

Chapter 1: An Overview of the Machine Learning Life Cycle
Machine learning (ML) is a subfield of computer science that involves studying and exploring computer algorithms that can learn the structure of data using statistical analysis. The dataset that's used for learning is called training data. The output of training is called a model, which can then be used to run predictions against a new dataset that the model hasn't seen before. There are two broad categories of machine learning: supervised learning and unsupervised learning. In supervised learning, the training dataset is labeled (the dataset will have a target column). The algorithm intends to learn how to predict the target column based on other columns (features) in the dataset. Predicting house prices, stock market changes, and customer churn are some supervised learning examples. In unsupervised learning, on the other hand, the data is not labeled (the dataset will not have a target column). In this, the algorithm intends to recognize the common patterns in the dataset. One of the methods of generating labels for an unlabeled dataset is using unsupervised learning algorithms. Anomaly detection is one of the use cases for unsupervised learning.
The idea of the first mathematical model for machine learning was presented in 1943 by Walter Pitts and Warren McCulloch (The History of Machine Learning: How Did It All Start? – https://labelyourdata.com/articles/history-of-machine-learning-how-did-it-all-start). Later, in the 1950s, Arthur Samuel developed a program for playing championship-level computer checkers. Since then, we have come a long way in ML. I would highly recommend reading this article if you haven't.
Today, as we try to teach real-time decision-making to systems and devices, ML engineer and data scientist positions are the hottest jobs on the market. It is predicted that the global machine learning market will grow from $8.3 billion in 2019 to $117.9 billion by 2027. As shown in the following diagram, it's a unique skill set that overlaps with multiple domains:
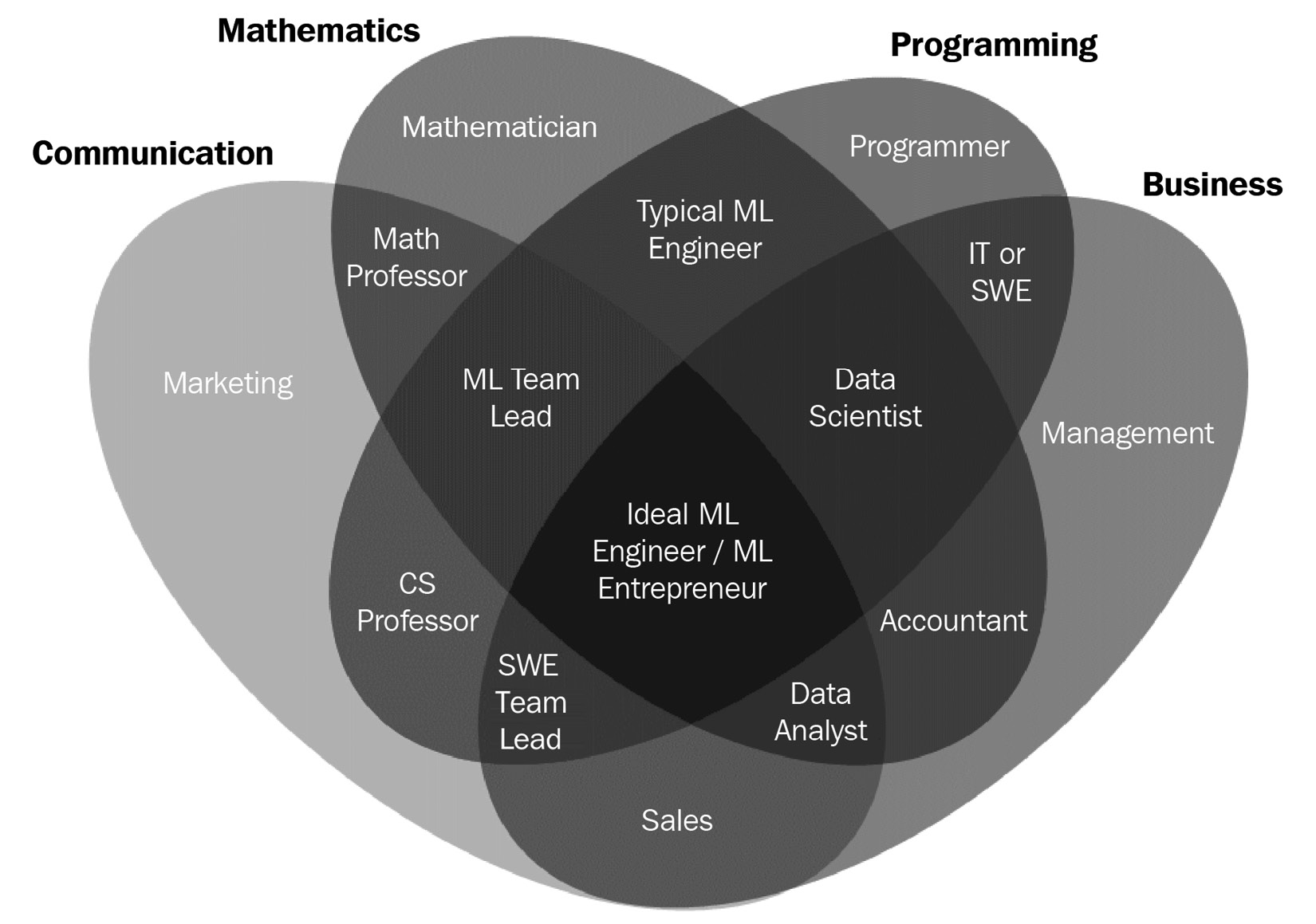
Figure 1.1 – ML/data science skill sets
In 2007 and 2008, the DevOps movement revolutionized the way software was developed and operationalized. It reduced the time to production for software:
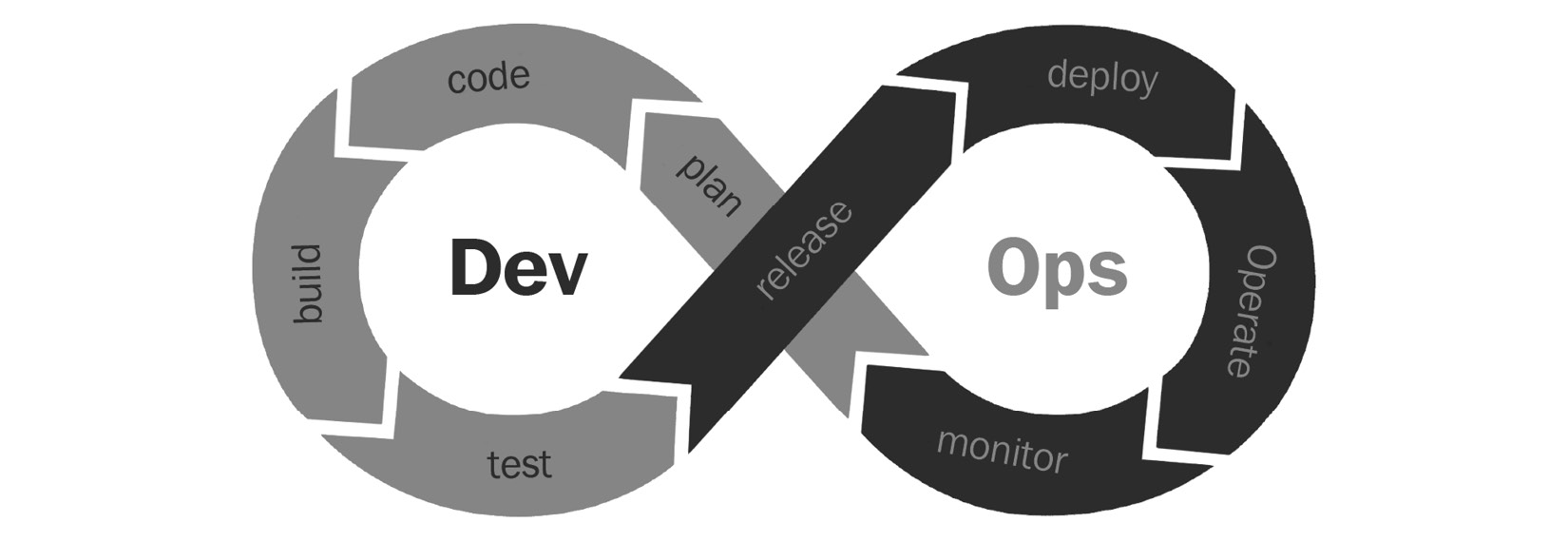
Figure 1.2 – DevOps
Similarly, to take a model from experimentation to operationalization, we need a set of standardized processes that makes this process seamless. Well, the answer to that is machine learning operations (MLOps). Many experts in the industry have come across a set of patterns that would reduce the time to production of ML models. 2021 is the year of MLOps – there are a lot of new start-ups that are trying to cater to the ML needs of the firms that are still behind in the ML journey. We can assume that this will expand over time and only get better, just like any other process. As we grow with it, there will be a lot of discoveries and ways of working, best practices, and more will evolve. In this book, we will talk about one of the common tools that's used to standardize ML and its best practices: the feature store.
Before we discuss what a feature store is and how to use it, we need to understand the ML life cycle and its common oversights. I want to dedicate this chapter to learning about the different stages of the ML life cycle. As part of this chapter, we will take up an ML model-building exercise. We won't dive deep into the ML model itself, such as its algorithms or how to do feature engineering; instead, we will focus on the stages an ML model would typically go through, as well as the difficulties involved in model building versus model operationalization. We will also discuss the stages that are time-consuming and repetitive. The goal of this chapter is to understand the overall ML life cycle and the issues involved in operationalizing models. This will set the stage for later chapters, where we will discuss feature management, the role of a feature store in ML, and how the feature store solves some of the issues we will discuss in this chapter.
In this chapter, we will cover the following topics:
- The ML life cycle in practice
- An ideal world versus the real world
- The most time-consuming stages of ML
Without further ado, let's get our hands dirty with an ML model.