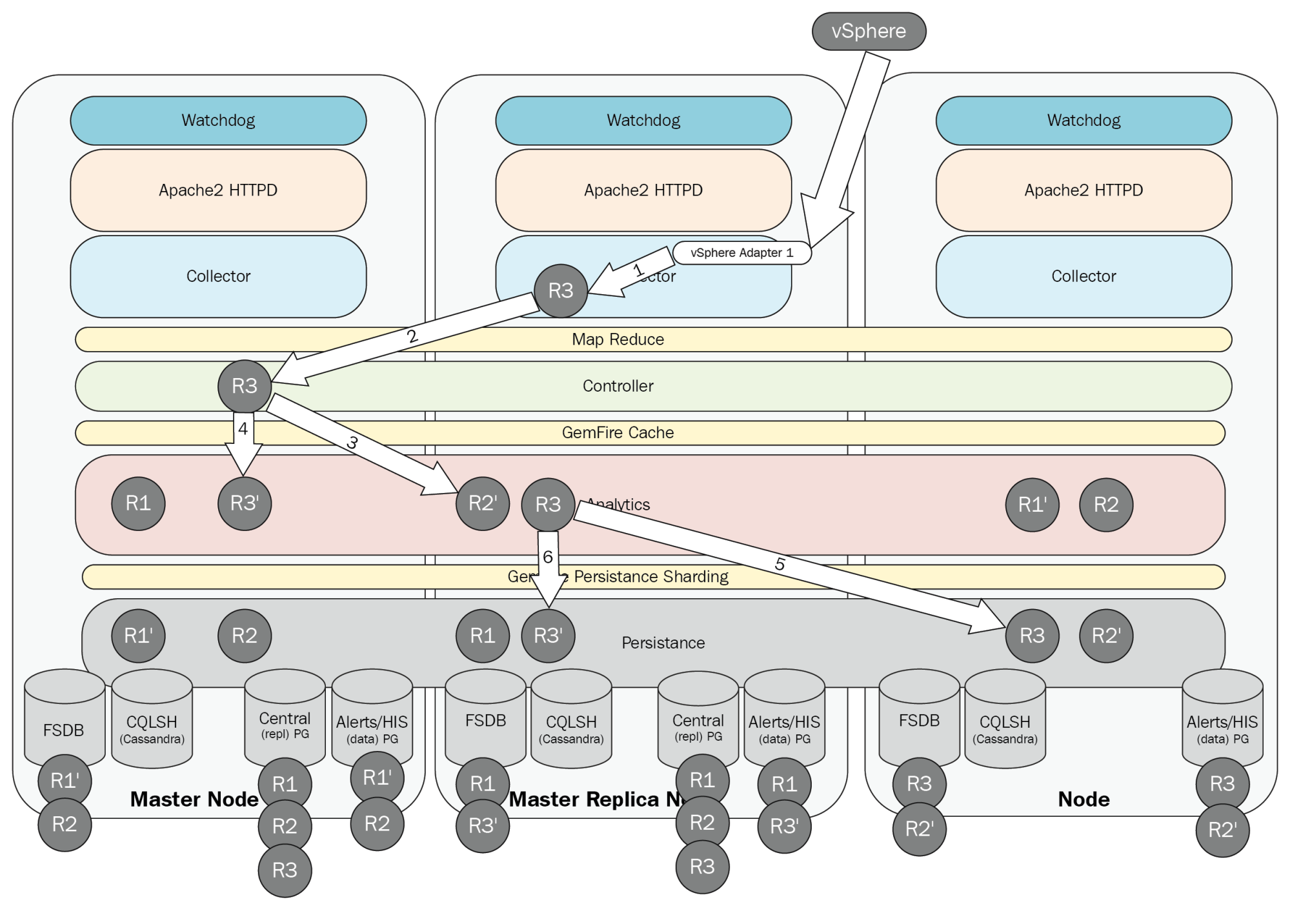
One of the features that came in vRealize Operations 6.0 was the ability to configure the cluster in an HA mode to prevent data loss. This still remains an impressive feature, used even today in vRealize Operations 6.6. Enabling HA makes two major changes to the Operations Manager cluster:
- The primary effect of HA is that all sharded data is duplicated by the Controller layer to a primary and backup copy in both the GemFire cache and GemFire Persistence layers.
- The secondary effect is that the master replica is created on a chosen data node for replication of the database. This node then takes over the role of the master node in the event that the original master fails.