

Understanding DL explainability challenges
In this section, we will discuss DL explainability challenges at each of the stages described in Figure 1.3. It is increasingly important to view explainability as an integral and necessary mechanism to define, test, debug, validate, and monitor models across the entire model life cycle. Embedding explainability early will make subsequent model validation and operations easier. Also, to maintain ongoing trust in ML/DL models, it is critical to be able to explain and debug ML/DL models after they go live in production:
- Data collection/cleaning/annotation: As we have gathered, explainability is critical for model prediction. The root cause of any model's trustworthiness or bias can be traced back to the data used to train the model. Explainability for the data is still an emerging area but is critical. So, what could go wrong and become a challenge during the data collection/cleaning/annotation stage? For example, let's suppose we have an ML/DL model, and its prediction outcome is about whether a loan applicant will pay back a loan or not. If the data collected has certain correlations between age and the loan payback outcome, this will cause the model to use age as a predictor. However, a loan decision based on a person's age is against the law and not allowed even if the model works well. So, during data collection, it could be that the sampling strategy is not sufficient to represent certain subpopulations such as different loan applicants in different age groups.
A subpopulation could have lots of missing fields and then be dropped during data cleaning. This could result in underrepresentation following the data cleaning process. Human annotations could favor the privileged group and other possible unconscious biases. A metric called Disparate Impact could reveal the hidden biases in the data, which compares the proportion of individuals that receive a positive outcome for two groups: an unprivileged group and a privileged group. If the unprivileged group (for example, persons with age > 60) receives a positive outcome (for example, loan approval) less than 80% of the proportion of the privileged group (persons with age < 60), this is a disparate impact violation based on the current common industry standard (a four-fifths rule). Tools such as Dataiku could help to automate the disparate impact and subpopulation analysis to find groups of people who may be treated unfairly or differently because of the data used for model training.
- Model development: Model explainability during offline experimentation is very important to not only help understand why a model behaves a certain way but also help with model selection to decide which model to use if we need to put it into production. Accuracy might not be the only criteria to select a winning model. There are a few DL explainability tools, such as SHAP (please refer to Figure 1.5). MLflow integration with SHAP provides a way to implement DL explainability:
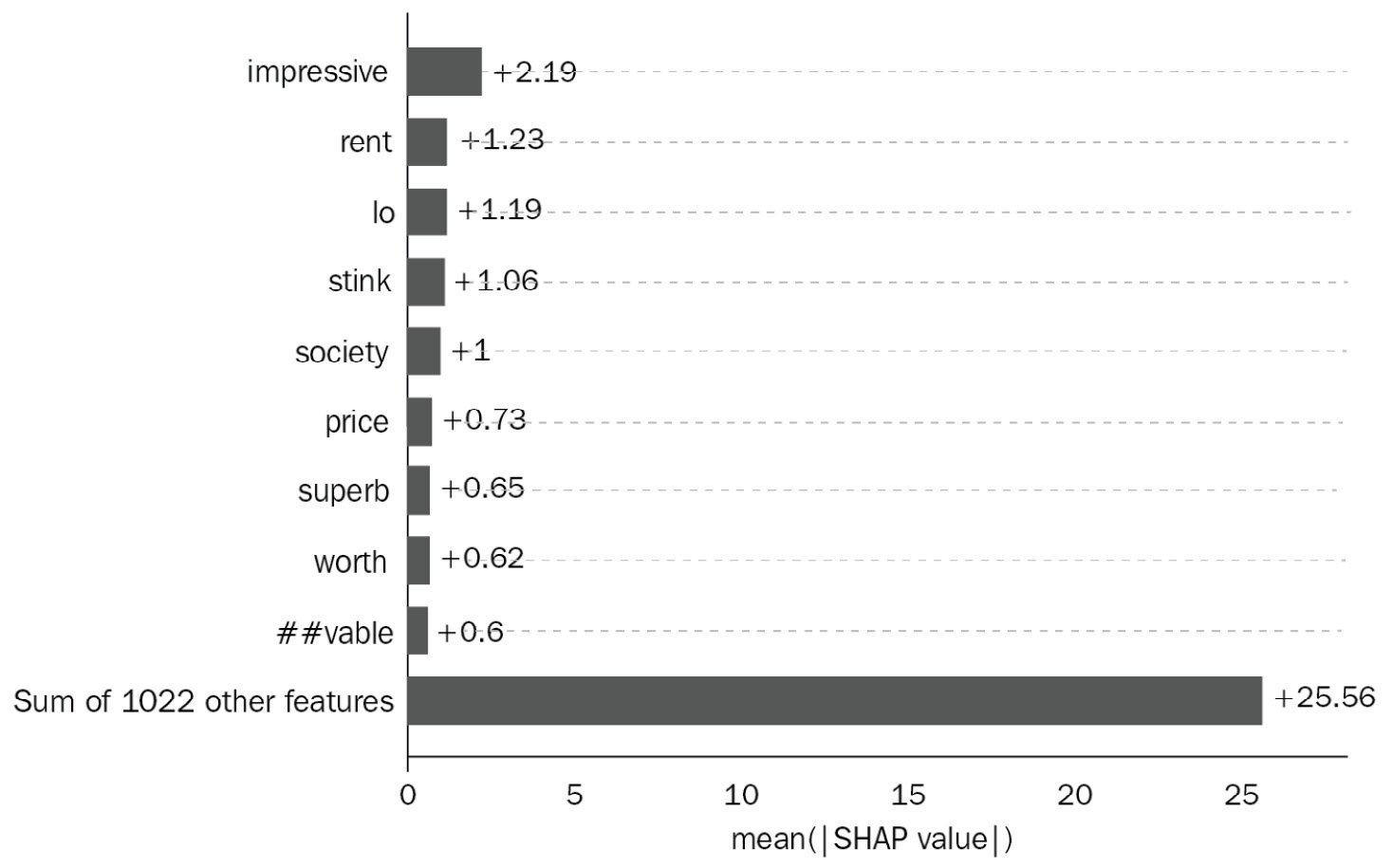
Figure 1.5 – NLP text SHAP Variable Importance Plot when using a DL model
Figure 1.5 shows that this NLP model's prediction results' number one feature is the word impressive, followed by rent. Essentially, this breaks the black box of the DL model, giving much confidence to the usage of DL models in production.
- Model deployment and serving in production: During the production stage, if the explainability of the model prediction can be readily provided to users, then not only will the usability (user-friendliness) of the model be improved, but also, we can collect better feedback data as users are more incentivized to give more meaningful feedback. A good explainability solution should provide point-level decisions for any prediction outcome. This means that we should be able to answer why a particular person's loan is rejected and how this rejection compares to other people in a similar or different age group. So, the challenge is to have explainability as one of the gated deployment criteria for releasing a new version of the model. However, unlike accuracy metrics, it is very difficult to measure explainability as scores or thresholds, although certain case-based reasoning could be applied and automated. For example, if we have certain hold-out test cases where we expect the same or similar explanations regardless of the versions of the model, then we could use that as a gated release criterion.
- Model validation and A/B testing: During online experimentation and ongoing production model validation, we would need explainability to understand whether the model has been applied to the right data or whether the prediction is trustworthy. Usually, ML/DL models encode complex and non-linear relationships. During this stage, it is often desirable to understand how the model influences the metrics of user behavior (for example, a higher conversion rate on a shopping website). Influence sensitivity analysis could provide insights regarding whether a certain user feature such as a user's income has a positive or negative impact on the outcome. If during this stage, we found, for some reason, that higher incomes cause a negative loan approval rate or a lower conversion rate, then this should be automatically flagged. However, automated sensitivity analysis during model validation and A/B testing is still not widely available and remains a challenging problem. A few vendors such as TruEra provide potential solutions to this space.
- Monitoring and feedback loops: While model performance metrics and data characteristics are of importance here, explainability can provide an incentive for users to provide valuable feedback and user behavior metrics to identify drivers and causes of model degradation if there are any. As we know, ML/DL models are prone to overfitting and cannot generalize well beyond their training data. One important explainability solution during model production monitoring is to measure how feature importance shifts across different data splits (for example, pre-COVID versus post-COVID). This can help data scientists to identify where degradation in model performance is due to changing data (such as a statistical distribution shift) or changing relationships between variables (such as a concept shift). A recent example provided by TruEra (https://truera.com/machine-learning-explainability-is-just-the-beginning/) illustrates that a loan model changes its prediction behavior due to changes in people's annual income and loan purposes before and after the COVID periods. This explainability of Feature Importance Shift greatly helps to identify the root causes of changes in model behavior during the model production monitoring stage.
In summary, DL explainability is a major challenge where ongoing research is still needed. However, MLflow's integration with SHAP now provides a ready-to-use tool for practical DL applications, which we will cover in our advanced chapter later in this book.