

DQN with prioritized experience replay
We learned that in DQN, we randomly sample a minibatch of K transitions from the replay buffer and train the network. Instead of doing this, can we assign some priority to each transition in the replay buffer and sample the transitions that had high priority for learning?
Yes, but first, why do we need to assign priority for the transition, and how can we decide which transition should be given more priority than the others? Let's explore this more in detail.
The TD error  is the difference between the target value and the predicted value, as shown here:
is the difference between the target value and the predicted value, as shown here:
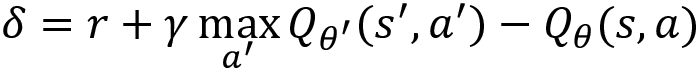
A transition that has a high TD error implies that the transition is not correct, and so we need to learn more about that transition to minimize the error. A transition that has a low TD error implies that the transition is already good. We can always learn more from our mistakes rather than only focusing on what we are already good at, right? Similarly, we can learn more...