

Now that we understand a bit about enterprise virtualization, elastic cloud computing, and the origin of OpenStack, let's discuss some details about the OpenStack project.
About OpenStack
The OpenStack Foundation
The OpenStack Foundation was created in 2012 with the simple mission to protect, empower, and promote OpenStack software and the community around it.
Since the Foundation's initial formation, there have been more than fifteen OpenStack Summits. The OpenStack Summit is an incredible gathering of more than 5,000 software developers, CIOs, systems engineers, and technical writers from all over the world. Membership of the foundation is free and accessible to anyone; everyone from individual contributors to large enterprises are members, including companies like AT&T, Red Hat, Rackspace, Ubuntu, SUSE, Google, and IBM.
Even if you haven't used OpenStack yet, join the OpenStack Foundation! It's fast, free, and fun. https://www.openstack.org/join/ .
The four opens
The OpenStack Foundation is committed to ensuring that OpenStack follows "the four opens":
- Open source: The OpenStack source code is licensed under the Apache License Version 2.0 (APLv2). OpenStack is committed to creating truly open source software that is usable and scalable.
- Open design: OpenStack is also committed to an open design process. Every six months, the development community meets for a Project Team Gathering (PTG) to create the roadmap for the next release. This includes brainstorming ideas, gathering requirements, and writing blueprints for upcoming releases. The PTGs are always open to the public.
- Open development: OpenStack keeps its source code publicly available through the entire development process (https://github.com/openstack). Everything is open, including code reviews, release roadmaps, and technical discussions.
- Open community: All processes are documented, open, and transparent. The technical governance of the project is democratic, with a community of contributors electing technical leads and members of technical committees. Project meetings are held in public IRC channels, and technical communication is primarily done through public mailing lists.
OpenStack types
Wandering the exhibition floor of an OpenStack Summit can be extremely daunting to the OpenStack newcomer. Every major IT company appears to have some sort of OpenStack solution, and it's often difficult to decipher what is actually being offered. The best way to explain these various OpenStack offerings is by breaking them down into four distinct types. See Figure 1.2.
- Project: The OpenStack project can be found at http://github.com/openstack. This contains the publicly available source code that thousands of developers are actively committing to throughout the day. It's free to download and install yourself.
- Distributions/appliances: OpenStack is incredibly complex due to its many moving parts, and therefore difficult to deploy, manage, and support. To reduce complexity, companies and communities alike create OpenStack distributions or "appliances." These are easy, turnkey approaches to deploying OpenStack. They typically provide opinionated methods for deployment by using popular configuration management tools such as Ansible, Puppet, or Chef. They may install OpenStack directly from the project source code on GitHub, or via packages that have been developed by popular operating system communities like Ubuntu and Red Hat.
- Hosted private clouds: Customers looking for the security and reliability of a private OpenStack cloud without the need to manage it themselves should consider a hosted private cloud solution. These solutions typically use an existing OpenStack distribution and also include 24/7 customer support, with guaranteed uptime via an SLA (Service Level Agreement).
- Public clouds: There are quite a few public clouds built on OpenStack software. These include Rackspace and OVH Public Cloud. Similar to Amazon Web Services, Azure, or Google Cloud Platform, an OpenStack Public Cloud solution resides in the provider's data centers. The provider is responsible for the management of the environment, which is used by multiple customers on shared hardware.
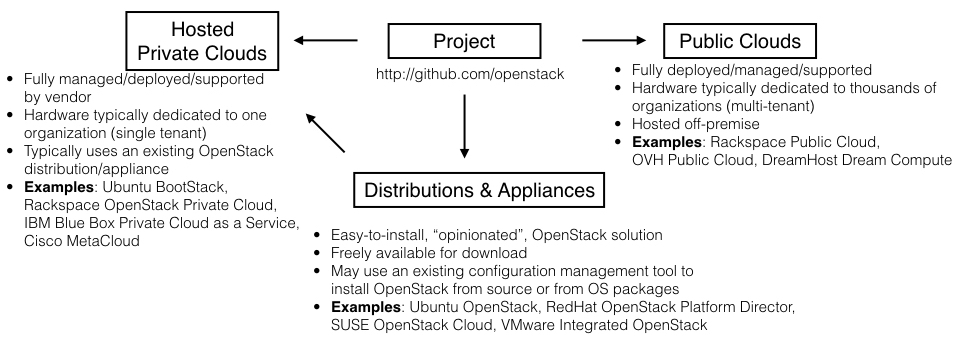
Figure 1.2: Different types of OpenStack
OpenStack jobs
As you can see from Figure 1.3, the need for those with OpenStack skills has been increasing over the years:
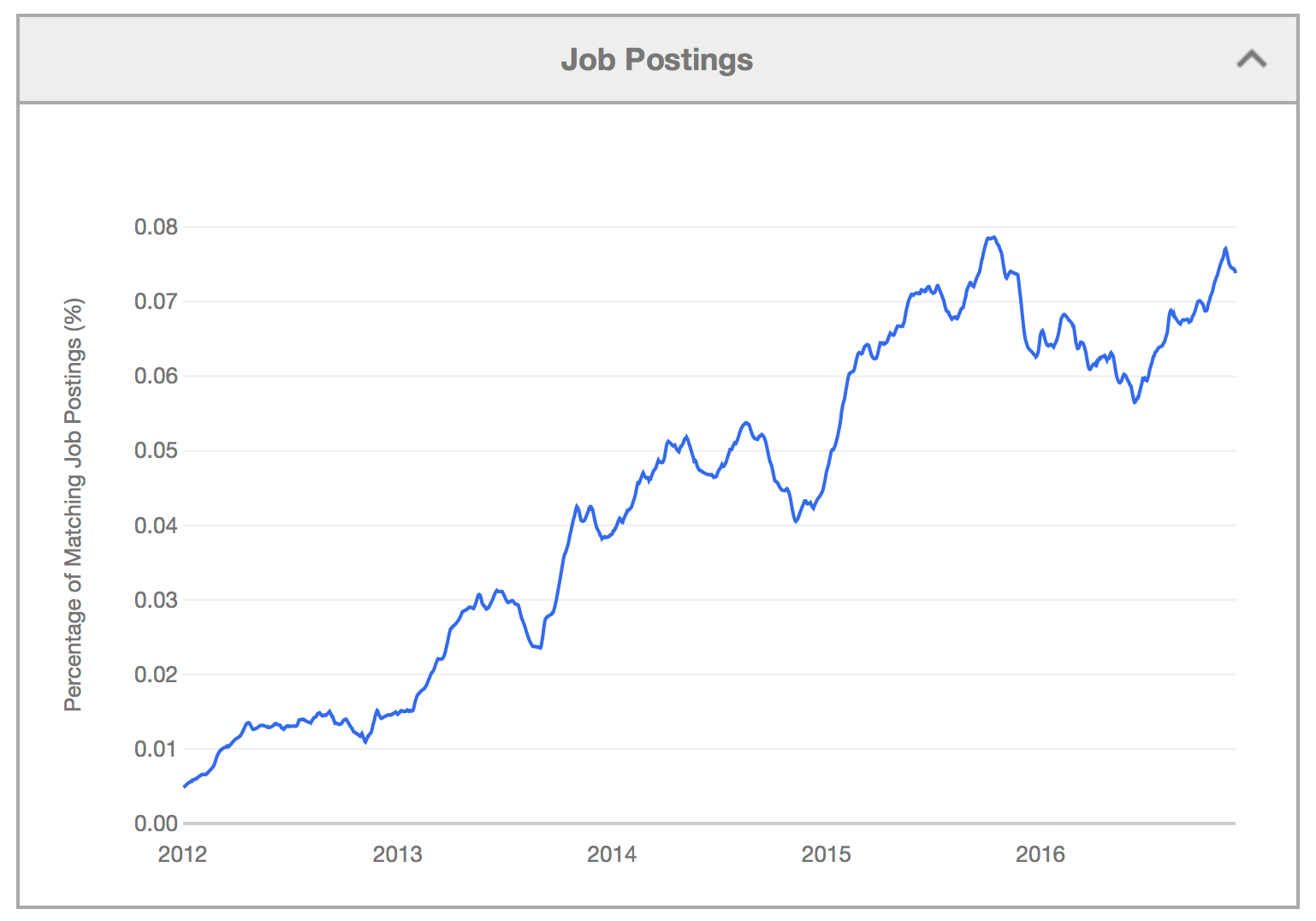
Figure 1.3: An increase in OpenStack Job postings since 2012
But what specific positions are available to those who know OpenStack? Let's break down a few of the different roles an individual with OpenStack skills may possess.
Application developer - developing on OpenStack
The application developer who understands OpenStack uses it to create virtual resources so they can deploy their applications on top of OpenStack. They typically have a background in Amazon Web Services, Azure, or Google Cloud Platform, and treat OpenStack as an Infrastructure as a Service (IaaS) platform. They are most likely full-stack developers, well-versed in all layers of web applications. They love the speed and agility of OpenStack. It allows them to instantly deploy an application when inspiration strikes and ship applications to their customers quickly and efficiently.
OpenStack administrator/operator - administrating the cloud
The OpenStack administrator or operator is the target audience for the Certified OpenStack Administrator exam. This individual typically has some years of experience as a Linux System Administrator, and is comfortable acting as the go-to individual for all OpenStack-related questions. They are responsible for managing new users, domains, and projects. They must also know how to interact with OpenStack, as well as how to train others to create virtual resources using the services installed in the environment.
OpenStack engineer/infrastructure engineer - doing the DevOps thing
An OpenStack engineer may spend a lot of their time in the datacenter working with automation tools like Puppet, Chef, and Ansible. When OpenStack needs more capacity, the OpenStack engineer is responsible for racking, stacking, and wiring up the servers, ensuring the operating systems have the latest patches, and seeing that all proper OpenStack components get the proper configuration file values, permissions, and settings. Although the Certified OpenStack Administrator exam doesn't require test takers to understand specific values for configuration files (or how to upgrade existing services), OpenStack engineers most likely know how to do this inside and out—often finding themselves working on automation scripts to ease their daily responsibilities.
OpenStack product developer - simplifying OpenStack deployment/management
The OpenStack product developer works on developing an OpenStack distribution or appliance. They understand the difficulty of building clouds; in turn, they create opinionated distributions to ease the OpenStack deployment and management process. Examples include Red Hat OpenStack Platform Director, SUSE OpenStack Cloud, and Rackspace Private Cloud. These companies may also offer professional service or support in addition to the product.
Upstream OpenStack developer - making OpenStack better!
Those eager to contribute to the actual OpenStack project are known as OpenStack upstream developers. These developers develop for OpenStack—building blueprints, chatting with other OpenStack developers on IRC, attending the PTG meet-ups, and contributing code—as they to make OpenStack the ubiquitous cloud operating system. Upstream developers have an impact on the OpenStack roadmap and are part of a healthy community that strengthens enterprise adoption.
OpenStack services overview
OpenStack is made up of a variety of services that are all written in the Python programming language and serve a specific function. OpenStack's modular nature facilitates the modern cloudy application design philosophy and also allows easy expandability; any person, community, or company can develop an OpenStack service that can easily integrate into its ecosystem.
The OpenStack Foundation has successfully identified nine key services they consider part of the core of OpenStack, which we'll explore in detail.
Keystone - identity service
Keystone handles authentication. It acts as a common authentication system across all core services in an OpenStack environment. Both human users and services must authenticate to Keystone to retrieve a token before interacting with other services in the environment.
Visualize the process of logging on to a website with your username and password. When a user does this on the Horizon dashboard, they authenticate against Keystone to successfully login and begin creating virtual resources. Keystone also stores the service catalog, users, domains, projects, groups, roles, and quotas—exam objective concepts you'll examine in Chapter 3, Keystone Identity Service.
Glance - image service
Glance provides discovery, registration, and delivery services for disk images.
When one boots a virtual machine (also known as an instance), it is typically required to provide a disk image. These typically contain an operating system (such as Ubuntu or Red Hat Enterprise Linux), and are best described as a snapshot of a disk's contents. Examples of disk image types include QCOW2, VMDK, VHDX, ISO, and RAW. The disk image has usually been previously created by a person or script who has gone through the initial installation procedure and has installed specific configuration files to ensure it is cloud-aware. Glance can store images in a variety of data stores, including the local filesystem or OpenStack Swift.
Nova - compute service
Inspired by Amazon EC2, Nova is the compute service and the core of the OpenStack cloud. It is designed to manage and automate pools of compute resources, and can work with widely available virtualization technologies as well as bare metal servers.
It's important to note that Nova is not a hypervisor. It's a system of services that sit above the hypervisor, orchestrating availability of compute resources. Some examples of hypervisors include Hyper-V, VMware ESXi, Xen, and the most popular, KVM (Kernel-based Virtual Machine). Nova also supports the ability to utilize Linux container technology such as LXC and Docker.
In OpenStack, the term booting is used to refer to the creation of a virtual machine. A virtual machine booted with Nova is often called an instance.
Neutron - networking service
Neutron is a service that allows users to manage virtual network resources and IP addresses.
If one wants to boot an instance, they typically need to provide a virtual network on which to boot that instance so that it has network connectivity. With Neutron, users can view their own networks, subnets, firewall rules, and routers—all through the Horizon dashboard, CLI, or API. One's ability to create and manage network resources depends on the specific role they have been assigned.
Neutron also contains a modular framework powered by a variety of plugins, agents, and drivers, including Linux bridge and Open vSwitch.
Cinder - block storage service
Inspired by Amazon's Elastic Block Storage (EBS) offering, Cinder allows users to create volumes that can be mounted as devices by Nova instances.
Cinder volumes behave as if they were raw unformatted hard drives. Once data is written to these volumes, the data persists even after terminating the instance or an instance failure. This is because the written data is stored on a dedicated Cinder storage server, not the compute nodes where the instances reside. Cinder also supports snapshots which capture the current state of a volume. These are useful for providing backup protection, and they can also be used to instantiate new volumes that contain the exact data of the snapshot. You can also write images to a block storage devices for compute to use as a bootable persistent instance.
Swift - object storage service
Inspired by Amazon S3, Swift is a redundant storage system that provides developers and IT teams with secure, durable, and highly scalable cloud storage. A user creates a container and stores static files, also known as objects, in the container. These objects can be anything from pictures or movies to spreadsheets and HTML files. From the end user's perspective, storage is limitless, inexpensive, and accessible via a REST API. Features can also be turned on via the Swift API. These include hosting a static website, versioning, setting specific objects to expire, and even setting Access Control Lists (ACLs) allowing public access to the objects inside the container.
On the backend of Swift, static files (also known as objects) are written to multiple disk drives spread throughout servers in a data center. The Swift software is responsible for ensuring data replication and integrity across the cluster. Should a server or hard drive fail, Swift replicates its contents from other active nodes to a new location in the cluster.
Heat - orchestration service
Inspired by Amazon's CloudFormation service, Heat helps operators model and set up OpenStack resources so that they can spend less time managing these resources and more time focusing on the applications that run on OpenStack.
You begin with a blueprint or Heat Orchestration Template (HOT) that describes all the OpenStack resources to be provisioned. Heat then takes care of provisioning and configuring, with no need to worry about dependencies or order of execution—a template describes all the resources and their parameters. After the stack has been created, your resources are up and running.
Templates are extremely convenient because they allow operators to check them into a version control system to easily track changes to the infrastructure. If problems occur after deploying a Heat template, you simply restore to a previous version of the template. If you want to make a change to the stack, you can easily update it by providing a modified template with new parameters.
OpenStack services in action
Let's take a high-level look at these OpenStack services in the wild, from the perspective of the Horizon dashboard home screen. See Figure 1.4.

Figure 1.4: OpenStack services on the Horizon dashboard
Let's start from the top:
- Instances: The Nova instances section is where you can manage your virtual machines. You can start, stop, pause, lock, and suspend instances—as well as create snapshots, view console logs, and log in into the instances via an interactive console. Learn more about this section in Chapter 5, Nova Compute Service.
- Volumes: In this section, you can create Cinder block volumes, snapshots, and backups. You can also attach your volumes to instances. Learn more about this section in Chapter 7, Cinder Block Storage Service.
- Images: The Glance images section is where you can see your currently available images as well as upload images and edit metadata associated with the images. Learn more about this section in Chapter 4, Glance Image Service.
- Access & Security: This section is a mix of a few services and contains four primary sections: Neutron Security Groups, Nova Keypairs, a list of Service Catalog public endpoints, and a place to download a pre-populated credential file for interacting with OpenStack with a command-line interface with the currently logged-in user. Learn more about this section in Chapter 3, Keystone Identity Service, Chapter 5, Nova Compute Service, and Chapter 6, Neutron Networking Service.
- NETWORK: In this section, you can utilize Neutron by creating tenant networks, tenant subnets, routers, and floating IPs. Learn more about this section in Chapter 6, Neutron Networking Service.
- ORCHESTRATION: Here, you can create Heat stacks by either uploading a Heat orchestration template or pasting it into the dashboard. You can also list and update existing stacks in this area. Learn more about this section in Chapter 9, Heat—Orchestration Service.
- OBJECT STORE: Create Swift containers and upload static objects such as photos, movies, and HTML files. Learn more about this section in Chapter 8, Swift—Object Storage Service.
- Admin: This admin panel only appears when the user logging in has the admin role. It features an admin-only look at all virtual resources across all domains and projects in the environment.
- Identity: This is where Keystone domains, projects, users, roles, and quotas are listed. If one has the admin role, they can do a variety of things in here, including creating new projects, adding new users to those projects, assigning roles, and modifying quotas. Learn more about this section in Chapter 3, Keystone Identity Service.
Interacting with OpenStack
The power of OpenStack is in the REST API of each core service. These APIs can be publicly exposed and thus accessible from anywhere in the world with public internet access: a smartphone, a laptop on the coffee shop WiFi network, or remote office.
There are a variety of ways in which one can interact with OpenStack to create virtual resources from anywhere. As we work our way down these various methods, the amount of automation increases, allowing a software developer to easily create virtual resources and deploy applications on top of those resources with minimal user interaction. See Figure 1.5.
- Horizon dashboard (GUI): If you are new to OpenStack, this is the best place to begin your journey. You simply navigate to the Horizon URL via the web browser, enter your username and password, verify you are scoped to the proper project, and then proceed—creating instances, networks, and volumes with the click of a button. See Figure 1.4 for where the services are located upon first logging in. Because not all OpenStack service features are available via the Horizon dashboard, you will need to also interact with OpenStack services via the command-line interface to utilize additional functionality.
A majority of the exam objectives can be completed via the Horizon dashboard. Each chapter will break down completing objectives via the command-line interface and Horizon dashboard (when available).
- Command-line interface (CLI): The OpenStack command line interface will unlock a majority of the OpenStack service features and can easily be installed on Windows, Mac, and Linux systems. For Linux gurus with Bash shell experience, the CLI is the tool of choice.
- Software development kit (SDK): Although the bash shell and OpenStack CLI combination are extremely powerful, SDKs provide more expressiveness. One example scenario: a developer hosting their popular application on OpenStack virtual infrastructure so that additional resources can be automatically provisioned when specific thresholds are met. Or, imagine an Android application that allows an organization's employees to create OpenStack resources with a few simple clicks of a button. Simply put, OpenStack SDKs allow you to programmatically interact with OpenStack services in the comfort of your favorite language. OpenStack SDKs are currently available in the following languages: C, C++, Closure, Erlang, Go, Java, JavaScript, .NET, Node.js, Perl, PHP, Python, and Ruby.
- Heat orchestration template (HOT): You can deploy Heat templates (similar to Amazon Web Service CloudFormation Blueprints) that utilize the OpenStack service APIs—creating OpenStack resources with the simple click of a button. The user defines their application by describing OpenStack resources in the template. The Heat templates provide maximum automation to the cloud user, deploying an entire application without manual creation of individual resources or dependencies. One can even check these into a version control system such as Git to easily track changes to the infrastructure.
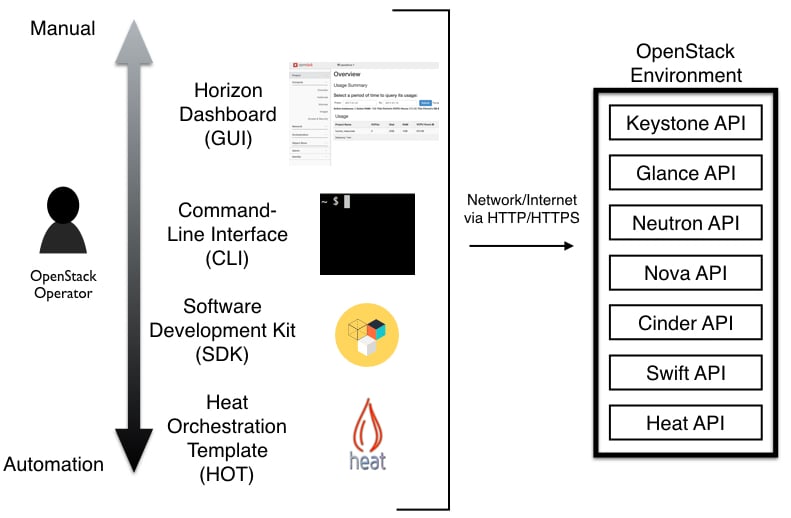
Figure 1.5: The various methods one can use to interact with an OpenStack environment
The OpenStack clients
Although the majority of the COA exam can be completed on the Horizon dashboard, understanding how to use the OpenStack CLI is critical if you want to pass! Although it can appear a bit unsettling to those with minimal experience, over time you'll notice that the CLI will reveal the true fun of OpenStack.
Service-based clients - traditional clients
Every core OpenStack service has an associated command-line client. Like the OpenStack services, the command-line clients are written in the Python programming language (available at http://github.com/openstack). The clients also contain the service API bindings for developing Python code that can talk directly to a specific service without requiring long-winded API requests. For years, the most popular clients used by OpenStack administrators were the following:
- python-keystoneclient
- python-glanceclient
- python-neutronclient
- python-novaclient
- python-cinderclient
- python-swiftclint
- python-heatclient
Python-openstackclient - the unified client
Because it was quite frustrating to remember commands for each separate client, the OpenStack community created a new OpenStack client called OSC (OpenStack Client) in 2013. The actual program is named python-openstackclient and available at http://github.com/openstack/python-openstackclient.
See Figure 1.6. python-openstackclient is a CLI client for OpenStack that brings all the traditional service-based clients into a single shell with a uniform command structure. It has a consistent and predictable format for all of its commands and takes the following form:
openstack [<global-options>] <object-1> <action> [<object-2>] [<command-arguments>]
For example, if you wanted to create a brand new Nova virtual machine instance, you could simply run:
$ openstack server create demo-instance1 --flavor m1.tiny --image cirros MyFirstInstance
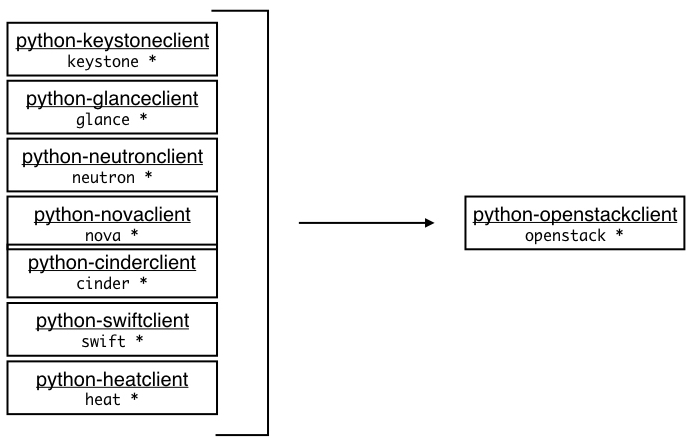
Figure 1.6: python-openstackclient brings the traditional service-based clients into a single shell with a uniform command structure
You can also view help commands by running the following:
$ openstack help
The OpenStack clients will be discussed in more detail in upcoming chapters. As of September 2017, the COA exam tests on the Newton version of OpenStack. The exam will provide access to python-openstackclient and all service-based clients. A majority of the exam objectives can be completed with python-openstackclient, except where noted in this book.
OpenStack daemon communication
Now that we've discussed the various ways in which an OpenStack operator interacts with OpenStack via the API, let's discuss internal communication among the core OpenStack services. In Figure 1.7, you can see the color code in the top left that shows the service and daemon. The service is simply the name of the OpenStack service, while the daemon represents the program that is actually running to bring the service to life.
To avoid tight coupling, communication amongst the daemons within a specific service is achieved via an Advanced Message Queueing Protocol (AMQP). In a typical OpenStack environment, this can be software such as RabbitMQ or Qpid.
Recall the cloudy development methodology that we discussed in the history portion of this chapter. While OpenStack encourages its software developers to follow this methodology when deploying applications on it, the actual OpenStack infrastructure follows the exact same principles: highly available, scalable, and loosely coupled.
For example, when a user sends a request to nova-api to boot a server, nova-api will publish this message on the AMQP bus. This message will then be read by nova-scheduler. Now let's visualize an OpenStack cloud that often receives hundreds of requests to boot instances. To solve this problem you would deploy more servers in the infrastructure, install more nova-scheduler daemons, and simply point them to the OpenStack environment's AMQP server. That's Horizontal scaling in action!
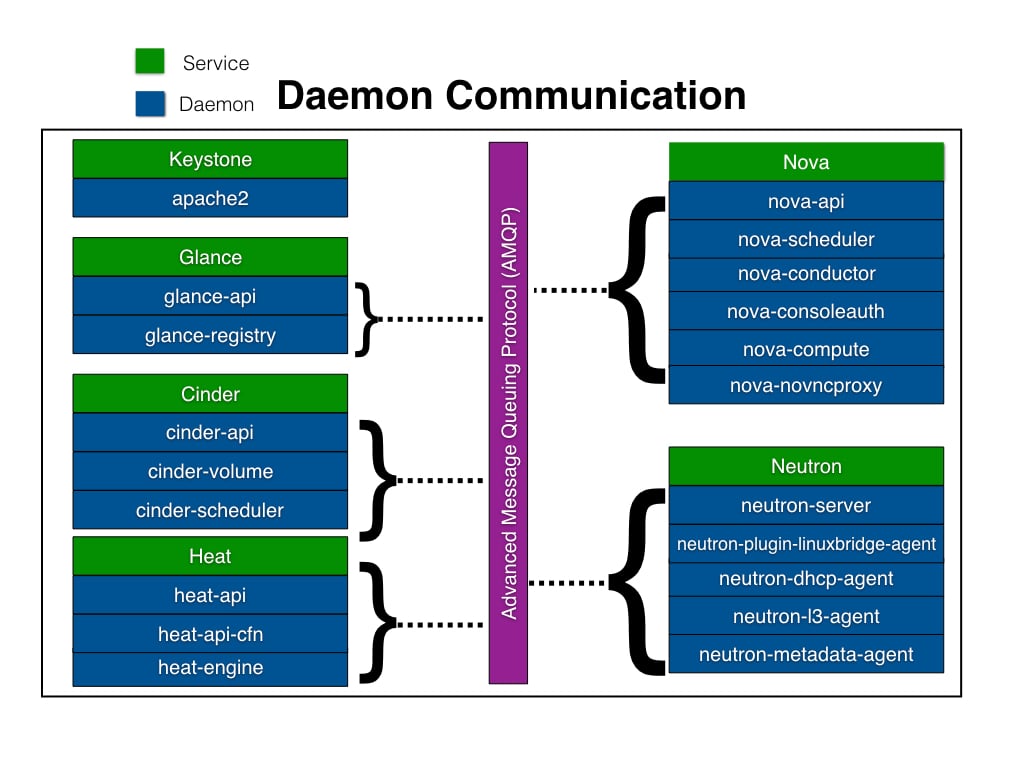
Figure 1.7: OpenStack daemons within a specific service use the AMQP bus to communicate among themselves
OpenStack API communication
While the OpenStack service daemons rely on AMQP for communication among daemons within their specific service, the APIs are used both by OpenStack users wishing to create virtual resources and for service-to-service communication.

Figure 1.8: An example of API communication amongst OpenStack services
Envision a user sending a request to nova-api to boot an instance. In order to boot that server, quite a few internal API calls would need to take place. Let's look at an example sequence of API calls that would take place when booting a virtual machine instance.
An OpenStack user would first send a POST API call to the nova-api daemon with details about what sort of virtual machine they'd like. That message would get put on the AMQP message bus and consumed by the nova-scheduler daemon. The nova-scheduler daemon would then choose the best fit for the virtual machine using its scheduling algorithm. The nova-compute daemon residing on the compute node consumes this message. Before the server can be boot, the following must occur (see Figure 1.8):
- (1): The nova-compute daemon sends an API request to Keystone to retrieve a scoped token.
- (2): nova-compute gets back a 200 HTTP response along with a scoped token. Now nova-compute has a scoped token and can freely communicate with other OpenStack services.
- (3): nova-compute now sends a request to neutron-server to verify whether the specified virtual network on which to boot the instance is available.
- (4): nova-compute receives a response that the network is available and capable of attaching to the instance.
- (5): nova-compute must then send an API call to glance-api to retrieve the operating system image.
- (6): The glance-api responds back with the image that will reside on the compute node.
Now our instance will be booted! That was a lot of work!
Don't worry! You don't need to understand all the magic occurring behind the scenes in OpenStack to be successful on the exam. This is for educational purposes only!