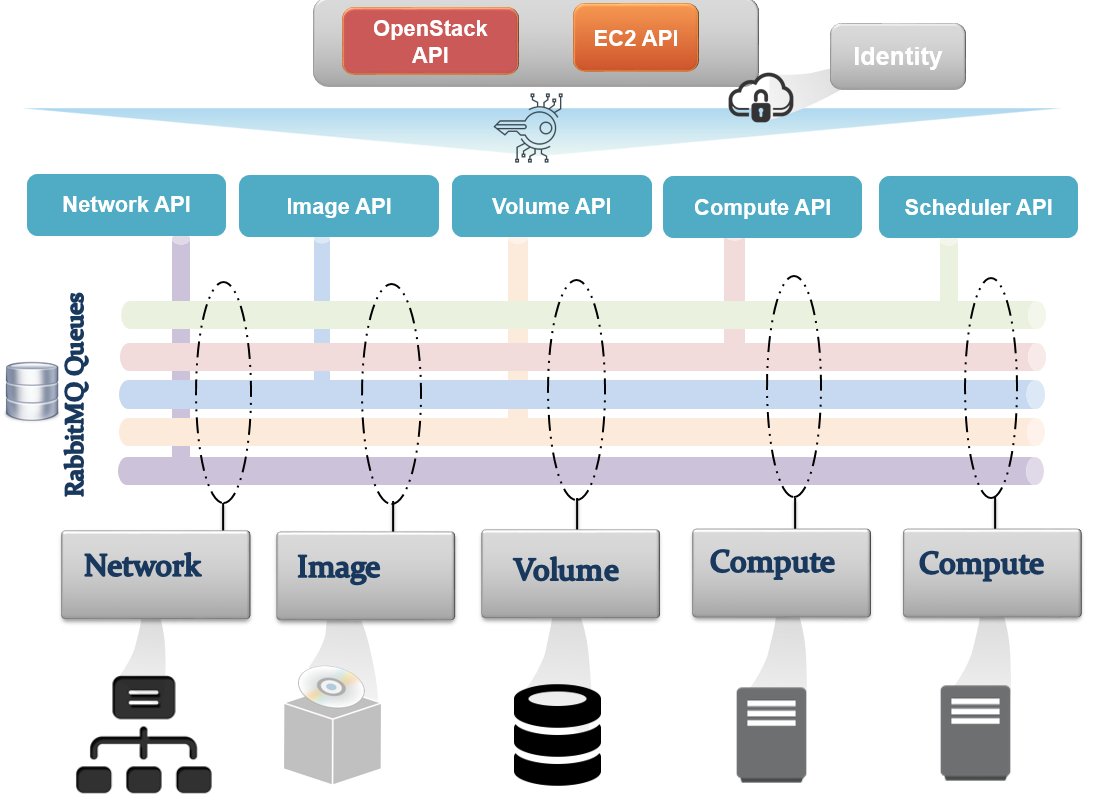
Let's try to see how OpenStack works by chaining all the service cores covered in the previous sections in a series of steps:
- Authentication is the first action performed. This is where Keystone comes into the picture. Keystone authenticates the user based on credentials such as the username and password.
- The service catalog is then provided by Keystone. This contains information about the OpenStack services and the API endpoints.
- You can use the Openstack CLI to get the catalog:
$ openstack catalog list
The service catalog is a JSON structure that exposes the resources available on a token request.
- Typically, once authenticated, you can talk to an API node. There are different APIs in the OpenStack ecosystem (the OpenStack API and EC2 API):
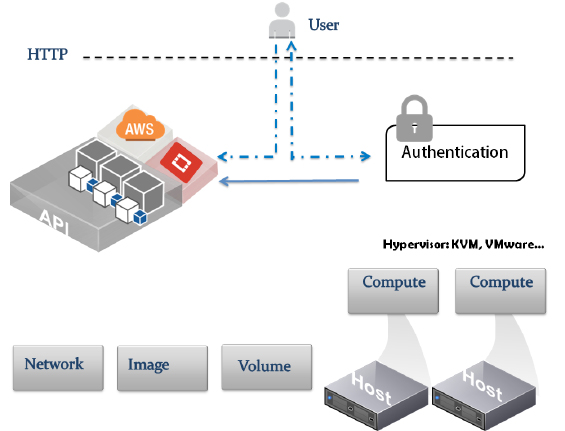
The following figure shows a high-level view of how OpenStack works:
- Another element in the architecture is the instance scheduler. Schedulers are implemented by OpenStack services that are architected around worker daemons. The worker daemons manage the launching of instances on individual nodes and keep track of resources available to the physical nodes on which they run. The scheduler in an OpenStack service looks at the state of the resources on a physical node (provided by the worker daemons) and decides the best candidate node to launch a virtual instance on. An example of this architecture is nova-scheduler. This selects the compute node to run a virtual machine or Neutron L3 scheduler, which decides which L3 network node will host a virtual router.
The scheduling process in OpenStack Nova can perform different algorithms such as simple, chance, and zone. An advanced way to do this is by deploying weights and filters by ranking servers as its available resources.