


-
Book Overview & Buying

-
Table Of Contents

Deep Reinforcement Learning with Python - Second Edition
By :
Deep Reinforcement Learning with Python
By:
Overview of this book
With significant enhancements in the quality and quantity of algorithms in recent years, this second edition of Hands-On Reinforcement Learning with Python has been revamped into an example-rich guide to learning state-of-the-art reinforcement learning (RL) and deep RL algorithms with TensorFlow 2 and the OpenAI Gym toolkit.
In addition to exploring RL basics and foundational concepts such as Bellman equation, Markov decision processes, and dynamic programming algorithms, this second edition dives deep into the full spectrum of value-based, policy-based, and actor-critic RL methods. It explores state-of-the-art algorithms such as DQN, TRPO, PPO and ACKTR, DDPG, TD3, and SAC in depth, demystifying the underlying math and demonstrating implementations through simple code examples.
The book has several new chapters dedicated to new RL techniques, including distributional RL, imitation learning, inverse RL, and meta RL. You will learn to leverage stable baselines, an improvement of OpenAI’s baseline library, to effortlessly implement popular RL algorithms. The book concludes with an overview of promising approaches such as meta-learning and imagination augmented agents in research.
By the end, you will become skilled in effectively employing RL and deep RL in your real-world projects.
Table of Contents (22 chapters)
Preface

Fundamentals of Reinforcement Learning
 Free Chapter
Free Chapter
A Guide to the Gym Toolkit
The Bellman Equation and Dynamic Programming
Monte Carlo Methods
Understanding Temporal Difference Learning
Case Study – The MAB Problem
Deep Learning Foundations
A Primer on TensorFlow
Deep Q Network and Its Variants
Policy Gradient Method
Actor-Critic Methods – A2C and A3C
Learning DDPG, TD3, and SAC
TRPO, PPO, and ACKTR Methods
Distributional Reinforcement Learning
Imitation Learning and Inverse RL
Deep Reinforcement Learning with Stable Baselines
Reinforcement Learning Frontiers
Other Books You May Enjoy
Index
Appendix 1 – Reinforcement Learning Algorithms
Appendix 2 – Assessments
 of our network is given as follows:
of our network is given as follows:
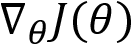 is the gradient and
is the gradient and  is known as the step size or learning rate. If the step size is large then there will be a large policy update, and if it is small then there will be a small update in the policy. How can we find an optimal step size? In the policy gradient method, we keep the step size small and so on every iteration there will be a small improvement in the...
is known as the step size or learning rate. If the step size is large then there will be a large policy update, and if it is small then there will be a small update in the policy. How can we find an optimal step size? In the policy gradient method, we keep the step size small and so on every iteration there will be a small improvement in the...






