

There are two ways to achieve scalability: by scaling up or scaling out.
You can scale an application up by buying a bigger server or by adding more CPUs, memory, and/or storage to the existing one. The problem with scaling up is that finding the right balance of resources is extremely difficult. You might add more CPUs only to find out that you have turned memory into a bottleneck. Because of this, the law of diminishing returns kicks in fairly quickly, which causes the cost of incremental upgrades to grow exponentially. This makes scaling up a very unattractive option, when the cost-to-benefit ratio is taken into account.
Scaling out, on the other hand, implies that you can scale the application by adding more machines to the system and allowing them to share the load. One common scale-out scenario is a farm of web servers fronted by a load balancer. If your site grows and you need to handle more requests, you can simply add another server to the farm. Scaling out is significantly cheaper in the long run than scaling up and is what we will discuss in the remainder of this section.
Unfortunately, designing an application for scale-out requires that you remove all single points of bottleneck from the architecture and make some significant design compromises. For example, you need to completely remove the state from the application layer and make your services stateless.
Well, I might have exaggerated a bit to get your attention. It is certainly possible to write a completely stateless service:
public class HelloWorldService {
public String hello() {
return "Hello world!";
}
}However, most "stateless" services I've seen follow a somewhat different pattern:
public class MyService {
public void myServiceMethod() {
loadState();
doSomethingWithState();
saveState();
}
}Implementing application services this way is what allows us to scale the application layer out, but the fact that our service still needs state in order to do anything useful doesn't change. We haven't removed the need—we have simply moved the responsibility for state management further down the stack.
The problem with that approach is that it usually puts more load on the resource that is the most difficult and expensive to scale—a relational database.
In order to provide ACID (atomicity, consistency, isolation, and durability) guarantees, a relational database needs to perform quite a bit of locking and log all mutating operations. Depending on the database, locks might be at the row level, page level, or even table level. Every database request that needs to access locked data will essentially have to wait for the lock to be released.
In order to improve concurrency, you need to ensure that each database write is committed or rolled back as fast as possible. This is why there are so many rules about the best ways to organize the disk subsystem on a database server. Whether it's placing log files on a different disk or partitioning large tables across multiple disks, the goal is to optimize the performance of the disk I/O as it should be. Because of durability requirements, database writes are ultimately disk bound, so making sure that the disk subsystem is optimally configured is extremely important.
However, no matter how fast and well-optimized your database server is, as the number of users increases and you add more web/application servers to handle the additional load, you will reach a point where the database is simply overwhelmed. As the data volume and the number of transactions increase, the response time will increase exponentially, to the point where your system will not meet its performance objectives anymore.
When that happens, you need to scale the database.
The easiest and the most intuitive approach to database scaling is to scale up by buying a bigger server. That might buy you some time, but guess what—if your load continues to increase, you will soon need an even bigger server. These big servers tend to be very expensive, so over time this becomes a losing proposition. One company I know of eventually reached the point where the incremental cost to support each additional user became greater than the revenue generated by that same user. The more users they signed up, the more money they were losing.
So if scaling up is not an answer, how do we scale the database out?
There are three main approaches to database scale-out: master-slave replication, clustering, and sharding. We will discuss the pros and cons of each in the following sections.
Master-slave replication is the easiest of the three to configure and requires minimal modifications to application logic. In this setup, a single master server is used to handle all write operations, which are then replicated to one or more slave servers asynchronously, typically using log shipping:

This allows you to spread the read operations across multiple servers, which reduces the load on the master server.
From the application perspective, all that you need to do is to modify the code that creates the database connections to implement a load balancing algorithm. Simple round-robin server selection for read operations is typically all you need.
However, there are two major problems with this approach:
There is a lag between a write to the master server and the replication. This means that your application could update a record on the master and immediately after that read the old, incorrect version of the same record from one of the slaves, which is often undesirable.
You haven't really scaled out. Although you have given your master server some breathing room, you will eventually reach the point where it cannot handle all the writes. When that happens, you will be on your vendor's website again, configuring a bigger server.
The second approach to database scale-out is database clustering, often referred to as the shared everything approach. The best known example of a database that uses this strategy is Oracle RAC.
This approach allows you to configure many database instances that access a shared storage device:

In the previous architecture, every node in the cluster can handle both reads and writes, which can significantly improve throughput.
From the application perspective, nothing needs to change, at least in theory. Even the load balancing is automatic.
However, database clustering is not without its own set of problems:
Database writes require synchronization of in-memory data structures such as caches and locks across all the nodes in the cluster. This increases the duration of write operations and introduces even more contention. In the worst-case scenario, you might even experience negative scalability as you add nodes to the cluster (meaning that as you add the nodes, you actually decrease the number of operations you can handle).
It is difficult to set up and administer, and it requires an expensive SAN device for shared storage.
Even read operations cannot be scaled indefinitely, because any shared disk system, no matter how powerful and expensive it is, will eventually reach its limit.
In general, database clustering might be a good solution for read-intensive usage scenarios, such as data warehousing and BI (Business Intelligence), but will likely not be able to scale past a certain point in write-intensive OLTP (online transaction processing) applications.
The basic idea behind database sharding is to partition a single large database into several smaller databases. It is also known as a shared nothing approach.
It is entirely up to you to decide how to actually perform partitioning. A good first step is to identify the groups of tables that belong together based on your application's querying needs. If you need to perform a join on two tables, they should belong to the same group. If you are running an e-commerce site, it is likely that you will end up with groups that represent your customer-related tables, your product catalog-related tables, and so on.
Once you identify table groups, you can move each group into a separate database, effectively partitioning the database by functional area. This approach is also called vertical partitioning, and is depicted in the following diagram:

Unfortunately, vertical partitioning by definition is limited by the number of functional areas you can identify, which imposes a hard limit on the number of shards you can create. Once you reach the capacity of any functional shard, you will either need to scale up or partition data horizontally.
This means that you need to create multiple databases with identical schemas, and split all the data across them. It is entirely up to you to decide how to split the data, and you can choose a different partitioning strategy for each table. For example, you can partition customers by state and products using modulo of the primary key:
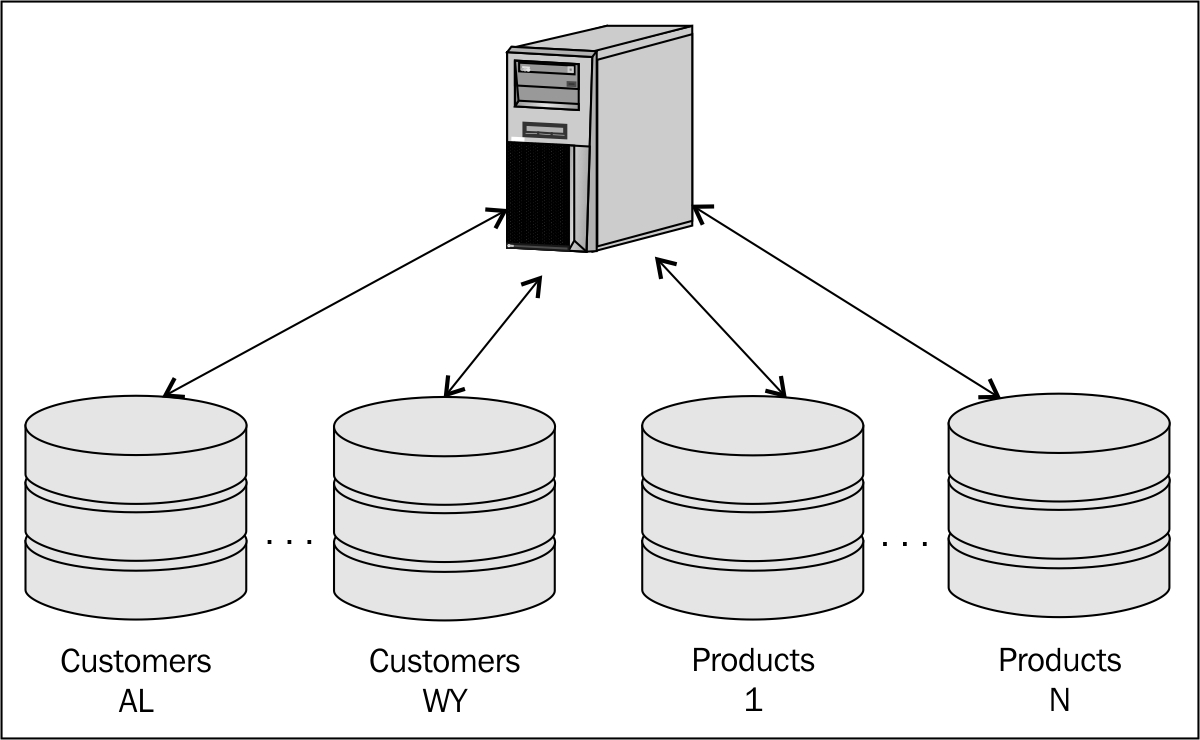
Implemented properly, database sharding gives you virtually unlimited scalability, but just like the other two strategies it also has some major drawbacks:
For one, sharding significantly complicates application code. Whenever you want to perform a database operation, you need to determine which shard the operation should execute against and obtain a database connection accordingly. While this logic can (and should) be encapsulated within the Data Access Layer, it adds complexity to the application nevertheless.
You need to size your shards properly from the very beginning, because adding new shards later on is a major pain. Once your data partitioning algorithm and shards are in place, adding a new shard or a set of shards requires you not only to implement your partitioning algorithm again, but also to undertake the huge task of migrating the existing data to new partitions, which is an error-prone and time-consuming process.
Queries and aggregations that used to be simple are not so simple anymore. Imagine your customers are partitioned by state and you want to retrieve all female customers younger than 30, and sort them by the total amount they spent on makeup within the last six months. You will have to perform a distributed query against all the shards and aggregate the results yourself. And I hope you kept track of those makeup sales within each customer row, or you might spend a few long nights trying to collect that information from a partitioned orders table.
It is likely that you will have to denormalize your schema and/or replicate reference data to all the shards in order to eliminate the need for cross-shard joins. Unless the replicated data is read-only, you will have the same consistency issues as with master-slave setup when it gets updated.
Cross-shard updates will require either distributed (XA) transactions that can significantly limit the scalability, or compensating transactions that can significantly increase application complexity. If you avoid distributed transactions and implement your own solution, you will also run into data consistency issues, as updates to one shard will be visible before you update the others and complete a logical transaction.
Failure of any single shard will likely render the whole system unusable. Unfortunately, the probability that one shard will fail is directly proportional to the number of shards. This means that you will have to implement an HA (High Availability) solution for each individual shard, effectively doubling the amount of hardware and the cost of the data layer.
Even with all these drawbacks, sharding is the approach used by some of the largest websites in the world, from Facebook and Flickr, to Google and eBay. When the pain is great, any medicine that reduces it is good, regardless of the side effects.
In the next section we will look at the fourth option for database scaling—removing the need to scale it at all.
As I mentioned earlier, removal of the state from the application has a significant increase in database load as a consequence. This implies that there is a simple way to reduce the database load—put state back into the application.
Of course, we can't really put the state back into our stateless services, as that would make them stateful and prevent them from scaling out. However, nothing prevents us from introducing a new data management layer between our stateless application logic and the database. After all, as professor Bellovin said, "any software problem can be solved by adding another layer of indirection".

Ideally, this new layer should have the following characteristics:
It should manage data as objects, because objects are what our application needs
It should keep these objects in memory, in order to improve performance and avoid the disk I/O bottlenecks that plague databases
It should be able to transparently load missing data from the persistent store behind it
It should be able to propagate data modifications to the persistent store, possibly asynchronously
It should be as simple to scale out as our stateless application layer
As you have probably guessed, Coherence satisfies all of these requirements, which makes it a perfect data management layer for scalable web applications.
Many database queries in a typical application are nothing more than primary key-based lookups. Offloading only these lookups to an application-tier cache would significantly reduce database load and improve overall performance.
However, when your application-tier cache supports propagate queries and can also scale to support large datasets across many physical machines, you can offload even more work to it and let the database do what it does best—persist data and perform complex queries.
The company I mentioned earlier, which was at risk of going bankrupt because of the high cost of scaling up their database, saw database load drop more than 80% after they introduced Coherence into the architecture.
Furthermore, because they didn't have to block waiting for the response from the database for so long, their web servers were able to handle twice the load. In combination, this effectively doubled the capacity and ensured that no database server upgrades would be necessary in the near future.
This example is somewhat extreme, especially because in this case it literally meant the difference between closing the shop and being profitable, but it is not uncommon to see a 60% to 80% reduction in database load after Coherence is introduced into the architecture, accompanied with an increased capacity in the application layer as well.
Coherence effectively eliminates the need for master-slave replication, as it provides all of its benefits without any of the drawbacks.
Read-only slaves are effectively replaced with a distributed cache that is able to answer the vast majority of read operations. On the other hand, updates are performed against the cached data and written into the database by Coherence, so there is no replication lag and the view of the data is fully coherent at all times.
By significantly reducing the total load on the database, Coherence will give your database cluster some breathing space and allow you to handle more users, or to reduce the size of the cluster.
In the best-case scenario, it might eliminate the need for the database cluster altogether, allowing you to significantly simplify your architecture.
This is by far the most interesting scenario of the three. Just like with database clustering, you might be able to completely eliminate the need for sharding and simplify the architecture by using a single database.
However, if you do need to use shards, Coherence allows you to eliminate some of the drawbacks we discussed earlier.
For one, distributed queries and aggregations are built-in features, not something that you need to write yourself. Finding all female customers younger than 30 is a simple query against the customers cache. Similarly, aggregating orders to determine how much each of these customers spent on makeup becomes a relatively simple parallel aggregation against the orders cache.
Second, Coherence allows you to protect the application against individual shard failures. By storing all the data within the grid and configuring Coherence to propagate data changes to the database asynchronously, your application can survive one or more shards being down for a limited time.
Coherence is an ideal solution for scalable data management. Scaling both capacity and throughput can be easily achieved by adding more nodes to the Coherence cluster.
However, it is entirely possible for an application to introduce contention and prevent scalability, for example, by using excessive locking. Because of this, care should be taken during application design to ensure that artificial bottlenecks are not introduced into the architecture.