern for us.
Machine learning was initially done with structured data fitting nicely into columns and rows. Soon, people wanted more. Data scientists wanted to also be able to classify images or to understand patterns in large text documents. Unfortunately, the algorithms within machine learning could not handle these kinds of unstructured data very well, mostly because of the complexity of the data itself. It is said that an image says a thousand words and it is indeed true that even one single pixel of an image holds a lot of information that can be analyzed in many different ways.
With the emergence of cloud computing and the improvements in processing units, a new subfield within machine learning arrived. Instead of the simpler CPUs (Central Processing Units), we now have the more powerful GPUs (Graphical Processing Units) that can process complex data such as images at a much faster rate. With more power comes more cost, but thanks to the cloud, we have GPUs available on demand and only have to pay for when we use them.
Once we had the processing power, we still needed different algorithms to extract the patterns in these kinds of unstructured data. Since we wanted to perform these tasks just like humans would do it, researchers turned to the brain and looked at how the brain processes information. Our brain is made up of cells that we call neurons, which process information on many different layers. So, when looking at unstructured data, researchers tried to recreate a simplified artificial neural network in which these neurons and layers are simulated. This turned out to work very well and resulted in the subfield of deep learning. Now, we can take images and classify them or detect objects in them using the subfield we call Computer Vision. And we can use Natural Language Processing (NLP) to extract insights from text.
We have now talked about AI, machine learning, and deep learning. In Figure 1.2, a visual overview is shown of these three terms:
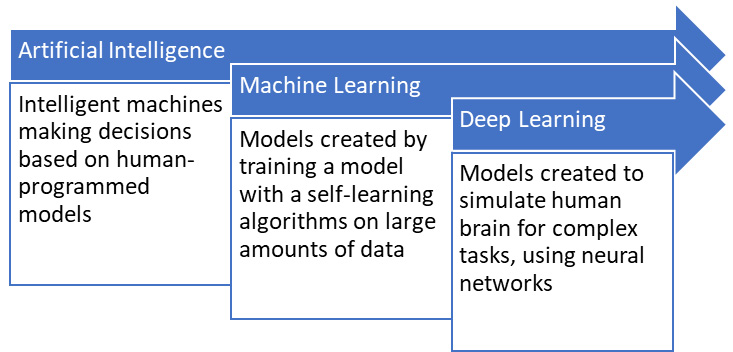
Figure 1.2 – Overview of AI, machine learning, and deep learning
As seen in Figure 1.2, the three terms we just discussed are related to each other. AI is often considered to be the umbrella term for anything we do to let a machine execute an intelligent task like a human would do it. One approach to this has been machine learning, in which we train models not by teaching them the rules, but by letting the models learn themselves. All we do is offer the data and algorithm (which defines the task) to train a model. And lastly, we have deep learning as a subfield of machine learning, in which special algorithms are used to better handle complex tasks such as understanding patterns in unstructured data.
Besides these three main terms that are necessary to understand before working with AI in Power BI, we also need to make a distinction between supervised and unsupervised learning. These two approaches divide the algorithms we will use into two categories. Understanding the difference between them helps us to know what we need to include in our datasets that we will use as input for a model we want to train.
Understanding supervised and unsupervised learning
The purpose of AI is that you want to predict something. You want to predict something such as whether someone is more likely to buy a washing machine or a new fridge. Or you want to predict how many apples you will sell on a given day so that you know how much to supply your store with. What we want to predict is often called a label or tag. Sometimes we have training data that includes that label, and sometimes we do not.
If we run a store that sells apples, we can take our historical data, which we can combine with extra data such as weather data and day of the week. On cold Mondays, no one may want to buy apples but on sunny Fridays, you may run out of apples before noon. Because we can see in our historical data how many apples we have sold in the past when specific conditions were met, we have training data that includes a label, namely number of apples sold. If we know the label, we call this supervised learning.
What about the laptops we were selling? Let's say we have customer data including demographic information such as age and gender. But we may also have data on what they use the laptops for: online games or work. In this case, we do not know how many different groups we should create different marketing strategies for. So, the groups we want to categorize them into do not exist in the training data. Therefore, we have no labels in our training data and thus are doing unsupervised learning.
It is good to make the distinction between these different terms because it will help you understand what is required from your data and what you can expect from the model. Finally, let's zoom in to the different types of algorithms that we can expect to use throughout this book.
Understanding algorithms
When you have decided you want to apply AI to your data, we now know that we need to have data and an algorithm to create a model. We will discuss the requirements of the data in later chapters in much more detail. That leaves us with understanding how to use algorithms. Understanding how to work with algorithms is considered to be the data scientist's expertise as it lies at the cross-section of mathematics and statistics. However, even if we do not build models ourselves, or aspire to becoming full-on data scientists, it is still beneficial to understand the main types of algorithms we can work with.
The most important thing we need to know is that by choosing the right algorithm, we dictate how we want to look at the data and what kind of pattern should be detected by the model. If we talk about supervised learning – where we know the label we want to predict – we often talk about regression or classification. With regression, we try to predict a numeric value, whereas with classification the label is categorical (two or more categories).
Understanding regression algorithms
Imagine you work for a company that supplies electricity to households all across the country. You will have collected a lot of data on your customers, such as where they live, what type of house they live in, the number of people who make up that household, and the size of the house. For existing customers, you know how much energy they have consumed in previous years. For new customers, you want to predict what their energy consumption will be so that you can make a good estimation on what the costs will be for them.
Our data may look something like the table shown in Figure 1.3, where we have historical data for two existing customers, and we want to predict the energy consumption in kWh for the third, new customer:
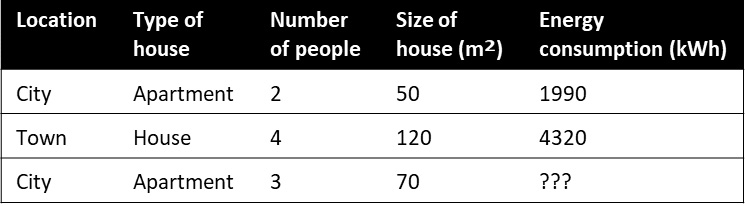
Figure 1.3 – Data for three customers on household characteristics as well as energy consumption
In this example, we know the label: energy consumption. So, we know that we are doing supervised learning. The variable we want to predict has a numerical value (for example 1990 kWh, 4320 kWh, or anything in between). Therefore, this is a simple example of a regression model. There are different algorithms we could choose within the subset of regression to train such a model. The choice may depend on things such as how complicated you want to allow your model to be, how explainable you want your model to be, and how much compute and time you want to spend on training your model. Some examples of such algorithms are linear regression, decision forest regression, and boosted decision tree regression.
Understanding classification algorithms
After we trained our model with one of these algorithms and our historical data, we were able to correctly predict for our new customer what the energy consumption will be and how much they will be spending per month. Our new customer has agreed to buy electricity from us but wants to know more about potential ways to save energy. This brings us to the idea of working more proactively with solar panels. If people have solar panels on their roofs, they can generate electricity themselves on sunny days and save money. We, of course, want to help them with this investment and the installation of solar panels.
Some customers may already have solar panels, some may approach us to talk about solar panels, and some may have never given it a thought. We want to reach out to customers and advertise the solar panels that we sell, but we do not want to annoy or spend marketing budget on customers who already have them.
So, what we want to do now is make an inventory of which of our customers already has solar panels. Sure, we could check with each and every household to see whether they have solar panels, but that seems like a big task that takes too much time and energy. And not every household may react to the survey we would send out to collect that data. We therefore decide we are going to see whether we can predict it. We can collect some sample data, train a model that can predict whether that customer has solar panels, and use those insights to target the right households.
This sample data may look like the data shown in Figure 1.4. We again have historical or known data, and we have a label. Since we know the label for our sample data, we are doing supervised learning. In this case, however, we are not trying to predict a numeric value. The label we try to predict is solar panels, and can either be yes or no. So, we have two categories, making it a classification problem; more specifically, a binary or two-class classification problem:
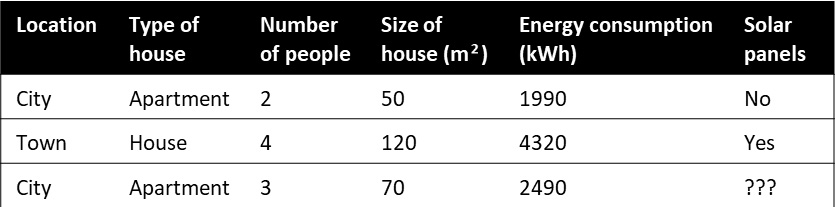
Figure 1.4 – Household characteristics and the solar panels label
Again, there are different algorithms we could choose from when we know we want to do classification. First of all, it matters whether we have two or three or more classes for our label. Next, we again can choose how complex or explainable we want our model to be with options such as a two-class logistic regression or decision forest algorithm to train our model with.
Finally, let's take look at one more simple example so that we have seen different types of algorithms we can work with. Imagine we are still supplying electricity to people all across the country, but now a new competitor has entered the market. We are afraid this new business will take away some of our customers, so we want to offer people nice benefits to convince them to stay with us. We do not want to offer this to all our customers, to save money, meaning we need to make a good assessment on who will leave us.
We have not had many customers leaving us yet, and we want to prevent this from happening. This does mean, however, that we do not have a label; we do not have enough data on the variable we want to predict. In this case, we might want to cluster our customers, and divide them into different groups: those who will leave us for the competitor, and those who will not. We may have some customers that have left us. Based on the little data we have, we can use an algorithm such as K-means clustering to find similar data points to the customers who left us to create these groups and target those that are on the verge of leaving us with attractive deals to make sure they stay with us.
Working with algorithms requires an understanding of the mathematics and statistics behind them. To use them to train models, we rely on data scientists bringing that knowledge to our team so that we can make more data-driven decisions. To work with the AI features in Power BI, we are not expected to become data science experts. It does, however, help to understand the choices being made to realize what the potential and restrictions are of using AI on our data.
Now that we know what AI is and how we can use different algorithms to train our model, let's take a step back and have a look at the complete data science process. How do we take data from beginning to end? And how we can we do so successfully?
What is the data science process?
Just like every project, training a model consists of multiple phases. And just like many projects, these phases are not necessarily linear. Instead, we want to take an iterative approach when developing an AI solution. First, let´s have a look at what the phases of the data science process look like.
The very first thing we need to think about is what we are doing this for. Why do we want to use AI? What is the model going to do? Even though it is good to drive innovation, we want to avoid using AI just because everyone else is doing it. Nevertheless, identifying an appropriate use case for AI can be challenging as many applications are relatively new and unknown. So, what is then a good use case? Of course, it depends on the area of business, but in each area, there is some low-hanging fruit that we can identify. Most commonly, we can think of using AI to predict how to invest marketing budgets, how to increase sales, how to monitor for predictive maintenance, or how to find outliers and anomalies in your data such as risk assessments.
After deciding on the use case, and essentially the scope, it becomes easier to think about what data to use and what metrics to evaluate the model on to know whether it will be successful or not. The next step is then to actually get the data. From a technical perspective, this could mean collecting data, building a new data orchestration pipeline to continuously extract data from a source such as a website or CRM system, or simply getting access to a database that already exists within the organization. Some hurdles may arise here. To train a good model, we need good data. And our data may not meet the requirements of having the right quantity or quality. There may also be Personally Identifiable Information (PII) data that needs to be masked or excluded first before we are allowed to work with that data.
Assuming that data is acquired by the data scientist, they can finally use their expertise to build the model. To build a model, we need data and an algorithm. The data we have received may need some processing. We may want to check for biases in the data, impute missing values, or transform data to make it more useful for our model. This phase is called pre-processing or feature engineering. The purpose is to end up with features that will serve as the input for our model.
Once we have a set of features, often in the form of variables structured as columns in a table, we can actually train the model. This means we try out algorithms and evaluate the models trained by looking at the resulting metrics provided by the different models. This phase by itself is very iterative and can require multiple models being trained (sometimes in parallel). After evaluating the model, based on the requirements from the use case, it can also lead to going back one or more phases to either redefine the use case, get different data, or alter the choices made in feature engineering.
Once it has been decided that a good enough model has been trained, the final phase can finally be executed. What exactly has to happen during this phase will depend on how the model's insights are being consumed. One example of how we can integrate the model is in a client application, where data is generated or collected in that application and is sent to the model to get real-time predictions back, which are also used in applications. Another common example is using a model for batch analysis of data. In this case, we can integrate the model into our data orchestration pipeline to make sure we use powerful compute to process a large amount of data. Whether it is real-time or batch predictions we want to generate, this is a final and crucial step we need to take into consideration when going through the data science process as shown in Figure 1.5:

Figure 1.5 – The five data science process phases
The data science process is not a linear process but understanding the five phases we most likely will iterate through can help us in knowing when to do what. A good project starts with a clearly defined use case, we then acquire data, prepare it through feature engineering, train a model with that data, and finally we integrate our model into our applications or Power BI reports.
Integrating AI with Power BI is of course especially interesting for the data analyst. In the next section, we will try to answer the question why this is a match made in heaven.