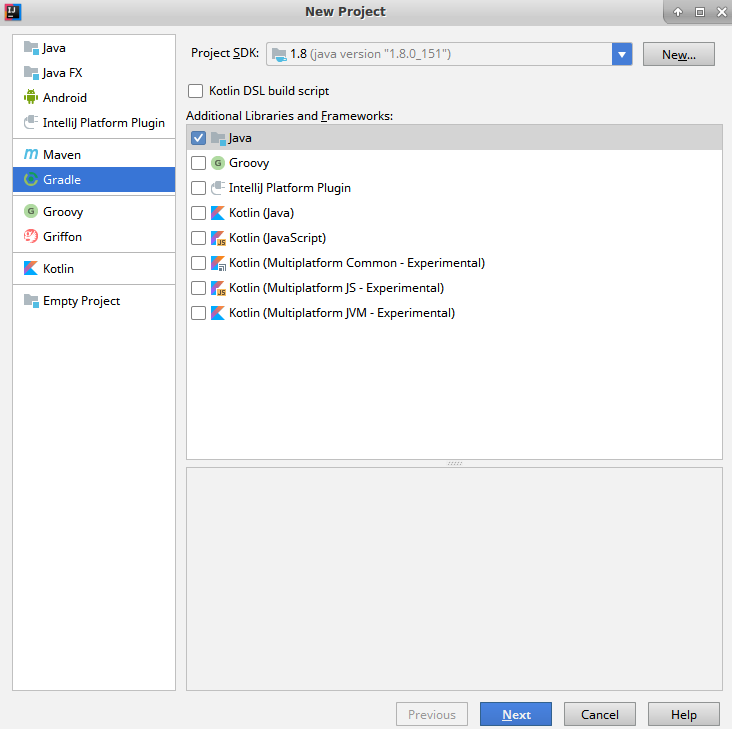
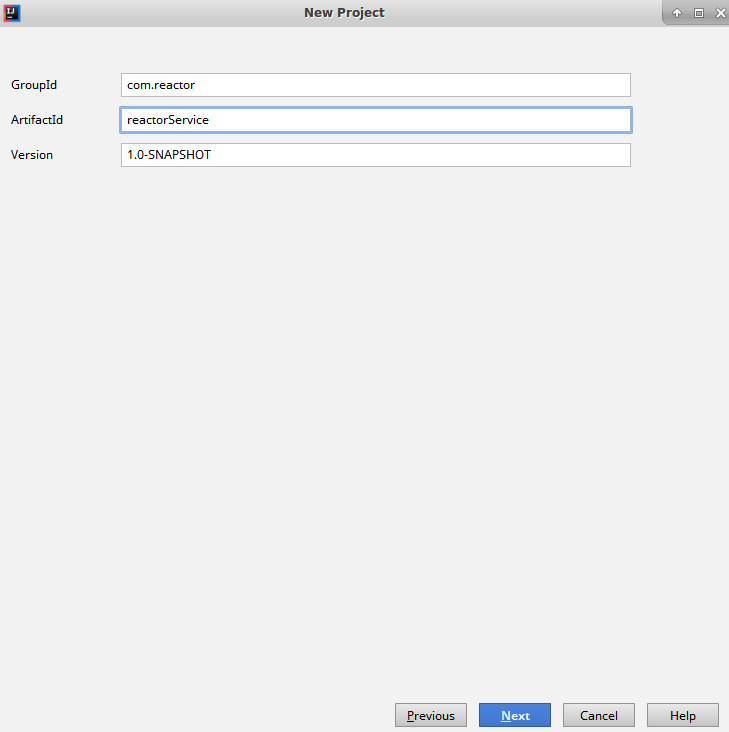
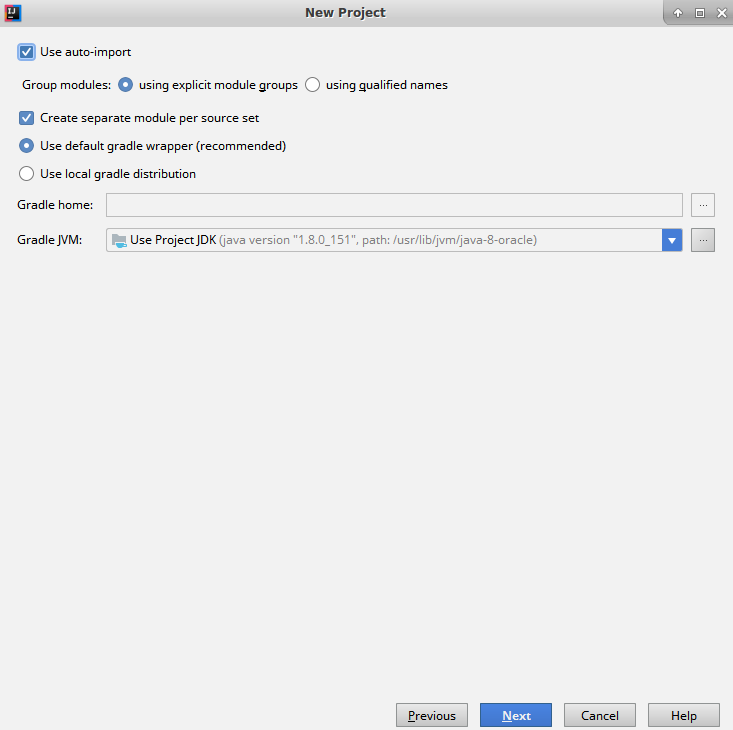
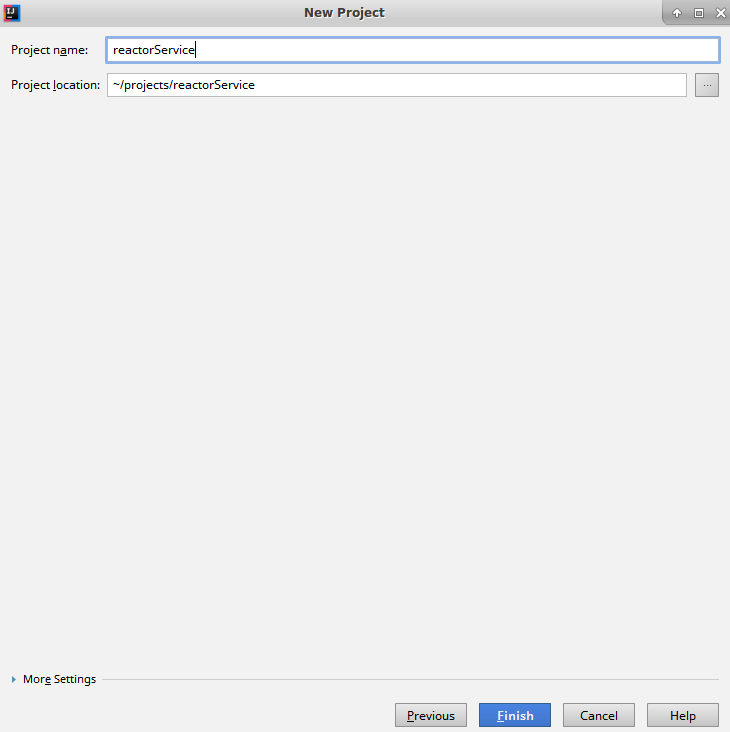
Reactor is an implementation completed by the Pivotal Open Source team, conforming to the Reactive Streams API. The framework enables us to build reactive applications, taking care of backpressure and request handling. The library offers the following features.
-
Book Overview & Buying

-
Table Of Contents

Hands-On Reactive Programming with Reactor
By :
Hands-On Reactive Programming with Reactor
By:
Overview of this book
Reactor is an implementation of the Java 9 Reactive Streams specification, an API for asynchronous data processing. This specification is based on a reactive programming paradigm, enabling developers to build enterprise-grade, robust applications with reduced complexity and in less time. Hands-On Reactive Programming with Reactor shows you how Reactor works, as well as how to use it to develop reactive applications in Java.
The book begins with the fundamentals of Reactor and the role it plays in building effective applications. You will learn how to build fully non-blocking applications and will later be guided by the Publisher and Subscriber APIs. You will gain an understanding how to use two reactive composable APIs, Flux and Mono, which are used extensively to implement Reactive Extensions. All of these components are combined using various operations to build a complete solution.
In addition to this, you will get to grips with the Flow API and understand backpressure in order to control overruns. You will also study the use of Spring WebFlux, an extension of the Reactor framework for building microservices.
By the end of the book, you will have gained enough confidence to build reactive and scalable microservices.
Table of Contents (13 chapters)
Preface
 Free Chapter
Free Chapter
Getting Started with Reactive Streams
The Publisher and Subscriber APIs in a Reactor
Data and Stream Processing
Processors
SpringWebFlux for Microservices
Dynamic Rendering
Flow Control and Backpressure
Handling Errors
Execution Control
Testing and Debugging
Assessments
Other Books You May Enjoy