In this section, we will discuss the concept of clean architecture, the problems it solves, and how it can be applied to an Android application.
Architecture can be viewed as the high-level solution that's required to build a system that can solve business and technical requirements. The goal should be to keep as many options on the table for as long as we can. From an Android development perspective, we've seen the platform grow a lot, and to balance the new changes that have been added to the platform with the addition of new features for our application and its maintenance, we will need to give our application a very good foundation so that it will adapt to changes. A common approach to architecture in Android development was the layered architecture, where apps would be split into three layers – the user interface, domain, and data layers. The problem here was that the domain layer depended on the data layer, so when the data layer changed, the domain layer needed to change too.
Clean architecture represents an integration of multiple types of architecture that provide independence from frameworks, user interfaces, and databases, as well as being testable. The shape resembles that of an onion, where dependencies go toward the inner layers. These layers are as follows:
- Entity Layer: This layer is the innermost layer and is represented by objects that hold data or business-critical functions.
- Use Case Layer: This layer implements the business logic of the system.
- Interface Adapter Layer: This layer is responsible for converting the data between the frameworks and drivers and the use case. This will hold components such as ViewModels and presenters, as well as various converters that are responsible for converting network and persistence-related data into entities.
- Frameworks and Drivers Layer: This layer is the outermost layer and is comprised of components such as activities, fragments, networking components, and persistence components.
Let's consider a scenario: you've recently been hired by a start-up company as their first Android engineer. You have been given a basic idea of what the app that you've been asked to develop should do, but there isn't anything too concrete; the user interface has not been finalized, the teams working on the backend are new themselves, and there isn't anything too concrete on their side either. What you do know is a set of use cases that specify what the app does: log into a system, load a list of tasks and add new tasks, delete tasks, and edit existing tasks. The product owner tells you that you should work on something while using mock data so that they can get a feel of the product and consult with the user interface and user experience teams to discuss improvements and modifications.
You are faced with a choice here: you can build the product that's been requested by the product owner as fast as possible and then constantly refactor your code for each new integration and the change in requirements, or you can take a little bit more time and factor in the future changes that will come into your approach. If you were to take the first approach, then you would find yourself in a situation where many developers found themselves, which is to go back and change things properly. Let's assume you chose the second approach. What would you need to do then? You can start decoupling your code into separate layers. You know that the UI will change, so you will need to keep it isolated so that when it is changed, the change will only be isolated to that particular section. Often, the UI is referred to as the presentation layer.
Next, you want to decouple the business logic. This is something specific to processing the data that your app will use. This is often done in the domain layer. Finally, you want to decouple how the data is loaded and stored. This will be the part where you deal with integrating libraries such as Room and Retrofit and it's often called the data layer. Because the requirements aren't definitive yet, you also want to decouple how you want to handle use cases so that if a use case changes, you can protect the others from that change. If you were to rotate the class diagram from Figure 1.4, you would see a layered approach to this example.
As we've mentioned previously, the fact that ConcreteData shows up in all the classes in our example is not a good idea. This is because, at the end of the day, the fact that we chose Retrofit and Moshi shouldn't impact the rest of the application. This is similar if it was the opposite way around and the activity or ViewModel would've done the same. At the end of the day, the way we choose to implement our UI or what networking library we should use represent details. Our domain layer shouldn't be impacted by any of these choices.
What we are doing here is establishing boundaries between the components in our system so that a change in a component doesn't impact a change in another component. In Android, even if we use the latest libraries and frameworks, we should still make sure that our domain is still protected by changes in those frameworks. Going back to the start-up example, and assuming you've chosen to decouple your components and pick the appropriate boundaries, after many demos and iterations, your company decides to hire additional developers to work on new, separate features. If those developers follow the guidelines you've set up, they can work with a minimal level of overlap.
The recommendation from Android development documentation is to take advantage of modules. One of the arguments is that it improves build speed because when you work on a certain module, it won't rebuild the others when you build the application – it caches them instead. Splitting your application into multiple modules serves another purpose.
Let's go back to the start-up. Things are going great and people love your product, so your company decides to open your APIs for other businesses to integrate into their systems. Your company also wants to provide an Android library so that it's easier for businesses to access your APIs. You already have this logic integrated into your application; you just need to export it. What features do you want to export? All? None? Do they want to persist data locally? Do they want some of the UI or not? If your modules were split with proper boundaries, then you would be able to accommodate all of those features. What we want to do is have a system where we can easily plug things in and easily plug them out.
Transitioning our previous example to this approach, we would have something like this. The ConcreteData class and ConcreteDataService would remain the same:
@JsonClass(generateAdapter = true)
data class ConcreteData(
@Json(name = "field1") val field1: String,
@Json(name = "field1") val field2: String
)
interface ConcreteDataService {
@GET("/path")
suspend fun getConcreteData(): ConcreteData
}
Now, we will need to isolate the Retrofit library and create the interface adapter for it. But to do that, we will need to define our entity:
data class ConcreteEntity(
val field1: String,
val field2: String
)
It looks like it's a duplicate of ConcreteData, but this is a case of fake duplication. In reality, as things evolve, the two classes may contain different data, so they will need to be separated.
To isolate the Retrofit call, we need to invert the dependency of our repository. So, let's create a new interface that will return ConcreteEntity:
interface ConcreteDataSource {
suspend fun getConcreteEntity(): ConcreteEntity
}
In our implementation, we will invoke the Retrofit service interface:
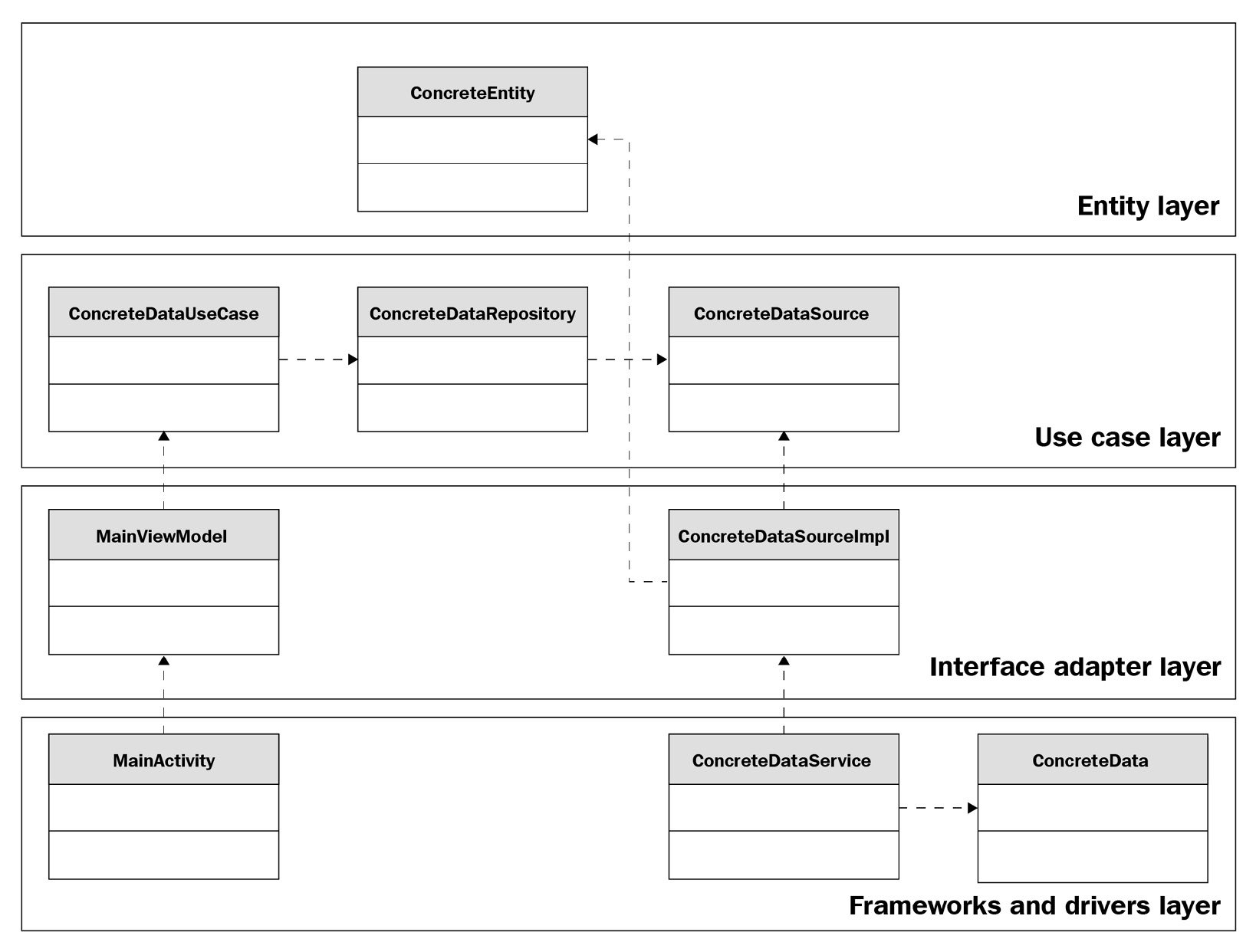
class ConcreteDataSourceImpl(private val concreteDataService: ConcreteDataService) :
ConcreteDataSource {
override suspend fun getConcreteEntity():
ConcreteEntity {
val concreteData = concreteDataService.
getConcreteData()
return ConcreteEntity(concreteData.field1,
concreteData.field2)
}
}
Here, we have invoked ConcreteDataService and then converted the network model into an entity.
Now, our repository will change into the following:
class ConcreteDataRepository @Inject constructor(private val concreteDataSource: ConcreteDataSource) {
suspend fun getConcreteEntity(): ConcreteEntity {
return concreteDataSource.getConcreteEntity()
}
ConcreteDataRepository will depend on ConcreteDataSource to avoid the dependencies on the networking layer.
Now, we need to build the use case to retrieve ConcreteEntity:
class ConcreteDataUseCase @Inject constructor(private val concreteDataRepository: ConcreteDataRepository) {
fun getConcreteEntity(): Flow<ConcreteEntity> {
return flow {
val fooList = concreteDataRepository.
getConcreteEntity()
emit(fooList)
}.flowOn(Dispatchers.IO)
}
}
ConcreteDataUseCase will depend on ConcreteDataRepository to retrieve the data and emit it using Kotlin flows.
Now, MainViewModel will need to be changed to invoke the use case. To do so, it will use the field1 object from ConcreteEntity:
@HiltViewModel
class MainViewModel @Inject constructor(private val concreteDataUseCase: ConcreteDataUseCase) :
ViewModel() {
private val _textData = MutableLiveData<String>()
val textData: LiveData<String> get() = _textData
fun loadConcreteData() {
viewModelScope.launch {
concreteDataUseCase.getConcreteEntity()
.collect { data ->
_textData.postValue(data.field1)
}
}
}
}
MainViewModel will now depend on ConcreteDataUseCase and retrieve ConcreteEntity, where it will extract field1. This will then be set in LiveData.
MainActivity will be updated to use the textData object from MainViewModel:
@AndroidEntryPoint
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
Screen()
}
}
}
@Composable
fun Screen(mainViewModel: MainViewModel = viewModel()){
mainViewModel.loadConcreteData()
UpdateText()
}
@Composable
fun UpdateText(mainViewModel: MainViewModel = viewModel()) {
val text by mainViewModel.textData.
observeAsState("test")
MessageView(text = text)
}
@Composable
fun MessageView(text: String) {
Text(text = text)
}
With that, MainActivity has been updated to use LiveData, which emits a String instead of a ConcreteData object.
Finally, the Hilt module will be updated as follows:
@Module
@InstallIn(SingletonComponent::class)
class ApplicationModule {
…
@Singleton
@Provides
fun provideHttpClient(): OkHttpClient {
return OkHttpClient
.Builder()
.readTimeout(15, TimeUnit.SECONDS)
.connectTimeout(15, TimeUnit.SECONDS)
.build()
}
@Singleton
@Provides
fun provideConverterFactory(): MoshiConverterFactory =
MoshiConverterFactory.create()
@Singleton
@Provides
fun provideRetrofit(
okHttpClient: OkHttpClient,
gsonConverterFactory: MoshiConverterFactory
): Retrofit {
return Retrofit.Builder()
.baseUrl("schema://host.com")
.client(okHttpClient)
.addConverterFactory(gsonConverterFactory)
.build()
}
@Singleton
@Provides
fun provideCurrencyService(retrofit: Retrofit):
ConcreteDataService =
retrofit.create(ConcreteDataService::class.java)
@Singleton
@Provides
fun provideConcreteDataSource(concreteDataService:
ConcreteDataService): ConcreteDataSource =
ConcreteDataSourceImpl(concreteDataService)
}
Here, we can see that ConcreteDataUseCase just invokes ConcreteDataRepository, which just invokes ConcreteDataSource. You may be wondering why this boilerplate is necessary. In this case, we have a bit of fake duplication. As the code grows, ConcreteDataRepository may connect to other data sources, and ConcreteDataUseCase may need to connect to multiple repositories to combine the data. The same can be said about ConcreteData and ConcreteEntity. Another benefit of this approach is the imposition of more rigor when it comes to development, and it creates consistency.
Let's look at the following diagram and see how it compares to Figure 1.4:
Figure 1.5 – Clean architecture
If we look at the top row, we will see the use case and the entity. We can also see that the dependencies go from the classes at the bottom toward the classes at the top, similar to how the dependencies go from the outer layers toward the inner layers here. A difference you may have noticed is that our example doesn't mention the usage of modules. Later in this book, we will explore how to apply clean architecture to multiple modules and how to manage them.
We are now back in the start-up, and you started working on the application, where you have defined a few entities and use cases and have put a simple UI in place. The product owner has asked you to deliver a demo with some mock data for tomorrow. What can you do? You can create a new implementation of your data source and plug in some mock objects that you can use to satisfy the conditions for the demo. You show the demo of the application and you receive some feedback about your UI. This means you can change your activities and fragments to render the data appropriately, and this won't impact any of the other components. What would happen if the use case were to change? In that situation, this would propagate into the rest of the other layers. This depends on the change, though, but this scenario is to be expected in this situation.






 Free Chapter
Free Chapter