At this point, we have a running Ceph cluster with one MON and three OSDs configured on ceph-node1. Now, we will scale up the cluster by adding ceph-node2 and ceph-node3 as MON and OSD nodes.
A Ceph storage cluster requires at least one monitor to run. For high availability, a Ceph storage cluster relies on an odd number of monitors and more than one, for example, 3 or 5, to form a quorum. It uses the Paxos algorithm to maintain quorum majority. Since we already have one monitor running on ceph-node1, let's create two more monitors for our Ceph cluster:
Add a public network address to the
/etc/ceph/ceph.conffile onceph-node1:public network = 192.168.1.0/24From
ceph-node1, useceph-deployto create a monitor onceph-node2:# ceph-deploy mon create ceph-node2Repeat this step to create a monitor on
ceph-node3:# ceph-deploy mon create ceph-node3Check the status of your Ceph cluster; it should show three monitors in the MON section:
# ceph -s # ceph mon stat

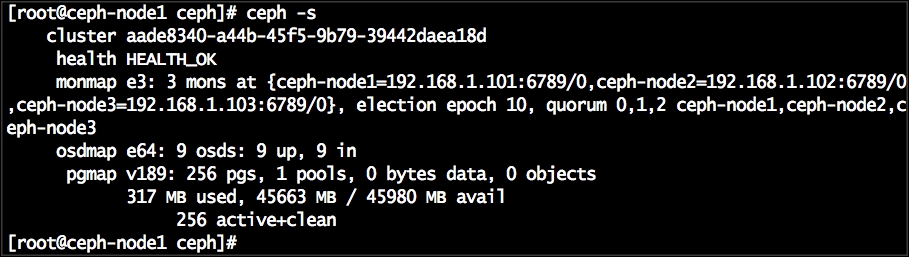
You will notice that your Ceph cluster is currently showing
HEALTH_WARN; this is because we have not configured any OSDs other thanceph-node1. By default, the date in a Ceph cluster is replicated three times, that too on three different OSDs hosted on three different nodes. Now, we will configure OSDs onceph-node2andceph-node3:Use
ceph-deployfromceph-node1to perform a disk list, disk zap, and OSD creation onceph-node2andceph-node3:# ceph-deploy disk list ceph-node2 ceph-node3 # ceph-deploy disk zap ceph-node2:sdb ceph-node2:sdc ceph-node2:sdd # ceph-deploy disk zap ceph-node3:sdb ceph-node3:sdc ceph-node3:sdd # ceph-deploy osd create ceph-node2:sdb ceph-node2:sdc ceph-node2:sdd # ceph-deploy osd create ceph-node3:sdb ceph-node3:sdc ceph-node3:sdd
Since we have added more OSDs, we should tune
pg_numand thepgp_numvalues for therbdpool to achieve aHEALTH_OKstatus for our Ceph cluster:# ceph osd pool set rbd pg_num 256 # ceph osd pool set rbd pgp_num 256
Check the status of your Ceph cluster; at this stage, your cluster will be healthy.