

One of the most impressive new features that is available as part of vROps 6.0 is the ability to configure the cluster in a HA mode to prevent against data loss. Enabling HA makes two major changes to the Operations Manager cluster:
The primary effect of HA is that all the sharded data is duplicated by the controller layer to a primary and backup copy in both the GemFire cache and GemFire persistence layers.
The secondary effect is that the master replica is created on a chosen data node for xDB replication of Global xDB. This node is then taken over by the role of the master node in the event that the original master fails.
Although HA is an impressive new feature in vROps 6.0, from a design perspective, this is not a feature that should simply be enabled without proper consideration.
As mentioned earlier, both cache and persistence data is sharded per resource, not per metric or adapter. As such, when a data node is unavailable, not only can metrics not be viewed or used for analytics, but also new metrics for resources that are on effected nodes are discarded assuming that the adapter collector is operational or failed over. This fact alone would attract administrators to simply enable HA by default and it is easy to do so under vROps 6.0.
Although HA is very easy to enable, you must ensure that your cluster is sized appropriately to handle the increased load. As HA duplicates all data stored in both the GemFire cache and persistence layers, it essentially doubles the load on the system.
Tip
When designing your Operations Manager cluster, as a general rule, you will need to double the number of nodes if you are planning to enable HA. Detailed information on scaling vROps as well as the sizing calculator can be found in KB 2093783: vRealize Operations Manager Sizing Guidelines.
It is also important to consider that Operations Manager should not be deployed in a vSphere cluster where the number of vROps nodes is greater than the underlying vSphere cluster hosts. This is because there is little point enabling HA in Operations Manager if more than one node is residing on the same vSphere host at the same time.
As we just said, HA duplicates all incoming resource data so that two copies exist instead of one in both the GemFire cache and persistence layer. This is done by creating a secondary copy of each piece of data that is used in queries if the node hosting a primary copy is unavailable.
It is important to note that HA is simply creating a secondary copy of each piece of data, and as such, only one node failure can be sustained at a time (N-1) without data loss regardless of the cluster size. If a node is down, a new secondary shard of the data is not created unless the original node is removed from the cluster permanently.
When a failed node becomes available again, a node is placed into the recovery mode. During this time, data is synchronized with the other cluster members and when the synchronization is complete, the node is returned to the active status.
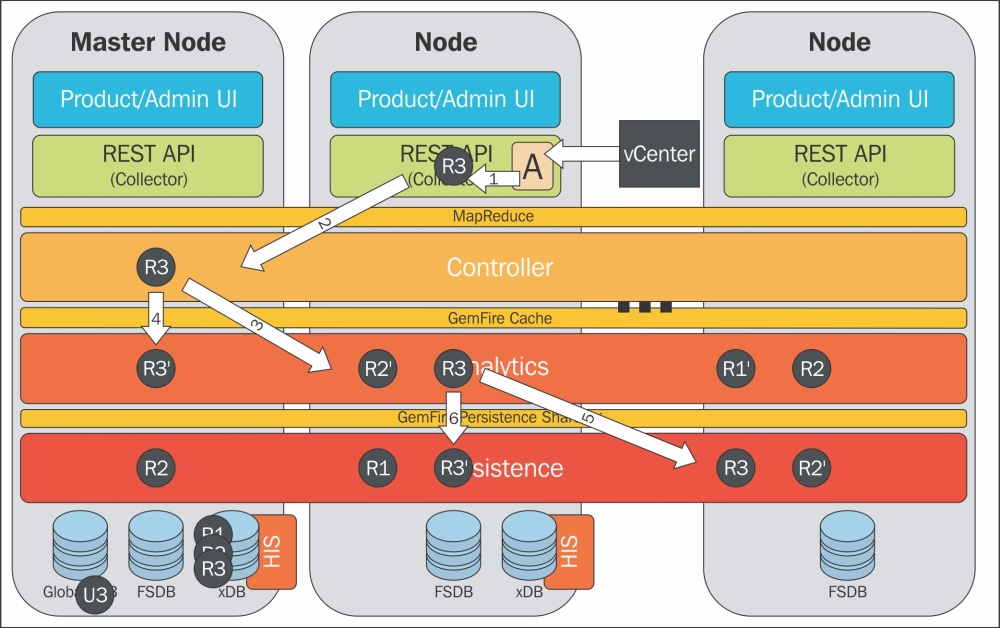
Let's run through this process using the preceding figure for an example of how the incoming data or the creation of a new object is handled in an HA configuration. In the preceding figure, R3 represents our new resource and R3' represents the secondary copy:
A running adapter instance receives data from vCenter as it is required to create a new resource for the new object, and a discovery task is created.
The discovery task is passed to the cluster. This task could be passed to any one node in the cluster and once it is assigned, that node is responsible for completing the task.
A new analytics item is created for the new object in the GemFire cache on any node in the cluster.
A secondary copy of the data is created on a different node to protect against failure.
The system then saves the data to the persistence layer. The object is created in the inventory (HIS) and its statistics are stored in the FSDB.
A secondary copy of the saved (GemFire persistence sharding) HIS and FSDB data is stored on a different node to protect against data loss.