While deceptively simple, there's actually a lot of thought involved in correctly placing an odd node, and why we use witness nodes rather than yet another PostgreSQL replica:
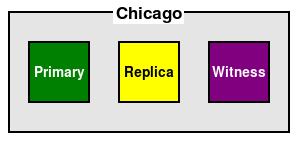
- Our first guideline is the most straightforward of these, such that we ensure there are an odd number of nodes in the cluster. Once we have that, any event in the cluster is submitted to the entire quorum for a decision, and only agreement guarantees subsequent action. Further, since the witness cannot vote for itself, only one eligible node will ever win the election. Consider this sample cluster diagram:
We have three nodes in this cluster and, in the event of a failure of the Primary node, the Witness must vote for the only remaining Replica. If the Witness had been a standard replica node, it could have voted for itself and potentially led to a tied vote. In an automated scenario, this would prevent the cluster from promoting a replacement Primary node.
- The second guideline is a variant of this concept. If we already had an odd number of nodes, one of these should be a Witness rather than a standard replica. Consider this diagram:
We can see here that the third node is still a replica, but it also acts as a Witness. Essentially, we don't allow this node to vote for itself to become the new Primary. This kind of role works well for read-only replicas that exist only for application use and is a good way to reuse existing resources.
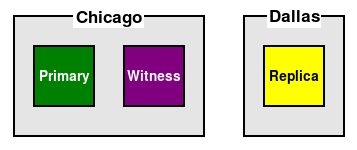
- The third guideline, of placing the Witness in the same location as the Primary node, safeguards node visibility. More important than automation is safety. By placing the Witness in the same location as the Primary when there are only two data centers, we can ensure that a network partition—a situation where we lose network connectivity between the data centers—won't result in the alternate location incorrectly promoting one of its replicas. Consider this diagram:
If the connection between Chicago and Dallas is lost, Chicago still has the majority of voting nodes, and Dallas does not. As a result, the cluster will continue operating normally until the network is repaired, and we didn't experience an accidental activation of a node in Dallas.
Some failover automation systems also take physical location into account by verifying that all nodes in one location agree that all nodes in the other location are not responding. In these cases, the only time where automation will not work normally is when a network partition has occurred. This approach is only viable when more than one node exists in each location. Such can be accomplished by allocating further replicas, or even witness nodes.
Unfortunately, our cluster is no longer symmetrical. If we activate the node in Dallas, there are no witnesses in that location, so we must eventually move the Primary back to Chicago. This means every failover will be followed by a manual switch to the other location, thus doubling our downtime.
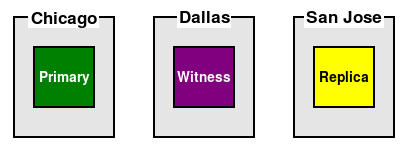
The easiest way to permanently address these concerns is to add a third location and assign a node there. In most cases, this will be the Witness node itself. Consider this example:
In this case, we may desire that only Chicago or San Jose host the active PostgreSQL node. In the event of a failure of our Primary node, San Jose should take over instead. The Witness can see both data centers and decide voting based on this. Furthermore, it doesn't matter if the Primary is active in Chicago or San Jose, because the Witness is not tied directly to either location.