

Interacting with the Azure Databricks workspace
The Azure Databricks workspace is where you can manage objects such as notebooks, libraries, and experiments. It is organized into folders and it also provides access to data, clusters, and jobs:
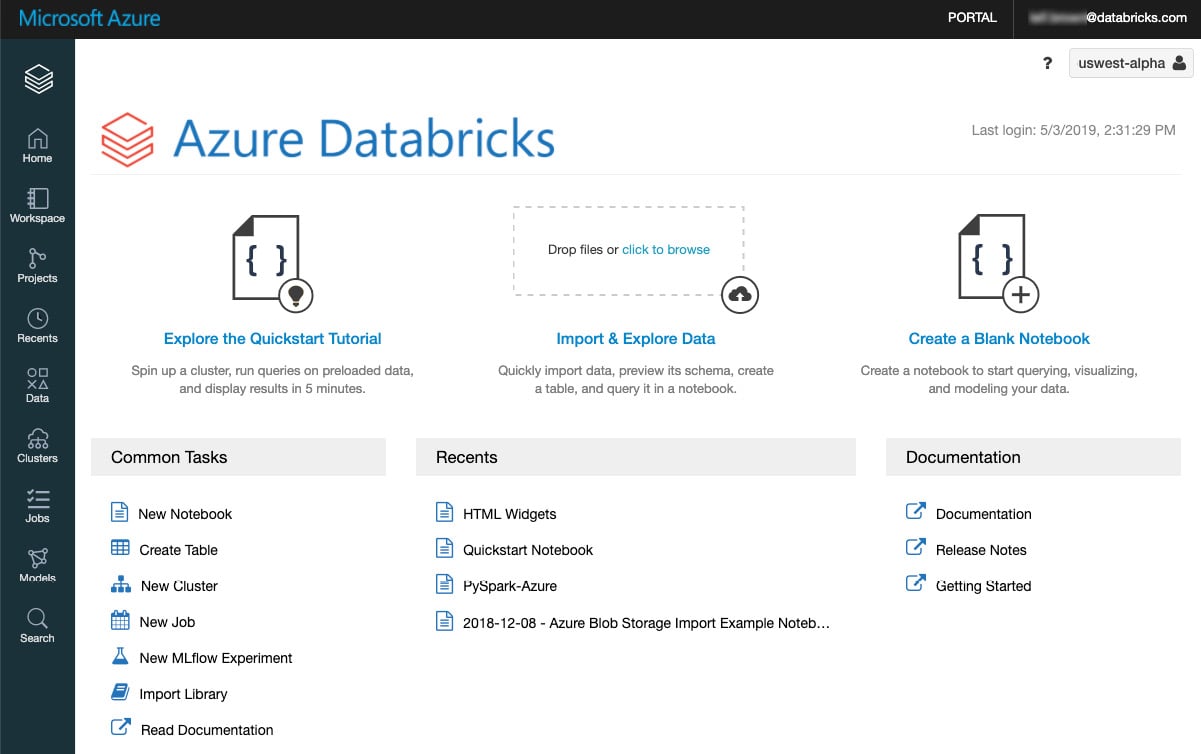
Figure 1.4 – Databricks workspace. Source: https://docs.microsoft.com/en-us/azure/databricks/workspace/
Access and control of a workspace and its assets can be made through the UI, CLI, or API. We will focus on using the UI.
Workspace assets
In the Azure Databricks workspace, you can manage different assets, most of which we have discussed in the terminology. These assets are as follows:
In the following sections, we will dive deeper into how to work with folders and other workspaces objects. The management of these objects is central to running our tasks in Azure Databricks.
Folders
All of our static assets within a workspace are stored in folders within the workspace. The stored assets can be notebooks, libraries, experiments, and other folders. Different icons are used to represent folders, notebooks, directories, or experiments. Click a directory to deploy the drop-down list of items:
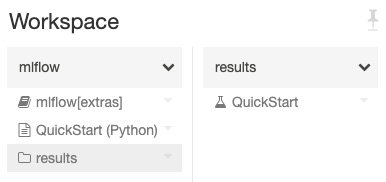
Figure 1.5 – Workspace folders
Clicking on the drop-down arrow in the top-right corner will unfold the menu item, allowing the user to perform actions with that specific folder:
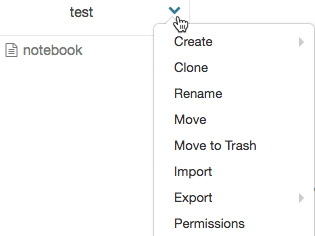
Figure 1.6 – Workspace folders drop-down menu
Special folders
The Azure Databricks workspace has three special folders that you cannot rename or move to a special folder. These special folders are as follows:
- Workspace
- Shared
- Users
Workspace root folder
The Workspace root folder is a folder that contains all of your static assets. To navigate to this folder, click the workspace or home icon and then click the go back icon:
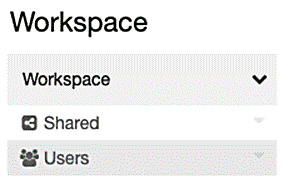
Figure 1.7 – Workspace root folder
Within the Workspace root folder, you either select Shared or Users. The former is for sharing objects with other users that belong to your organization, and the latter contains a folder for a specific user.
By default, the Workspace root folder and all of its contents are available for all users, but you can control and manage access by enabling workspace access control and setting permissions.
User home folders
Within your organization, every user has their own directory, which will be their root directory:
Figure 1.8 – Workspace Users folder
Objects in a user folder will be private to a specific user if workspace access control is enabled. If a user's permissions are removed, they will still be able to access their home folder.
Workspace object operations
To perform an action on a workspace object, right-click the object or click the drop-down icon at the right side of an object to deploy the drop-down menu:
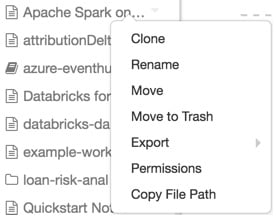
Figure 1.9 – Operations on objects in the workspace
If the object is a folder, from this menu, the user can do the following:
- Create a notebook, library, MLflow experiment, or folder.
- Import a Databricks archive.
If it is an object, the user can choose to do the following:
- Clone the object.
- Rename the object.
- Move the object to another folder.
- Move the object to Trash.
- Export a folder or notebook as a Databricks archive.
- If the object is a notebook, copy the notebook's file path.
- If you have Workspace access control enabled, set permissions on the object.
When the user deletes an object, this object goes to the Trash folder, in which everything is deleted after 30 days. Objects can be restored from the Trash folder or be eliminated permanently.
Now that you have learned how to interact with Azure Databricks assets, we can start working with Azure Databricks notebooks to manipulate data, create ETLs, ML experiments, and more.