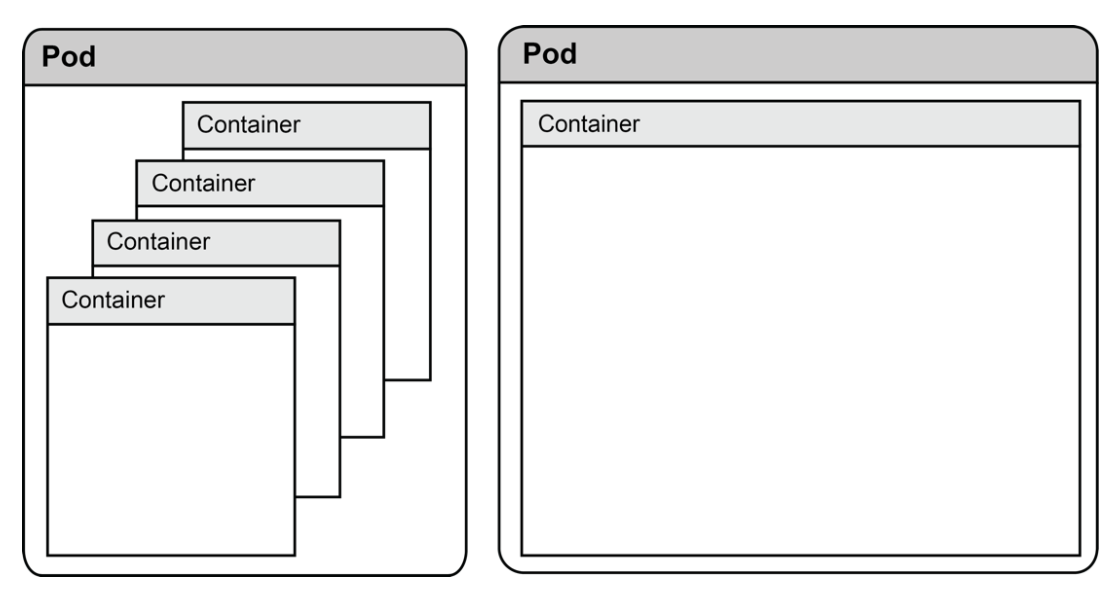
Like a group of whales, or perhaps a pea pod, a Kubernetes pod is a group of linked containers. As the following diagram shows, a pod can be made up of one or more containers; often a pod might just be a single container:
Pods are a logical grouping of one or more containers
Each pod that Kubernetes schedules is allocated its own unique IP address. The network namespace (and thus the pod's IP address) is shared by each container in the pod.
This means that it is convenient to deploy several containers together that closely collaborate over the network. For example, you might deploy a reverse proxy alongside a web application to add SSL or caching capabilities to an application that does not natively support them. In the following example, we achieve this by deploying a typical web application server-for example, Ruby on Rails—alongside a reverse proxy—for example, NGINX. This additional container provides further capabilities that might not be provided by the native application. This pattern of composing functionality together from smaller isolated containers means that you are able to reuse components more easily, and makes it simple to add additional functionality to existing tools. The setup is shown in the following diagram:
Providing additional capabilities by composing multiple containers
As well as sharing the network namespace, Kubernetes also allows very flexible sharing of volume mounts between any number of containers in a pod. This allows for a number of scenarios where several components may collaborate to perform a particular task.
In this example, we are using three containers that coordinate to serve a website built with a static-site generator using the NGINX webserver.
The first container uses Git to pull and update the source code from a remote Git repository. This repository is cloned into a volume that is shared with the second container. This second container uses the Jekyll framework to build the static files that will be served by our webserver. Jekyll watches the shared directory for changes on the filesystem and regenerates any files that need to be updated.
The directory that Jekyll writes the generated files to is shared with a container running NGINX that serves HTTP requests for our website, as shown in the following diagram:
We are using Jekyll here as an example, but there are many tools you can use to build static websites, such as Hugo, Hexo, and Gatsby. Splitting your application into separate containers like this means that it is simple to upgrade a single component, or even try an alternative tool.
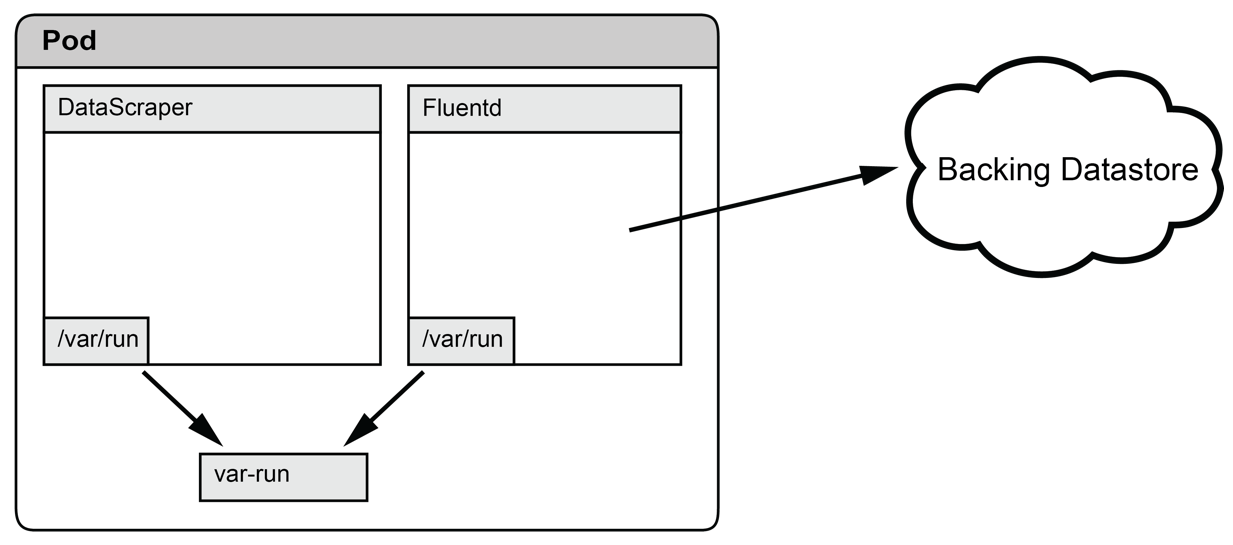
Another use for pods that share volume mounts is to support applications that communicate using Unix sockets, as shown in the following diagram. For example, an extract transform load (ETL) system could be modeled as several independent processes that communicate with UNIX sockets. This might be beneficial if you are able to make use of third-party tools for some or all of your pipeline, or reuse tools that you may have built for internal use in a variety of situations:
In this example, a custom application designed to scrape data from webpages communicates with an instance of Fluentd over a Unix domain socket located in a shared volume. The pattern of using a third-party tool such as Fluentd to push data to a backing datastore not only simplifies the implementation of the custom tool, but also provides compatibility with any store that Fluentd chooses to support.
Kubernetes gives you some strong guarantees that the containers in your pod have a shared lifecycle. This means that when you launch a pod, you can be sure that each container will be scheduled to the same node; this is important because it means that you can depend on the fact that other containers in your pod will exist and will be local. Pods are often a convenient way to glue the functionality of several different containers together, enabling the reuse of common components. You might, for example, use a sidecar container to enhance the networking abilities of your application, or provide additional log management or monitoring facilities.