

Perceptron
The "perceptron" is a simple algorithm that, given an input vector x of m values (x1, x2,..., xm), often called input features or simply features, outputs either a 1 ("yes") or a 0 ("no"). Mathematically, we define a function:
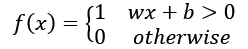
Where w is a vector of weights, wx is the dot product 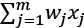 and b is bias. If you remember elementary geometry, wx + b defines a boundary hyperplane that changes position according to the values assigned to w and b.
and b is bias. If you remember elementary geometry, wx + b defines a boundary hyperplane that changes position according to the values assigned to w and b.
Note that a hyperplane is a subspace whose dimension is one less than that of its ambient space. See Figure 3 for an example:
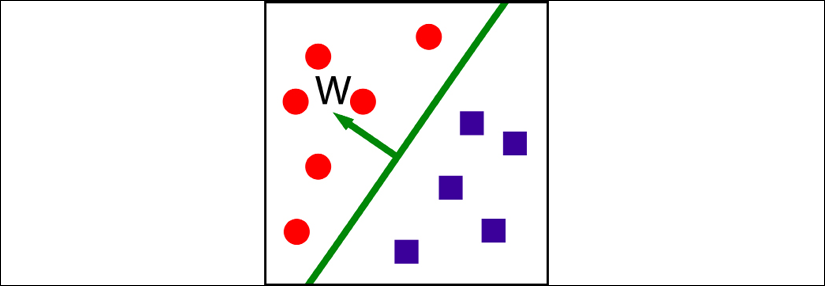
Figure 3: An example of a hyperplane
In other words, this is a very simple but effective algorithm! For example, given three input features, the amounts of red, green, and blue in a color, the perceptron could try to decide whether the color is white or not.
Note that the perceptron cannot express a "maybe" answer. It can answer "yes" (1) or "no" (0), if we understand how to define w and b. This is the "training" process that will be discussed in the following sections.
A first example of TensorFlow 2.0 code
There are three ways of creating a model in tf.keras: Sequential API , Functional API, and Model subclassing. In this chapter we will use the simplest one, Sequential(), while the other two are discussed in Chapter 2, TensorFlow 1.x and 2.x. A Sequential() model is a linear pipeline (a stack) of neural network layers. This code fragment defines a single layer with 10 artificial neurons that expects 784 input variables (also known as features). Note that the net is "dense," meaning that each neuron in a layer is connected to all neurons located in the previous layer, and to all the neurons in the following layer:
import tensorflow as tf
from tensorflow import keras
NB_CLASSES = 10
RESHAPED = 784
model = tf.keras.models.Sequential()
model.add(keras.layers.Dense(NB_CLASSES,
input_shape=(RESHAPED,), kernel_initializer='zeros',
name='dense_layer', activation='softmax'))
Each neuron can be initialized with specific weights via the kernel_initializer parameter. There are a few choices, the most common of which are listed as follows:
random_uniform: Weights are initialized to uniformly random small values in the range -0.05 to 0.05.random_normal: Weights are initialized according to a Gaussian distribution, with zero mean and a small standard deviation of 0.05. For those of you who are not familiar with Gaussian distribution, think about a symmetric "bell curve" shape.zero: All weights are initialized to zero.
A full list is available online at https://www.tensorflow.org/api_docs/python/tf/keras/initializers.