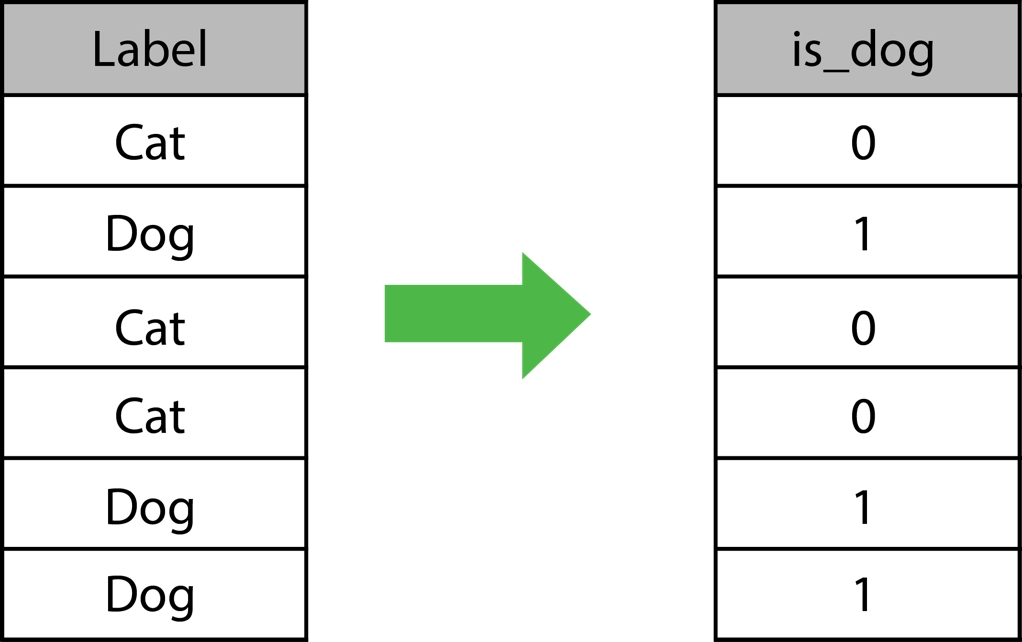
To fit models to the data, it must be represented in numerical format since the mathematics used to in all machine learning algorithms only work on matrices of numbers (you cannot perform linear algebra on an image). This will be one goal of this topic, to learn how to encode all features into numerical representations. For example, in binary text, values that contain one of two possible values may be represented as zeros or ones. An example is shown in the following figure. Since there are only two possible values, a value 0 is assumed to be a cat and the value 1 a dog We can also rename the column for interpretation..
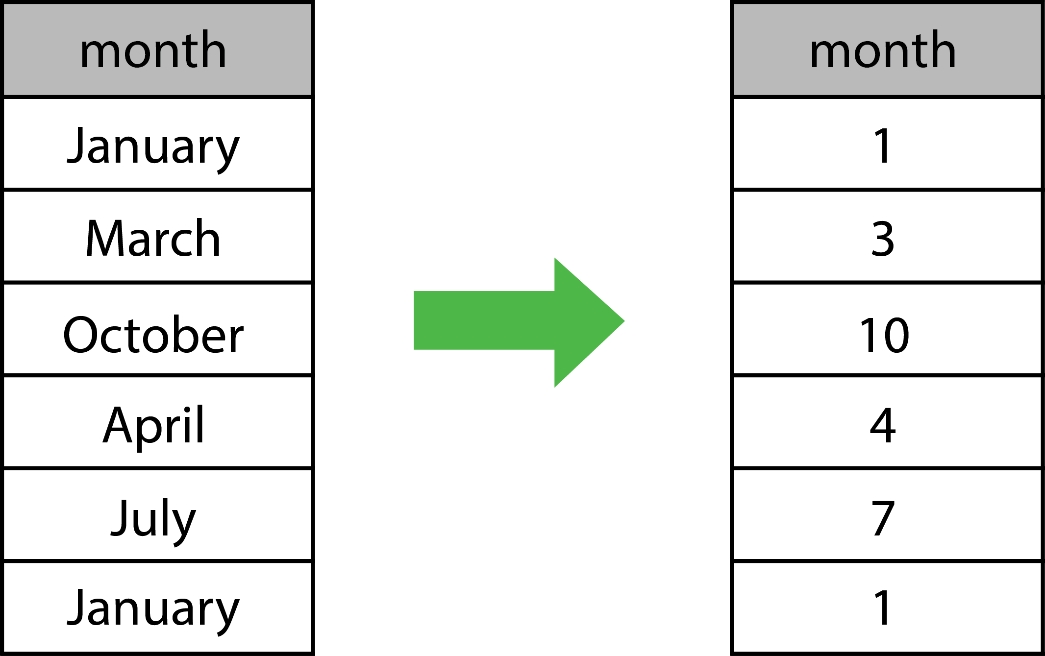
Another goal will be to appropriately represent the data in numerical format — by appropriately, we mean that we want to encode relevant information numerically through the distribution of numbers. For example, one method to encode the months of the year would be to use the number of the month in the year. For example, January would be encoded as 1, since it is the first month, and December would be 12. Here's an example of how this would look in practice:
Not encoding information appropriately into numerical features can lead to machine learning models learning unintuitive representations, and relationships between the feature data and target variables that will prove useless for human interpretation.
An understanding of the machine learning algorithms you are looking to use will also help encode features into numerical representations appropriately. For example, algorithms for classification tasks such as Artificial Neural Networks (ANNs) and logistic regression are susceptible to large variations in the scale between the features that may hamper model-fitting ability. Take, for example, a regression problem attempting to fit house attributes, such as area in square feet and the number of bedrooms, to the house price. The bounds of the area may be anywhere from 0 to 5,000, whereas the number of bedrooms may only vary from 0 to 6, so there is a large difference between the scale of the variables. An effective way to combat the large variation in scale between the features is to normalize the data. Normalizing the data will scale the data appropriately so that it is all of a similar magnitude, so that any model coefficients or weights can be compared correctly. Algorithms such as decision trees are unaffected by data scaling, so this step can be omitted for models using tree-based algorithms.
In this topic, we demonstrate a number of different ways to encode information numerically. There is a myriad of alternative techniques that can be explored elsewhere. Here, we will show some simple and popular methods to tackle common data formats.
Exercise 2: Cleaning the Data
It is important that we clean the data appropriately so that it can be used for training models. This often includes converting non-numerical datatypes into numerical datatypes. This will be the focus of this exercise – to convert all columns in the feature dataset into numerical columns. To complete the exercise, perform the following steps:
First, we load the feature dataset into memory:
Note
When pandas saves a DataFrame, it also includes the index column by default as the first column. So, when loading the data, we have to indicate which column number is the index column; otherwise, we will gain an extra column in our DataFrame.
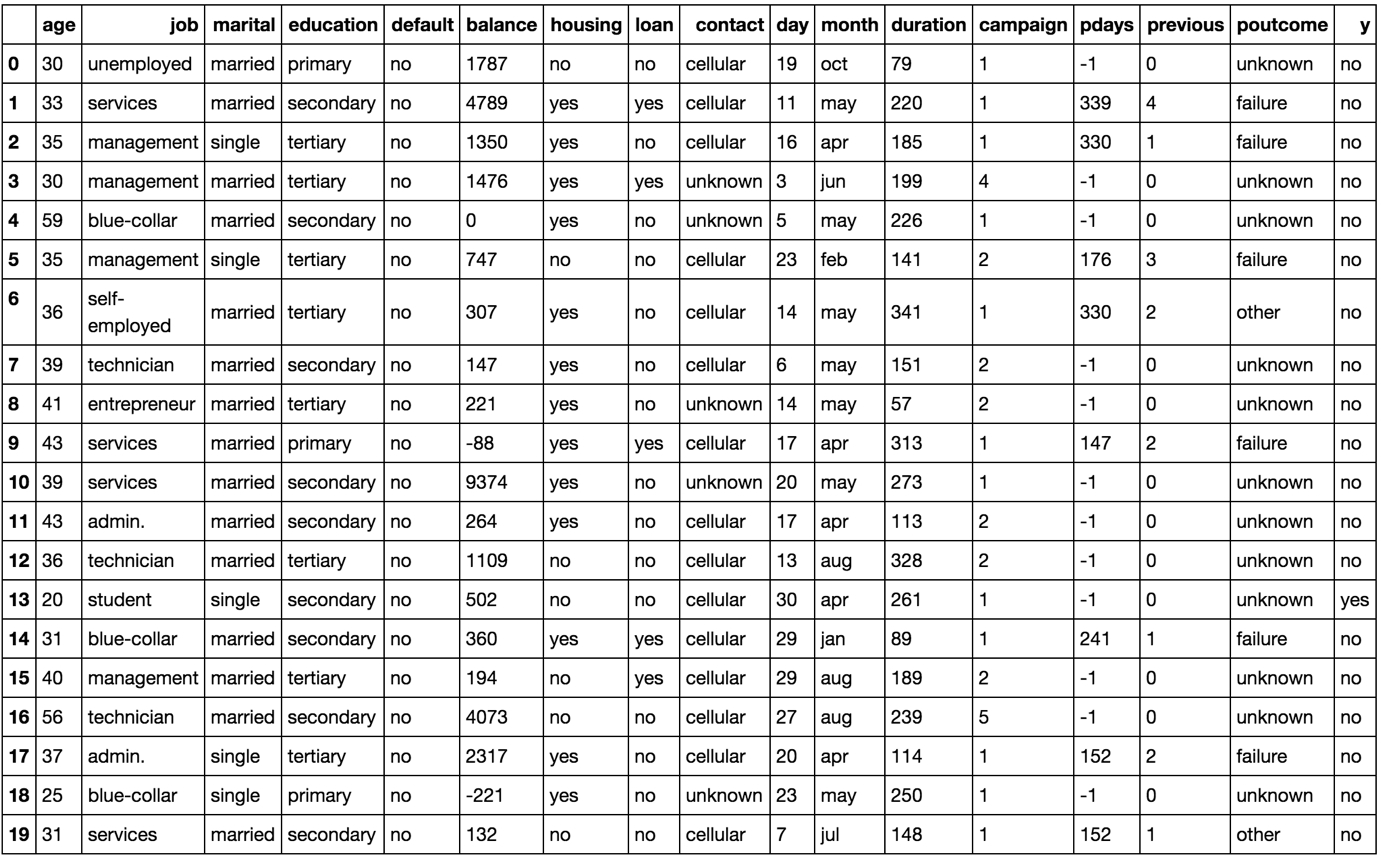
Again, we can look at the first 20 rows to check out the data:
We can see that there are a number of columns that need to be converted to numerical format. The numerical columns we may not need to touch the columns named age, balance, day, duration, campaign, pdays, and previous.
There are some binary columns, which have either one of two possible values. They are default, housing, and loan.
Finally, there are also categorical columns that are string types, but there are a limited number of choices (>2) that the column can take. They are job, education, marital, contact, month, and poutcome.
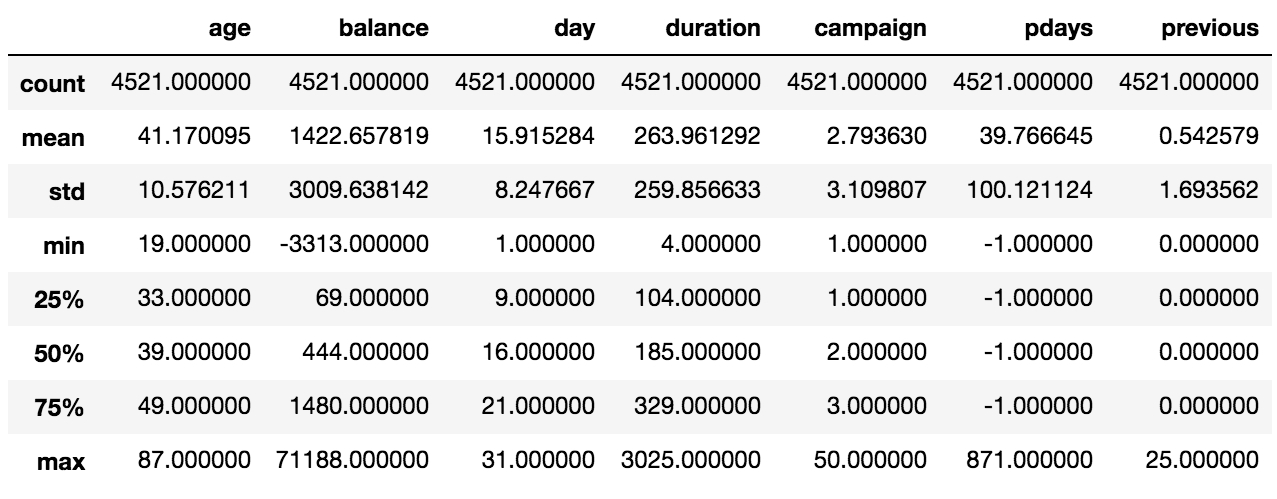
For the numerical columns, we can use the describe function, which can give us a quick indication of the bounds of the numerical columns:
We will convert the binary columns into numerical columns. For each column, we will follow the same procedure, examine the possible values, and convert one of the values to 1 and the other to 0. If appropriate, we will rename the column for interpretability.
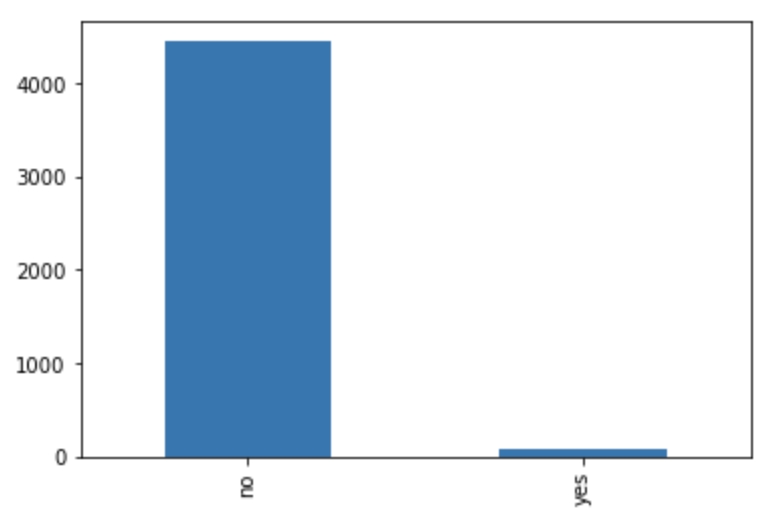
For context, it is helpful to see the distribution of each value. We can do that using the value_counts function. We can try this out on the default column:
We can also look at these values as a bar graph by plotting the value counts:
Note
The kind='bar' argument will plot the data as a bar graph. The default is a line graph. When plotting in the Jupyter Notebook, in order to make the plots within the notebook, the following command may need to be run: %matplotlib inline.
We can see that this distribution is very skewed. Let's convert the column to numerical value by converting the yes values to 1, and the no values to 0. We can also change the name of the column from default to is_default. This makes it a bit more obvious what the column means:
Note
The apply function iterates through each element in the column and applies the function provided as the argument. A function has to be supplied as the argument. Here, a lambda function is supplied.
We can take a look at the original and converted columns side by side. We can take a sample of the last few rows to show examples of both values manipulated to numerical data types:
Note
The tail function is identical to the head function, except the function returns the bottom n values of the DataFrame instead of the top n.
We can see that yes is converted to 1 and no is converted to 0.
Let's do the same for the other binary columns, housing and loan:
Next, we have to deal with categorical columns. We will approach the conversion of categorical columns to numerical values slightly differently, than with binary text columns but the concept will be the same. We will convert each categorical column into a set of dummy columns. With dummy columns, each categorical column will be converted to n columns, where n is the number unique values in the category. The columns will be zero or one depending on the value of categorical column.
This is achieved with the get_dummies function. If we need any help understanding the function, we can use the help function, or any function:
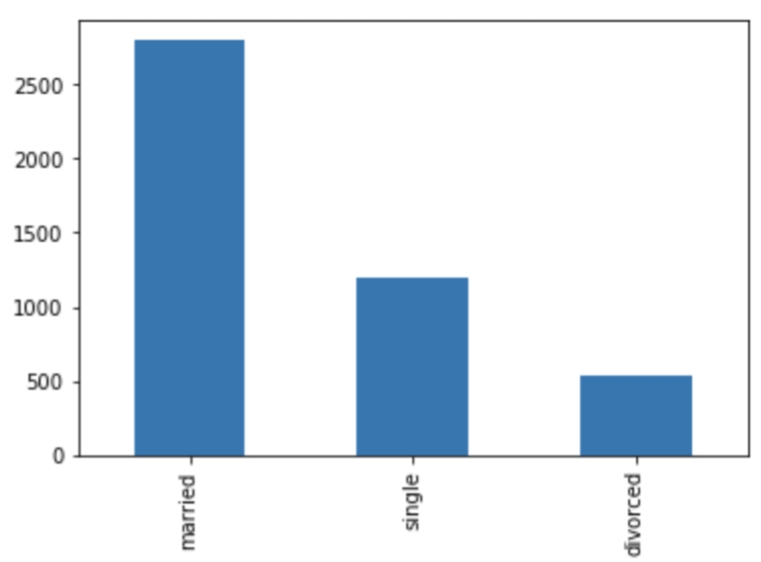
Let's demonstrate how to manipulate categorical columns with the marital column. Again, it is helpful to see the distribution of values, so let's look at the value counts and plot them:
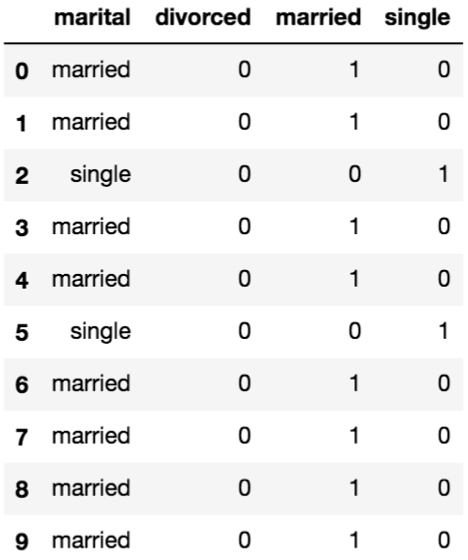
We can call the get_dummies function on the marital column and take a look at the first few rows alongside the original:
We can see that in each of the rows there can be one value of 1, which is in the column corresponding the value in the marital column.
In fact, when using dummy columns there is some redundant information. Because we know there are three values, if two of the values in the dummy columns are zero for a particular row, then the remaining column must be equal to one. It is important to eliminate any redundancy and correlations in features as it becomes difficult to determine which feature is most important in minimizing the total error.
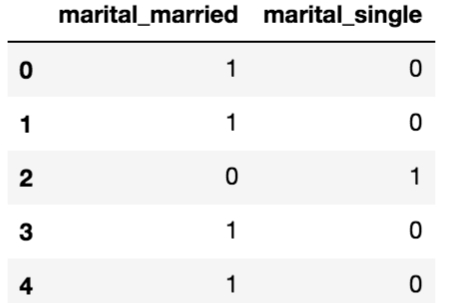
To remove the inter-dependency, let's drop the divorced column because it occurs with the lowest frequency. We can also change the name of the columns so that it is a little easier to read and include the original column:
Note
In the drop function, the inplace argument will apply the function in place, so a new variable does not have to declared.
Looking at the first few rows, we can see what remains of our dummy columns for the original marital column.
Finally, we can add these dummy columns to the original feature data by concatenating the two DataFrames column-wise and dropping the original column:
We will repeat the exact same steps with the remaining categorical columns: education, job, contact, and poutcome. First, we will examine the distribution of column values, which is an optional step. Second, we will create dummy columns. Third, we will drop one of the columns to remove redundancy. Fourth, we will change the column names for interpretability. Fifth, we will concatenate the dummy columns into a feature dataset. Sixth, we will drop the original column if it remains in the dataset.
We could treat the month column like a categorical variable, although since there is some order to the values (January comes before February, and so on) they are known as ordinal values. We can encode this into the feature by converting the month name into the month number, for example, January becomes 1 as it is the first month in the year.
This is one way to convert months into numerical features that may make sense in certain models. In fact, for a logistic regression model, this may not make sense since we are encoding some inherent weighting into the features. This feature will contribute 12 times as much for rows with December as the month compared to January, which there should be no reason to do. Regardless, in the spirit of showing multiple techniques to convert columns to numerical datatypes, we will continue.
We can achieve this result by mapping the month names to month numbers by creating a Python dictionary of key-value pairs in which the keys will be the month names and the values will be the month numbers:
Then we can convert the column by utilizing the map function:
Since we have kept the column name the same, there is no need for us to concatenate back into the original feature dataset and drop the column.
Now we should have our entire dataset as numerical columns. Let's check the types of each column to verify:
Now that we have verified the datatypes, we have a dataset we can use to train a model, so let's save this for later:
Let's do the same for the target variable. First, load the data in, then convert the column to numerical datatype, and lastly, save the column as CSV:
We can see that this is a string datatype, and there are two unique values.
Let's convert this into a binary numerical column, much like we did the binary columns in the feature dataset:
Finally, we save the target dataset to CSV:
In this exercise, we learned how to clean the data appropriately so that it can be used to train models. We converted the non-numerical datatypes into numerical datatypes. That is, we converted all the columns in the feature dataset into numerical columns. Lastly, we saved the target dataset to a CSV file so that we can use them in the succeeding exercises or activities.
Appropriate Representation of the Data
In our bank marketing dataset, we have some columns that do not appropriately represent the data, which will have to be addressed if we want the models we build to learn useful relationships between the features and the target. One column that is an example of this is the pdays column. In the documentation, the column is described as follows:
pdays: number of days that passed by after the client was last contacted from a previous campaign (numeric, -1 means client was not previously contacted)
Here we can see that a value of -1 means something quite different than a positive number. There are two pieces of information encoded in this one column that we may want to separate. They are as follows:
When we create columns, they should ideally align with hypotheses we create of relationships between the features and the target.
One hypothesis may be that previously contacted customers are more likely to subscribe to the product. Given our column, we could test this hypothesis by converting the pdays column into a binary variable indicating whether they were previously contacted or not. This can be achieved by observing whether the value of pdays is -1. If so, we will associate that with a value of 0; otherwise, they have been contacted, so the value will be 1.
A second hypothesis is that the more recently the customer was contacted, the greater the likelihood that they will subscribe. There are many ways to encode this second hypothesis. I recommend encoding the first one, and if we see that this feature has predictive power, we can implement the second hypothesis.
Since building machine learning models is an iterative process, we can choose either or both hypotheses and evaluate whether their inclusion has increased the model's predictive performance.
Exercise 3: Appropriate Representation of the Data
In this exercise, we will encode the hypothesis that a customer will be more likely to subscribe to the product that they were previously targeted with. We will encode this hypothesis by transforming the pdays column. Wherever the value is -1, we will transform it to 0, indicating the customer has never been previously contacted. Otherwise, the value will be 1. To do so, we follow the following steps:
Open a Jupyter notebook.
Load the dataset into memory. We can use the same feature dataset as was the output from Exercise 2:
Use the apply function to manipulate the column and create a new column:
Drop the original column:
Let's look at the column that was just changed:
Finally, let's save the dataset to a CSV file for later use:
Great! Now we can test our hypothesis of whether previous contact will affect the target variable. This exercise has demonstrated how to appropriately represent data for use in machine learning algorithms. We have presented some techniques to convert data into numerical datatypes that cover many situations that may be encountered when working with tabular data.
Life Cycle of Model Creation
In this section, we will cover the life cycle of creating performant machine learning models from engineering features, to fitting models to training data, and evaluating our models using various metrics. Many of the steps to create models are highly transferable between all machine learning libraries – we'll start with scikit-learn, which has the advantage of being widely used, and as such there is a lot of documentation, tutorials, and learning to be found across the internet.






 Free Chapter
Free Chapter