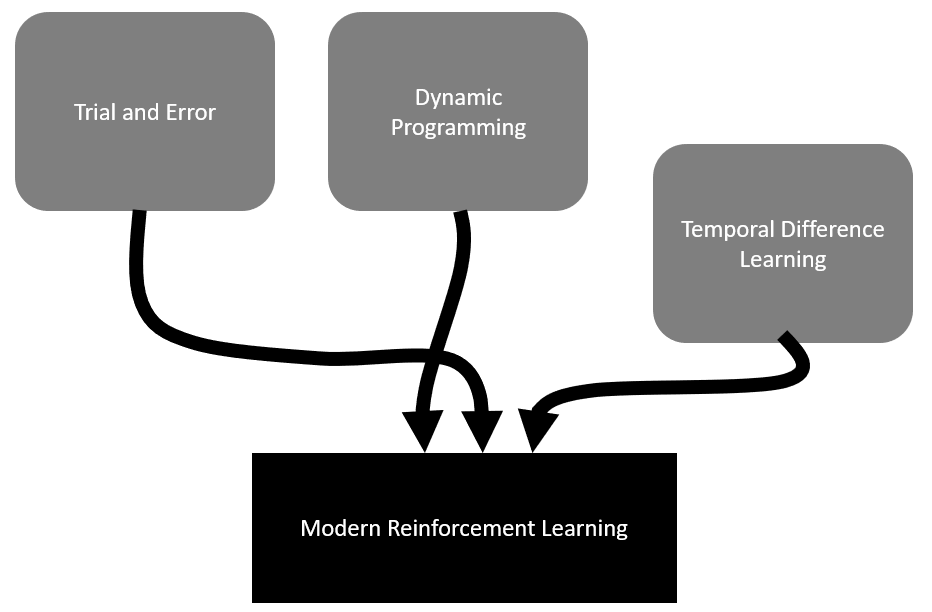
Machine learning is quickly becoming a broad and growing category, with many forms of learning systems addressed. We categorize learning based on the form of a problem and how we need to prepare it for a machine to process. In the case of supervised machine learning, data is first labeled before it is fed into the machine. Examples of this type of learning are simple image classification systems that are trained to recognize a cat or dog from a prelabeled set of cat and dog images. Supervised learning is the most popular and intuitive type of learning system. Other forms of learning that are becoming increasingly powerful are unsupervised and semi-supervised learning. Both of these methods eliminate the need for labels or, in the case of semi-supervised learning, require the labels to be defined more abstractly. The following diagram shows these learning methods and how they process data:
While this family of supervised learning methods has made impressive progress in just the last few years, they still lack the necessary planning and intelligence we expect from a truly intelligent machine. This is where RL picks up and differentiates itself. RL systems learn from interacting and making selections in the environment the agent resides in. The classic diagram of an RL system is shown here:
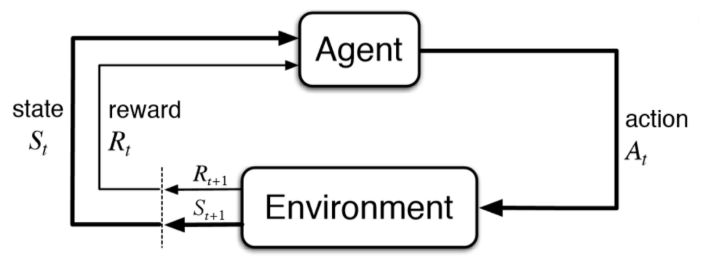
An RL system
In the preceding diagram, you can identify the main components of an RL system: the Agent and Environment, where the Agent represents the RL system, and the Environment could be representative of a game board, game screen, and/or possibly streaming data. Connecting these components are three primary signals, the State, Reward, and Action. The State signal is essentially a snapshot of the current state of Environment. The Reward signal may be externally provided by the Environment and provides feedback to the agent, either bad or good. Finally, the Action signal is the action the Agent selects at each time step in the environment. An action could be as simple as jump or a more complex set of controls operating servos. Either way, another key difference in RL is the ability for the agent to interact with, and change, the Environment.
Now, don't worry if this all seems a little muddled still—early researchers often encountered trouble differentiating between supervised learning and RL.
In the next section, we look at more RL terminology and explore the basic elements of an RL agent.