-
Book Overview & Buying

-
Table Of Contents

Transformers for Natural Language Processing - Second Edition
By :
Transformers for Natural Language Processing
By:
Overview of this book
Transformers are...well...transforming the world of AI. There are many platforms and models out there, but which ones best suit your needs?
Transformers for Natural Language Processing, 2nd Edition, guides you through the world of transformers, highlighting the strengths of different models and platforms, while teaching you the problem-solving skills you need to tackle model weaknesses.
You'll use Hugging Face to pretrain a RoBERTa model from scratch, from building the dataset to defining the data collator to training the model.
If you're looking to fine-tune a pretrained model, including GPT-3, then Transformers for Natural Language Processing, 2nd Edition, shows you how with step-by-step guides.
The book investigates machine translations, speech-to-text, text-to-speech, question-answering, and many more NLP tasks. It provides techniques to solve hard language problems and may even help with fake news anxiety (read chapter 13 for more details).
You'll see how cutting-edge platforms, such as OpenAI, have taken transformers beyond language into computer vision tasks and code creation using DALL-E 2, ChatGPT, and GPT-4.
By the end of this book, you'll know how transformers work and how to implement them and resolve issues like an AI detective.
Table of Contents (25 chapters)
Preface

 Free Chapter
Free Chapter
What are Transformers?
Getting Started with the Architecture of the Transformer Model
Fine-Tuning BERT Models
Pretraining a RoBERTa Model from Scratch
Downstream NLP Tasks with Transformers
Machine Translation with the Transformer
The Rise of Suprahuman Transformers with GPT-3 Engines
Applying Transformers to Legal and Financial Documents for AI Text Summarization
Matching Tokenizers and Datasets
Semantic Role Labeling with BERT-Based Transformers
Let Your Data Do the Talking: Story, Questions, and Answers
Detecting Customer Emotions to Make Predictions
Analyzing Fake News with Transformers
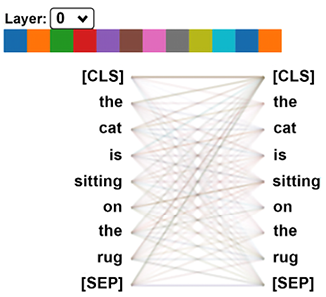
Interpreting Black Box Transformer Models
From NLP to Task-Agnostic Transformer Models
The Emergence of Transformer-Driven Copilots
The Consolidation of Suprahuman Transformers with OpenAI’s ChatGPT and GPT-4
Other Books You May Enjoy
Index
Appendix I — Terminology of Transformer Models
Appendix II — Hardware Constraints for Transformer Models
Appendix III — Generic Text Completion with GPT-2
Appendix IV — Custom Text Completion with GPT-2
Appendix V — Answers to the Questions