

We call these patterns, design patterns. Design patterns is a massive topic with countless books, tutorials, and other resources. We spend our entire careers practicing, shaping, and perfecting the use of these patterns in practical ways. We give each pattern a name so that we can have smoother conversations with fellow programmers and also organize them better in our own minds.
To do all that, we will cover the following topics in this chapter:
Let's delve a little deeper into what a design pattern is before we dive into the specific patterns. As you may have begun to understand, there are unlimited ways to write a program that does even a simple thing. A design pattern is a solution to solve a recurrent and common problem. These problems are often so ubiquitous, that even if you don't use a pattern deliberately, you will almost certainly be using one or more patterns inadvertently; especially, if you are using third-party code.
Coupling is the degree to which individual code components depend on other components. We want to reduce the coupling in our code so that all our code components operate as independently as possible. We want to be able to look at them and understand each component on its own without needing a full understanding of the entire system. Low coupling also allows us to make changes to one component without drastically affecting the rest of the code.
Cohesion is a reference to how well different code components fit together. We want code components that can operate independently, but they should still fit together with other components in a cohesive and understandable way. This means that to have low coupling and high cohesion, we want code components that are designed to have a single purpose and a small interface to the rest of our code. This applies to every level of our code, from how the different sections of our app fit together, down to how functions interact with each other.
Both of these measurements have a high impact on our final measurement: complexity. Complexity is basically just how difficult it is to understand the code, especially when it comes to practical things like adding new features or fixing bugs. By having low coupling and high cohesion, we will generally be writing much less complex code. However, taken to their extremes, these principles can sometimes actually cause greater complexity. Sometimes the simplest solution is the quickest and most effective one because we don't want to get bogged down into architecting the perfect solution when we can implement a near perfect solution ten times faster. Most of us cannot afford to code on an unlimited budget.
Behavioral patterns are patterns that describe how objects will communicate with each other. In other words, it is how one object will send information to another object, even if that information is just that some event has occurred. They help to lower the code's coupling by providing a more detached communication mechanism that allows one object to send information to another, while having as little knowledge about the other object as possible. The less any type knows about the rest of the types in the code base, the less it will depend on those types. These behavior patterns also help to increase cohesion by providing straightforward and understandable ways to send the information.
The first behavioral pattern we will discuss is called the iterator pattern. We are starting with this one because we have actually already made use of this pattern in Chapter 6, Make Swift Work For You – Protocols and Generics. The idea of the iterator pattern is to provide a way to step through the contents of a container independent of the way the elements are represented inside the container.
As we saw, Swift provides us with the basics of this pattern with the GeneratorType and SequenceType protocols. It even implements those protocols for its array and dictionary containers. Even though we don't know how the elements are stored within an array or dictionary, we are still able to step through each value contained within them. Apple can easily change the way the elements are stored within them and it would not affect how we loop through the containers at all. This shows a great decoupling between our code and the container implementations.
If you remember, we were even able to create a generator for the infinite Fibonacci sequence:
struct FibonacciGenerator: GeneratorType {
typealias Element = Int
var values = (0, 1)
mutating func next() -> Element? {
self.values = (
self.values.1,
self.values.0 + self.values.1
)
return self.values.0
}
}The "container" doesn't even store any elements but we can still iterate through them as if it did.
The iterator pattern is a great introduction to how we make real world use of design patterns. Stepping through a list is such a common problem that Apple built the pattern directly into Swift.
The other behavioral pattern that we will discuss is called the observer pattern. The basic idea of this pattern is that you have one object that is designed to allow other objects to be notified when something occurs.
In Swift, the easiest way to achieve this is to provide a closure property on the object that you want to be observable and have that object call the closure whenever it wants to notify its observer. The property will be optional, so that any other object can set their closure on this property:
Now, any object can define its own closure on the callback and be notified whenever cash is withdrawn:
A notification center is a central object that manages events for other types. We can implement a notification center for ATM withdrawals:
With this implementation, any object can start observing by passing a unique key and callback to the addObserverForKey:callback: method. It doesn't have to have any reference to an instance of an ATM. An observer can also be removed by passing the same unique key to removeObserverForKey:. At any point, any object can trigger the notification by calling the trigger: method and all the registered observers will be notified.
behavioral pattern we will discuss is called the iterator pattern. We are starting with this one because we have actually already made use of this pattern in Chapter 6, Make Swift Work For You – Protocols and Generics. The idea of the iterator pattern is to provide a way to step through the contents of a container independent of the way the elements are represented inside the container.
As we saw, Swift provides us with the basics of this pattern with the GeneratorType and SequenceType protocols. It even implements those protocols for its array and dictionary containers. Even though we don't know how the elements are stored within an array or dictionary, we are still able to step through each value contained within them. Apple can easily change the way the elements are stored within them and it would not affect how we loop through the containers at all. This shows a great decoupling between our code and the container implementations.
If you remember, we were even able to create a generator for the infinite Fibonacci sequence:
struct FibonacciGenerator: GeneratorType {
typealias Element = Int
var values = (0, 1)
mutating func next() -> Element? {
self.values = (
self.values.1,
self.values.0 + self.values.1
)
return self.values.0
}
}The "container" doesn't even store any elements but we can still iterate through them as if it did.
The iterator pattern is a great introduction to how we make real world use of design patterns. Stepping through a list is such a common problem that Apple built the pattern directly into Swift.
The other behavioral pattern that we will discuss is called the observer pattern. The basic idea of this pattern is that you have one object that is designed to allow other objects to be notified when something occurs.
In Swift, the easiest way to achieve this is to provide a closure property on the object that you want to be observable and have that object call the closure whenever it wants to notify its observer. The property will be optional, so that any other object can set their closure on this property:
Now, any object can define its own closure on the callback and be notified whenever cash is withdrawn:
A notification center is a central object that manages events for other types. We can implement a notification center for ATM withdrawals:
With this implementation, any object can start observing by passing a unique key and callback to the addObserverForKey:callback: method. It doesn't have to have any reference to an instance of an ATM. An observer can also be removed by passing the same unique key to removeObserverForKey:. At any point, any object can trigger the notification by calling the trigger: method and all the registered observers will be notified.
behavioral pattern that we will discuss is called the observer pattern. The basic idea of this pattern is that you have one object that is designed to allow other objects to be notified when something occurs.
In Swift, the easiest way to achieve this is to provide a closure property on the object that you want to be observable and have that object call the closure whenever it wants to notify its observer. The property will be optional, so that any other object can set their closure on this property:
Now, any object can define its own closure on the callback and be notified whenever cash is withdrawn:
A notification center is a central object that manages events for other types. We can implement a notification center for ATM withdrawals:
With this implementation, any object can start observing by passing a unique key and callback to the addObserverForKey:callback: method. It doesn't have to have any reference to an instance of an ATM. An observer can also be removed by passing the same unique key to removeObserverForKey:. At any point, any object can trigger the notification by calling the trigger: method and all the registered observers will be notified.
Now, any object can define its own closure on the callback and be notified whenever cash is withdrawn:
A notification center is a central object that manages events for other types. We can implement a notification center for ATM withdrawals:
With this implementation, any object can start observing by passing a unique key and callback to the addObserverForKey:callback: method. It doesn't have to have any reference to an instance of an ATM. An observer can also be removed by passing the same unique key to removeObserverForKey:. At any point, any object can trigger the notification by calling the trigger: method and all the registered observers will be notified.
With this implementation, any object can start observing by passing a unique key and callback to the addObserverForKey:callback: method. It doesn't have to have any reference to an instance of an ATM. An observer can also be removed by passing the same unique key to removeObserverForKey:. At any point, any object can trigger the notification by calling the trigger: method and all the registered observers will be notified.
Structural patterns are patterns that describe how objects should relate to each other so that they can work together to achieve a common goal. They help us lower our coupling by suggesting an easy and clear way to break down a problem into related parts and they help raise our cohesion by giving us a predefined way that those components will fit together.
The first structural pattern we are going to look at is called the composite pattern. The concept of this pattern is that you have a single object that can be broken down into a collection of objects just like itself. This is like the organization of many large companies. They will have teams that are made up of smaller teams, which are then made up of even smaller teams. Each sub-team is responsible for a small part and they come together to be responsible for a larger part of the company.
A computer ultimately represents what is on the screen with a grid of pixel data. However, it does not make sense for every program to be concerned with each individual pixel. Instead, most programmers use frameworks, often provided by the operating system, to manipulate what is on the screen at a much higher level. A graphical program is usually given one or more windows to draw within and instead of drawing pixels within a window; a program will usually set up a series of "views". A view will have lots of different properties but they will most importantly have a position, size, and background color.
Let's look at our own implementation of a View class:
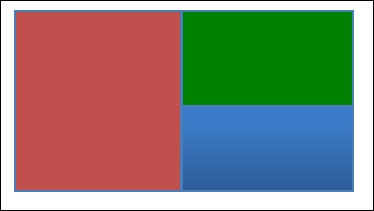
To produce this with our class, we could write a code similar to:
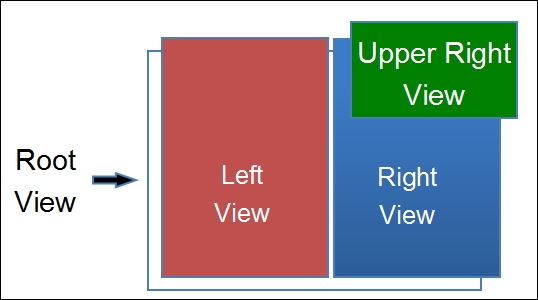
It is important to note that the position of upperRightView is left at 0, 0. That is because the positioning of all sub-views will always be relative to their immediate parent view. This allows us to pull any view out of the hierarchy without affecting any of its sub-views; drawing rightView within rootView will look exactly the same as if it were drawn on its own.
As you can see, the composite pattern is ideal for any situation where an object can be broken down into pieces that are just like it. This is great for something seemingly infinite like a hierarchy of views, but it is also a great alternative to subclassing. Subclassing is actually the tightest form of coupling. A subclass is extremely dependent on its superclass. Any change to a superclass is almost certainly going to affect all of its subclasses. We can often use the composite pattern as a less coupled alternative to subclassing.
As an example, let's explore the concept of representing a sentence. One way to look at the problem is to consider the sentence a special kind of string. Any kind of specialization like this will usually lead us to create a subclass; after all, a subclass is a specialization of its superclass. So we could create a Sentence subclass of String. This will be great because we can build strings using our sentence class and then pass them to methods that are expecting a normal string.
This is a much better alternative to subclassing in this scenario.
One of the most commonly used design patterns in Apple's frameworks is called the delegate pattern. The idea behind it is that you set up an object to let another object handle some of its responsibilities. In other words, one object will delegate some of its responsibilities to another object. This is like a manager hiring employees to do a job that the manager cannot or does not want to do themselves.
These protocols define only the methods necessary to allow the table view to properly function. This means that the delegate and dataSource properties can be any type as long as they implement the necessary methods. For example, one of the critical methods the data source must implement is tableView:numberOfRowsInSection:. This method provides the table view and an integer referring to the section that it wants to know about. It requires that an integer be returned for the number of rows in the referenced section. This is only one of multiple methods that data source must implement, but it gives you an idea of how the table view no longer has to figure out what data it contains. It simply asks the data source to figure it out.
This provides a very loosely coupled way to implement a specific table view and this same pattern is reused all over the programming world. You would be amazed at what Apple has been able to do with its table view, with very little to no pain inflicted on third party developers. The table view is incredibly optimized to handle thousands upon thousands of rows if you really wanted it to. The table has also changed a lot since the first developer kit for iOS, but these protocols have very rarely been changed except to add additional features.
Model view controller is one of the highest levels and most abstract design patterns. Variations of it are pervasive across a huge percentage of software, especially Apple's frameworks. It really can be considered the foundational pattern for how all of Apple's code is designed and therefore how most third party developers design their own code. The core concept of model view controller is that you split all of your types into three categories, often referred to as layers: model, view, and controller.
In the ideal implementation of model view controller, no model type should ever have any knowledge of the existence of a view type and no view type should know about a model type. Often, a model view controller is visualized sort of like a cake:
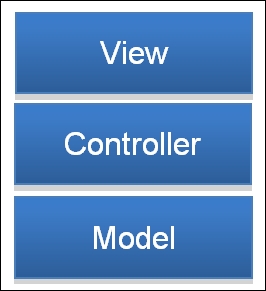
Another huge benefit of model view controller is that most components will be very reusable. You should be able to easily reuse views with different types of data like you can use a table view to display virtually any kind of data without changing the table view type and you should be able to display something like an address book in lots of different ways without changing the address book type.
As useful as this pattern is, it is also extremely hard to stick to. You will probably spend your entire development career evolving your sense for how to effectively breakdown your problems into these layers. It is often helpful to create explicit folders for each layer, forcing yourself to put every type into only one of the categories. You will also probably find yourself creating a bloated controller layer, especially in iOS, because it is often convenient to stick business logic there. More than any other design pattern, model view controller is probably the one that can be most described as something you strive for but rarely ever perfectly achieve.
first structural pattern we are going to look at is called the composite pattern. The concept of this pattern is that you have a single object that can be broken down into a collection of objects just like itself. This is like the organization of many large companies. They will have teams that are made up of smaller teams, which are then made up of even smaller teams. Each sub-team is responsible for a small part and they come together to be responsible for a larger part of the company.
A computer ultimately represents what is on the screen with a grid of pixel data. However, it does not make sense for every program to be concerned with each individual pixel. Instead, most programmers use frameworks, often provided by the operating system, to manipulate what is on the screen at a much higher level. A graphical program is usually given one or more windows to draw within and instead of drawing pixels within a window; a program will usually set up a series of "views". A view will have lots of different properties but they will most importantly have a position, size, and background color.
Let's look at our own implementation of a View class:
To produce this with our class, we could write a code similar to:
It is important to note that the position of upperRightView is left at 0, 0. That is because the positioning of all sub-views will always be relative to their immediate parent view. This allows us to pull any view out of the hierarchy without affecting any of its sub-views; drawing rightView within rootView will look exactly the same as if it were drawn on its own.
As you can see, the composite pattern is ideal for any situation where an object can be broken down into pieces that are just like it. This is great for something seemingly infinite like a hierarchy of views, but it is also a great alternative to subclassing. Subclassing is actually the tightest form of coupling. A subclass is extremely dependent on its superclass. Any change to a superclass is almost certainly going to affect all of its subclasses. We can often use the composite pattern as a less coupled alternative to subclassing.
As an example, let's explore the concept of representing a sentence. One way to look at the problem is to consider the sentence a special kind of string. Any kind of specialization like this will usually lead us to create a subclass; after all, a subclass is a specialization of its superclass. So we could create a Sentence subclass of String. This will be great because we can build strings using our sentence class and then pass them to methods that are expecting a normal string.
This is a much better alternative to subclassing in this scenario.
One of the most commonly used design patterns in Apple's frameworks is called the delegate pattern. The idea behind it is that you set up an object to let another object handle some of its responsibilities. In other words, one object will delegate some of its responsibilities to another object. This is like a manager hiring employees to do a job that the manager cannot or does not want to do themselves.
These protocols define only the methods necessary to allow the table view to properly function. This means that the delegate and dataSource properties can be any type as long as they implement the necessary methods. For example, one of the critical methods the data source must implement is tableView:numberOfRowsInSection:. This method provides the table view and an integer referring to the section that it wants to know about. It requires that an integer be returned for the number of rows in the referenced section. This is only one of multiple methods that data source must implement, but it gives you an idea of how the table view no longer has to figure out what data it contains. It simply asks the data source to figure it out.
This provides a very loosely coupled way to implement a specific table view and this same pattern is reused all over the programming world. You would be amazed at what Apple has been able to do with its table view, with very little to no pain inflicted on third party developers. The table view is incredibly optimized to handle thousands upon thousands of rows if you really wanted it to. The table has also changed a lot since the first developer kit for iOS, but these protocols have very rarely been changed except to add additional features.
Model view controller is one of the highest levels and most abstract design patterns. Variations of it are pervasive across a huge percentage of software, especially Apple's frameworks. It really can be considered the foundational pattern for how all of Apple's code is designed and therefore how most third party developers design their own code. The core concept of model view controller is that you split all of your types into three categories, often referred to as layers: model, view, and controller.
In the ideal implementation of model view controller, no model type should ever have any knowledge of the existence of a view type and no view type should know about a model type. Often, a model view controller is visualized sort of like a cake:
Another huge benefit of model view controller is that most components will be very reusable. You should be able to easily reuse views with different types of data like you can use a table view to display virtually any kind of data without changing the table view type and you should be able to display something like an address book in lots of different ways without changing the address book type.
As useful as this pattern is, it is also extremely hard to stick to. You will probably spend your entire development career evolving your sense for how to effectively breakdown your problems into these layers. It is often helpful to create explicit folders for each layer, forcing yourself to put every type into only one of the categories. You will also probably find yourself creating a bloated controller layer, especially in iOS, because it is often convenient to stick business logic there. More than any other design pattern, model view controller is probably the one that can be most described as something you strive for but rarely ever perfectly achieve.
Let's look at our own implementation of a View class:
To produce this with our class, we could write a code similar to:
It is important to note that the position of upperRightView is left at 0, 0. That is because the positioning of all sub-views will always be relative to their immediate parent view. This allows us to pull any view out of the hierarchy without affecting any of its sub-views; drawing rightView within rootView will look exactly the same as if it were drawn on its own.
As you can see, the composite pattern is ideal for any situation where an object can be broken down into pieces that are just like it. This is great for something seemingly infinite like a hierarchy of views, but it is also a great alternative to subclassing. Subclassing is actually the tightest form of coupling. A subclass is extremely dependent on its superclass. Any change to a superclass is almost certainly going to affect all of its subclasses. We can often use the composite pattern as a less coupled alternative to subclassing.
As an example, let's explore the concept of representing a sentence. One way to look at the problem is to consider the sentence a special kind of string. Any kind of specialization like this will usually lead us to create a subclass; after all, a subclass is a specialization of its superclass. So we could create a Sentence subclass of String. This will be great because we can build strings using our sentence class and then pass them to methods that are expecting a normal string.
This is a much better alternative to subclassing in this scenario.
One of the most commonly used design patterns in Apple's frameworks is called the delegate pattern. The idea behind it is that you set up an object to let another object handle some of its responsibilities. In other words, one object will delegate some of its responsibilities to another object. This is like a manager hiring employees to do a job that the manager cannot or does not want to do themselves.
These protocols define only the methods necessary to allow the table view to properly function. This means that the delegate and dataSource properties can be any type as long as they implement the necessary methods. For example, one of the critical methods the data source must implement is tableView:numberOfRowsInSection:. This method provides the table view and an integer referring to the section that it wants to know about. It requires that an integer be returned for the number of rows in the referenced section. This is only one of multiple methods that data source must implement, but it gives you an idea of how the table view no longer has to figure out what data it contains. It simply asks the data source to figure it out.
This provides a very loosely coupled way to implement a specific table view and this same pattern is reused all over the programming world. You would be amazed at what Apple has been able to do with its table view, with very little to no pain inflicted on third party developers. The table view is incredibly optimized to handle thousands upon thousands of rows if you really wanted it to. The table has also changed a lot since the first developer kit for iOS, but these protocols have very rarely been changed except to add additional features.
Model view controller is one of the highest levels and most abstract design patterns. Variations of it are pervasive across a huge percentage of software, especially Apple's frameworks. It really can be considered the foundational pattern for how all of Apple's code is designed and therefore how most third party developers design their own code. The core concept of model view controller is that you split all of your types into three categories, often referred to as layers: model, view, and controller.
In the ideal implementation of model view controller, no model type should ever have any knowledge of the existence of a view type and no view type should know about a model type. Often, a model view controller is visualized sort of like a cake:
Another huge benefit of model view controller is that most components will be very reusable. You should be able to easily reuse views with different types of data like you can use a table view to display virtually any kind of data without changing the table view type and you should be able to display something like an address book in lots of different ways without changing the address book type.
As useful as this pattern is, it is also extremely hard to stick to. You will probably spend your entire development career evolving your sense for how to effectively breakdown your problems into these layers. It is often helpful to create explicit folders for each layer, forcing yourself to put every type into only one of the categories. You will also probably find yourself creating a bloated controller layer, especially in iOS, because it is often convenient to stick business logic there. More than any other design pattern, model view controller is probably the one that can be most described as something you strive for but rarely ever perfectly achieve.
As an example, let's explore the concept of representing a sentence. One way to look at the problem is to consider the sentence a special kind of string. Any kind of specialization like this will usually lead us to create a subclass; after all, a subclass is a specialization of its superclass. So we could create a Sentence subclass of String. This will be great because we can build strings using our sentence class and then pass them to methods that are expecting a normal string.
This is a much better alternative to subclassing in this scenario.
One of the most commonly used design patterns in Apple's frameworks is called the delegate pattern. The idea behind it is that you set up an object to let another object handle some of its responsibilities. In other words, one object will delegate some of its responsibilities to another object. This is like a manager hiring employees to do a job that the manager cannot or does not want to do themselves.
These protocols define only the methods necessary to allow the table view to properly function. This means that the delegate and dataSource properties can be any type as long as they implement the necessary methods. For example, one of the critical methods the data source must implement is tableView:numberOfRowsInSection:. This method provides the table view and an integer referring to the section that it wants to know about. It requires that an integer be returned for the number of rows in the referenced section. This is only one of multiple methods that data source must implement, but it gives you an idea of how the table view no longer has to figure out what data it contains. It simply asks the data source to figure it out.
This provides a very loosely coupled way to implement a specific table view and this same pattern is reused all over the programming world. You would be amazed at what Apple has been able to do with its table view, with very little to no pain inflicted on third party developers. The table view is incredibly optimized to handle thousands upon thousands of rows if you really wanted it to. The table has also changed a lot since the first developer kit for iOS, but these protocols have very rarely been changed except to add additional features.
Model view controller is one of the highest levels and most abstract design patterns. Variations of it are pervasive across a huge percentage of software, especially Apple's frameworks. It really can be considered the foundational pattern for how all of Apple's code is designed and therefore how most third party developers design their own code. The core concept of model view controller is that you split all of your types into three categories, often referred to as layers: model, view, and controller.
In the ideal implementation of model view controller, no model type should ever have any knowledge of the existence of a view type and no view type should know about a model type. Often, a model view controller is visualized sort of like a cake:
Another huge benefit of model view controller is that most components will be very reusable. You should be able to easily reuse views with different types of data like you can use a table view to display virtually any kind of data without changing the table view type and you should be able to display something like an address book in lots of different ways without changing the address book type.
As useful as this pattern is, it is also extremely hard to stick to. You will probably spend your entire development career evolving your sense for how to effectively breakdown your problems into these layers. It is often helpful to create explicit folders for each layer, forcing yourself to put every type into only one of the categories. You will also probably find yourself creating a bloated controller layer, especially in iOS, because it is often convenient to stick business logic there. More than any other design pattern, model view controller is probably the one that can be most described as something you strive for but rarely ever perfectly achieve.
commonly used design patterns in Apple's frameworks is called the delegate pattern. The idea behind it is that you set up an object to let another object handle some of its responsibilities. In other words, one object will delegate some of its responsibilities to another object. This is like a manager hiring employees to do a job that the manager cannot or does not want to do themselves.
These protocols define only the methods necessary to allow the table view to properly function. This means that the delegate and dataSource properties can be any type as long as they implement the necessary methods. For example, one of the critical methods the data source must implement is tableView:numberOfRowsInSection:. This method provides the table view and an integer referring to the section that it wants to know about. It requires that an integer be returned for the number of rows in the referenced section. This is only one of multiple methods that data source must implement, but it gives you an idea of how the table view no longer has to figure out what data it contains. It simply asks the data source to figure it out.
This provides a very loosely coupled way to implement a specific table view and this same pattern is reused all over the programming world. You would be amazed at what Apple has been able to do with its table view, with very little to no pain inflicted on third party developers. The table view is incredibly optimized to handle thousands upon thousands of rows if you really wanted it to. The table has also changed a lot since the first developer kit for iOS, but these protocols have very rarely been changed except to add additional features.
Model view controller is one of the highest levels and most abstract design patterns. Variations of it are pervasive across a huge percentage of software, especially Apple's frameworks. It really can be considered the foundational pattern for how all of Apple's code is designed and therefore how most third party developers design their own code. The core concept of model view controller is that you split all of your types into three categories, often referred to as layers: model, view, and controller.
In the ideal implementation of model view controller, no model type should ever have any knowledge of the existence of a view type and no view type should know about a model type. Often, a model view controller is visualized sort of like a cake:
Another huge benefit of model view controller is that most components will be very reusable. You should be able to easily reuse views with different types of data like you can use a table view to display virtually any kind of data without changing the table view type and you should be able to display something like an address book in lots of different ways without changing the address book type.
As useful as this pattern is, it is also extremely hard to stick to. You will probably spend your entire development career evolving your sense for how to effectively breakdown your problems into these layers. It is often helpful to create explicit folders for each layer, forcing yourself to put every type into only one of the categories. You will also probably find yourself creating a bloated controller layer, especially in iOS, because it is often convenient to stick business logic there. More than any other design pattern, model view controller is probably the one that can be most described as something you strive for but rarely ever perfectly achieve.
of the highest levels and most abstract design patterns. Variations of it are pervasive across a huge percentage of software, especially Apple's frameworks. It really can be considered the foundational pattern for how all of Apple's code is designed and therefore how most third party developers design their own code. The core concept of model view controller is that you split all of your types into three categories, often referred to as layers: model, view, and controller.
In the ideal implementation of model view controller, no model type should ever have any knowledge of the existence of a view type and no view type should know about a model type. Often, a model view controller is visualized sort of like a cake:
Another huge benefit of model view controller is that most components will be very reusable. You should be able to easily reuse views with different types of data like you can use a table view to display virtually any kind of data without changing the table view type and you should be able to display something like an address book in lots of different ways without changing the address book type.
As useful as this pattern is, it is also extremely hard to stick to. You will probably spend your entire development career evolving your sense for how to effectively breakdown your problems into these layers. It is often helpful to create explicit folders for each layer, forcing yourself to put every type into only one of the categories. You will also probably find yourself creating a bloated controller layer, especially in iOS, because it is often convenient to stick business logic there. More than any other design pattern, model view controller is probably the one that can be most described as something you strive for but rarely ever perfectly achieve.
The final type of design patterns we will discuss is called creational patterns. These patterns relate to the initialization of new objects. At first, the initialization of an object probably seems simple and not a very important place to have design patterns. After all, we already have initializers. However, in certain circumstances, creational patterns can be extremely helpful.
The first patterns we will discuss are the singleton and shared instance patterns. We are discussing them together because they are extremely similar. First we will discuss shared instance, because it is the less strict form of the singleton pattern.
The idea of the shared instance pattern is that you provide an instance of your class to be used by other parts of your code. Let's look at a quick example of this in Swift:
Now, the different thing about the singleton pattern is that you would write your code in such a way that it is not even possible to create a second instance of your class. Even though our preceding address book class provides a shared instance, there is nothing to stop someone from creating their own instance using the normal initializers. We could pretty easily change our address book class to a singleton instead of a shared instance, as shown:
Using these patterns can also create hidden dependencies. Usually, it is pretty clear what dependencies an instance has based on what it must be initialized with, but a singleton or shared instance does not get passed into the initializer, so it can often go unnoticed as a dependency. Even though there is some initial extra overhead to passing an object into an initializer, it will often reduce the coupling and maintain a clearer picture of how your types interact. The bottom line is, like with any other pattern, think carefully about each use of the singleton and shared instance patterns and be sure it is the best tool for the job.
The final pattern we will discuss here is called abstract factory. It is based on a simpler pattern called factory. The idea of a factory pattern is that you implement an object for creating other objects, much like you would create a factory for assembling cars. The factory pattern is great when the initializing of a type is very complex or you want to create a bunch of similar objects. Let's take a look at the second scenario. What if we were creating a two-player ping-pong game and we had some scenario in the game where we would add additional balls that a specific player needed to keep in play? The ball class might look something like this:
Now, we could pass this factory into whatever object is responsible for handling the ball creation event and that object is no longer responsible for determining the color of the ball or any other properties we might want. This is great for reducing the number of responsibilities that object has and also keeps the code very flexible to add additional ball properties in the future without having to change the ball creation event object.
An abstract factory is a special form of factory where the instances the factory creates may be one of many subclasses of a single other class. A great example of this would be an image creation factory. As we discussed in Chapter 3, One Piece at a Time – Types, Scopes, and Projects, computers have an enormous number of ways to represent images. In that chapter we hypothesized having a superclass called just "Image" that would have a subclass for each type of image. This would help us write classes to handle any type of image very easily by always having them work with the image superclass. Similarly, we could create an image factory that would virtually eliminate any need for an external type to know anything about the different types of images. We could design an abstract factory that takes the path to any image, loads the image into the appropriate subclass, and returns it simply as the image superclass. Now, neither the code that loads an image, nor the code that uses the image, needs to know what type of image they are dealing with. All of the complexity of different image representations is abstracted away inside the factory and the image class hierarchy. This is a huge win for making our code easier to understand and more maintainable.
The idea of the shared instance pattern is that you provide an instance of your class to be used by other parts of your code. Let's look at a quick example of this in Swift:
Now, the different thing about the singleton pattern is that you would write your code in such a way that it is not even possible to create a second instance of your class. Even though our preceding address book class provides a shared instance, there is nothing to stop someone from creating their own instance using the normal initializers. We could pretty easily change our address book class to a singleton instead of a shared instance, as shown:
Using these patterns can also create hidden dependencies. Usually, it is pretty clear what dependencies an instance has based on what it must be initialized with, but a singleton or shared instance does not get passed into the initializer, so it can often go unnoticed as a dependency. Even though there is some initial extra overhead to passing an object into an initializer, it will often reduce the coupling and maintain a clearer picture of how your types interact. The bottom line is, like with any other pattern, think carefully about each use of the singleton and shared instance patterns and be sure it is the best tool for the job.
The final pattern we will discuss here is called abstract factory. It is based on a simpler pattern called factory. The idea of a factory pattern is that you implement an object for creating other objects, much like you would create a factory for assembling cars. The factory pattern is great when the initializing of a type is very complex or you want to create a bunch of similar objects. Let's take a look at the second scenario. What if we were creating a two-player ping-pong game and we had some scenario in the game where we would add additional balls that a specific player needed to keep in play? The ball class might look something like this:
Now, we could pass this factory into whatever object is responsible for handling the ball creation event and that object is no longer responsible for determining the color of the ball or any other properties we might want. This is great for reducing the number of responsibilities that object has and also keeps the code very flexible to add additional ball properties in the future without having to change the ball creation event object.
An abstract factory is a special form of factory where the instances the factory creates may be one of many subclasses of a single other class. A great example of this would be an image creation factory. As we discussed in Chapter 3, One Piece at a Time – Types, Scopes, and Projects, computers have an enormous number of ways to represent images. In that chapter we hypothesized having a superclass called just "Image" that would have a subclass for each type of image. This would help us write classes to handle any type of image very easily by always having them work with the image superclass. Similarly, we could create an image factory that would virtually eliminate any need for an external type to know anything about the different types of images. We could design an abstract factory that takes the path to any image, loads the image into the appropriate subclass, and returns it simply as the image superclass. Now, neither the code that loads an image, nor the code that uses the image, needs to know what type of image they are dealing with. All of the complexity of different image representations is abstracted away inside the factory and the image class hierarchy. This is a huge win for making our code easier to understand and more maintainable.
pattern we will discuss here is called abstract factory. It is based on a simpler pattern called factory. The idea of a factory pattern is that you implement an object for creating other objects, much like you would create a factory for assembling cars. The factory pattern is great when the initializing of a type is very complex or you want to create a bunch of similar objects. Let's take a look at the second scenario. What if we were creating a two-player ping-pong game and we had some scenario in the game where we would add additional balls that a specific player needed to keep in play? The ball class might look something like this:
Now, we could pass this factory into whatever object is responsible for handling the ball creation event and that object is no longer responsible for determining the color of the ball or any other properties we might want. This is great for reducing the number of responsibilities that object has and also keeps the code very flexible to add additional ball properties in the future without having to change the ball creation event object.
An abstract factory is a special form of factory where the instances the factory creates may be one of many subclasses of a single other class. A great example of this would be an image creation factory. As we discussed in Chapter 3, One Piece at a Time – Types, Scopes, and Projects, computers have an enormous number of ways to represent images. In that chapter we hypothesized having a superclass called just "Image" that would have a subclass for each type of image. This would help us write classes to handle any type of image very easily by always having them work with the image superclass. Similarly, we could create an image factory that would virtually eliminate any need for an external type to know anything about the different types of images. We could design an abstract factory that takes the path to any image, loads the image into the appropriate subclass, and returns it simply as the image superclass. Now, neither the code that loads an image, nor the code that uses the image, needs to know what type of image they are dealing with. All of the complexity of different image representations is abstracted away inside the factory and the image class hierarchy. This is a huge win for making our code easier to understand and more maintainable.
Good programming is about more than just grand, universal concepts of how to write effective code. The best programmers know how to play to the strengths of the tools at hand. We are now going to move from looking at the core tenants of programming design to some of the gritty details of enhancing your code with the power of Swift.
The first thing we will look at is making effective use of the associated value of an enumeration. Associated values are a pretty unique feature of Swift, so they open up some pretty interesting possibilities.
We have already seen in Chapter 3, One Piece at a Time – Types, Scopes, and Projects that we can use an enumeration with associated values to represent a measurement like distance in multiple measurement systems:
enum Height {
case Imperial(feet: Int, Inches: Double)
case Metric(meters: Double)
case Other(String)
}We can generalize this use case as using an enumeration to flatten out a simple class hierarchy. Instead of the enumeration, we could have created a height superclass or protocol with subclasses for each measurement system. However, this would be a more complex solution and we would lose the benefits of using a value type instead of a reference type. The enumeration solution is also very compact, making it very easy to understand at a glance instead of having to analyze how multiple different classes fit together.
Let's look at an even more complex example. Let's say we want to create a fitness app and we want to be able to track multiple types of workouts. Sometimes people workout to do a certain number of repetitions of various movements; other times they are just going for a certain amount of time. We could create a class hierarchy for this, but an enumeration with associated values works great:
enum Workout {
case ForTime(seconds: Int)
case ForReps(movements: [(name: String, reps: Int)])
}Now, when we want to create a workout, we only need to define values relevant to the type of workout we are interested in without having to use any classes at all.
Another great use of enumerations with associated values is to represent the state of something. The simplest example of this would be a result enumeration that can either contain a value or an error description if an error occurs:
This allows us to write a function that can fail and give a reason that it failed:
have already seen in Chapter 3, One Piece at a Time – Types, Scopes, and Projects that we can use an enumeration with associated values to represent a measurement like distance in multiple measurement systems:
enum Height {
case Imperial(feet: Int, Inches: Double)
case Metric(meters: Double)
case Other(String)
}We can generalize this use case as using an enumeration to flatten out a simple class hierarchy. Instead of the enumeration, we could have created a height superclass or protocol with subclasses for each measurement system. However, this would be a more complex solution and we would lose the benefits of using a value type instead of a reference type. The enumeration solution is also very compact, making it very easy to understand at a glance instead of having to analyze how multiple different classes fit together.
Let's look at an even more complex example. Let's say we want to create a fitness app and we want to be able to track multiple types of workouts. Sometimes people workout to do a certain number of repetitions of various movements; other times they are just going for a certain amount of time. We could create a class hierarchy for this, but an enumeration with associated values works great:
enum Workout {
case ForTime(seconds: Int)
case ForReps(movements: [(name: String, reps: Int)])
}Now, when we want to create a workout, we only need to define values relevant to the type of workout we are interested in without having to use any classes at all.
Another great use of enumerations with associated values is to represent the state of something. The simplest example of this would be a result enumeration that can either contain a value or an error description if an error occurs:
This allows us to write a function that can fail and give a reason that it failed:
Another powerful feature that we briefly covered in Chapter 3, One Piece at a Time – Types, Scopes, and Projects is the ability to extend existing types. We saw that we could add an extension to the string type that would allow us to repeat the string multiple times. Let's look at a more practical use case for this and discuss its benefits in terms of improving our code.
Perhaps we are creating a grade-tracking program where we are going to be printing out a lot of percentages. A great way to represent percentages is by using a float with a value between zero and one. Floats are great for percentages because we can use the built-in math functions and they can represent pretty granular numbers. The hurdle to cross when using a float to represent a percentage is printing it out. If we simply print out the value, it will most likely not be formatted the way we would want. People prefer percentages to be out of 100 and have a percent symbol after it.
One feature we have not yet discussed is the concept of lazy properties. Marking a property as lazy allows Swift to wait to initialize it until the first time it is accessed. This can be useful in at least a few important ways.
The most obvious way to use lazy properties is to avoid unnecessary memory usage. Let's look at a very simple example first:
An alternative to using lazy properties to achieve our goals above would be to use optional properties instead and simply assign those values later as needed. This is an OK solution, especially if our only goal is to reduce unnecessary memory usage or processing. However, there is one other great benefit to the lazy property solution. It produces more legible code by connecting the logic to calculate a property's value right by its definition. If we simply had an optional property it would have to be initialized in either an initializer or by some other method. It would not be immediately clear when looking at the property what its value will be and when it will be set, if it will be set at all.
This is a critically important advantage as your code base grows in size and age. It is very easy to get lost in a code base, even if it is your own. The more straight lines you can draw from one piece of logic to another, the easier it will be able to find the logic you are looking for when you come back to your code base later.
An alternative to using lazy properties to achieve our goals above would be to use optional properties instead and simply assign those values later as needed. This is an OK solution, especially if our only goal is to reduce unnecessary memory usage or processing. However, there is one other great benefit to the lazy property solution. It produces more legible code by connecting the logic to calculate a property's value right by its definition. If we simply had an optional property it would have to be initialized in either an initializer or by some other method. It would not be immediately clear when looking at the property what its value will be and when it will be set, if it will be set at all.
This is a critically important advantage as your code base grows in size and age. It is very easy to get lost in a code base, even if it is your own. The more straight lines you can draw from one piece of logic to another, the easier it will be able to find the logic you are looking for when you come back to your code base later.
An alternative to using lazy properties to achieve our goals above would be to use optional properties instead and simply assign those values later as needed. This is an OK solution, especially if our only goal is to reduce unnecessary memory usage or processing. However, there is one other great benefit to the lazy property solution. It produces more legible code by connecting the logic to calculate a property's value right by its definition. If we simply had an optional property it would have to be initialized in either an initializer or by some other method. It would not be immediately clear when looking at the property what its value will be and when it will be set, if it will be set at all.
This is a critically important advantage as your code base grows in size and age. It is very easy to get lost in a code base, even if it is your own. The more straight lines you can draw from one piece of logic to another, the easier it will be able to find the logic you are looking for when you come back to your code base later.
This is a critically important advantage as your code base grows in size and age. It is very easy to get lost in a code base, even if it is your own. The more straight lines you can draw from one piece of logic to another, the easier it will be able to find the logic you are looking for when you come back to your code base later.