

Traditionally, systems were made intelligent by using sophisticated algorithms written by programmers.
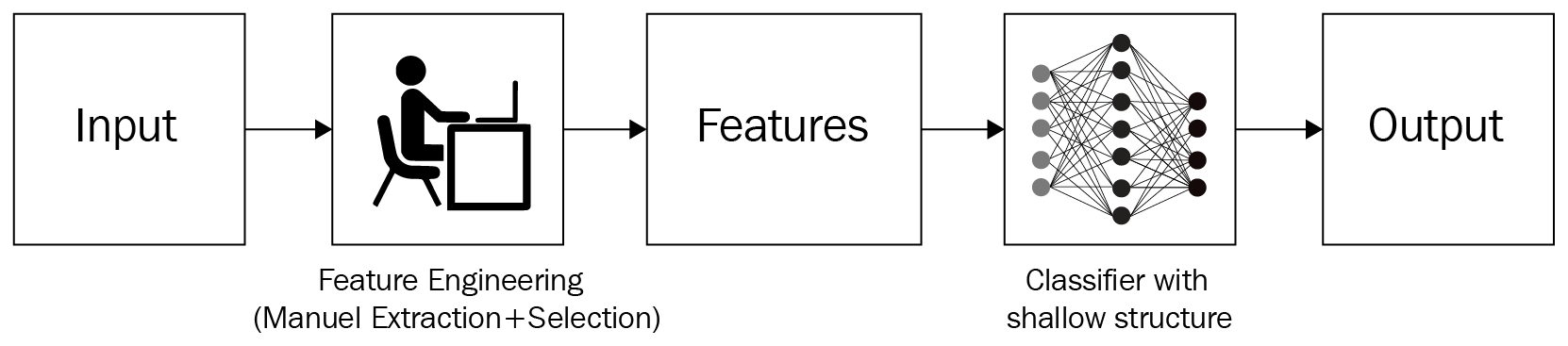
For example, say you are interested in recognizing whether a photo contains a dog or not. In the traditional Machine Learning (ML) setting, an ML practitioner or a subject matter expert first identifies the features that need to be extracted from images. Then they extract those features and pass them through a well-written algorithm that deciphers the given features to tell whether the image is of a dog or not. The following diagram illustrates the same idea:
Take the following samples:

From the preceding images, a simple rule might be that if an image contains three black circles aligned in a triangular shape, it can be classified as a dog. However, this rule would fail against this deceptive close-up of a muffin:

Of course, this rule also fails when shown an image with anything other than a dog's face close up. Naturally, therefore, the number of manual rules we'd need to create for the accurate classification of multiple types can be exponential, especially as images become more complex. Therefore, the traditional approach works well in a very constrained environment (say, taking a passport photo where all the dimensions are constrained within millimeters) and works badly in an unconstrained environment, where every image varies a lot.
We can extend the same line of thought to any domain, such as text or structured data. In the past, if someone was interested in programming to solve a real-world task, it became necessary for them to understand everything about the input data and write as many rules as possible to cover every scenario. This is tedious and there is no guarantee that all new scenarios would follow said rules.
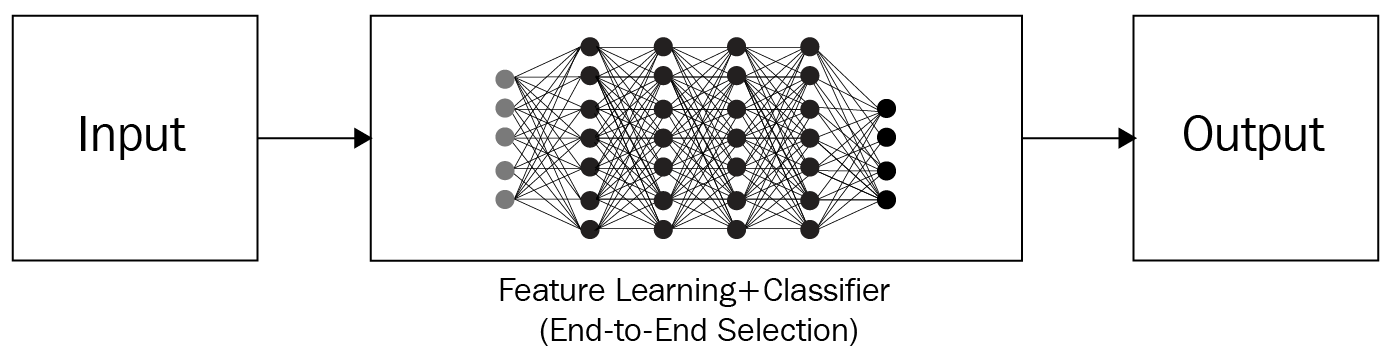
However, by leveraging artificial neural networks, we can do this in a single step.
Neural networks provide the unique benefit of combining feature extraction (hand-tuning) and use those features for classification/regression in a single shot with little manual feature engineering. Both these subtasks only require labeled data (for example, which pictures are dogs and which pictures are not dogs) and neural network architecture. It does not require a human to come up with rules to classify an image, which takes away the majority of the burden traditional techniques impose on the programmer.
Notice that the main requirement is that we provide a considerable amount of examples for the task that needs a solution. For example, in the preceding case, we need to provide lots and lots of dog and not-dog pictures to the model so it learns the features. A high-level view of how neural networks are leveraged for the task of classification is as follows:
Now that we have gained a very high-level overview of the fundamental reason why neural networks perform better than traditional computer vision methods, let's gain a deeper understanding of how neural networks work throughout the various sections in this chapter.