In this section, we'll cover the why behind Node.js. Why is it so good at creating backend apps? And why is it becoming so popular with companies such as Netflix, Uber and Walmart, who are all using Node.js in production?
As you might have noticed since you're taking this course, when people want to learn a new backend language, more and more they're turning to Node as the language they want to learn. The Node skillset is in hot demand, for both frontend developers who need to use Node day to day to do things such as compile their applications, to engineers who are creating applications and utilities using Node.js. All of this has made Node the backend language of choice.
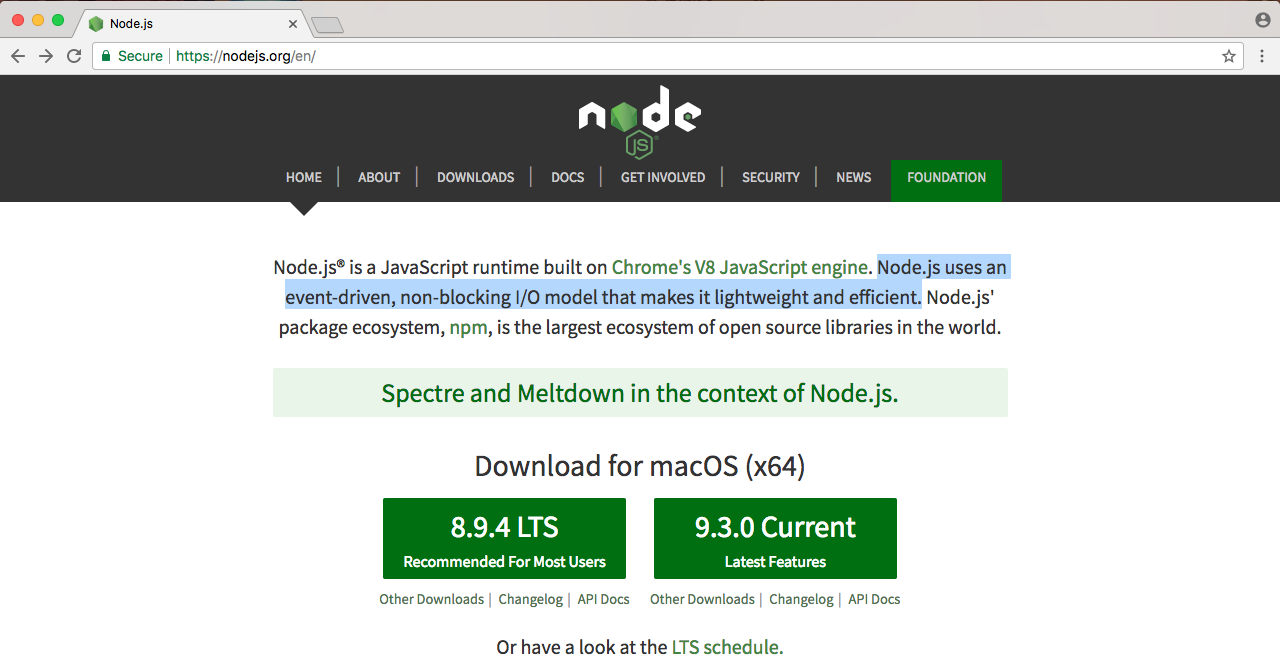
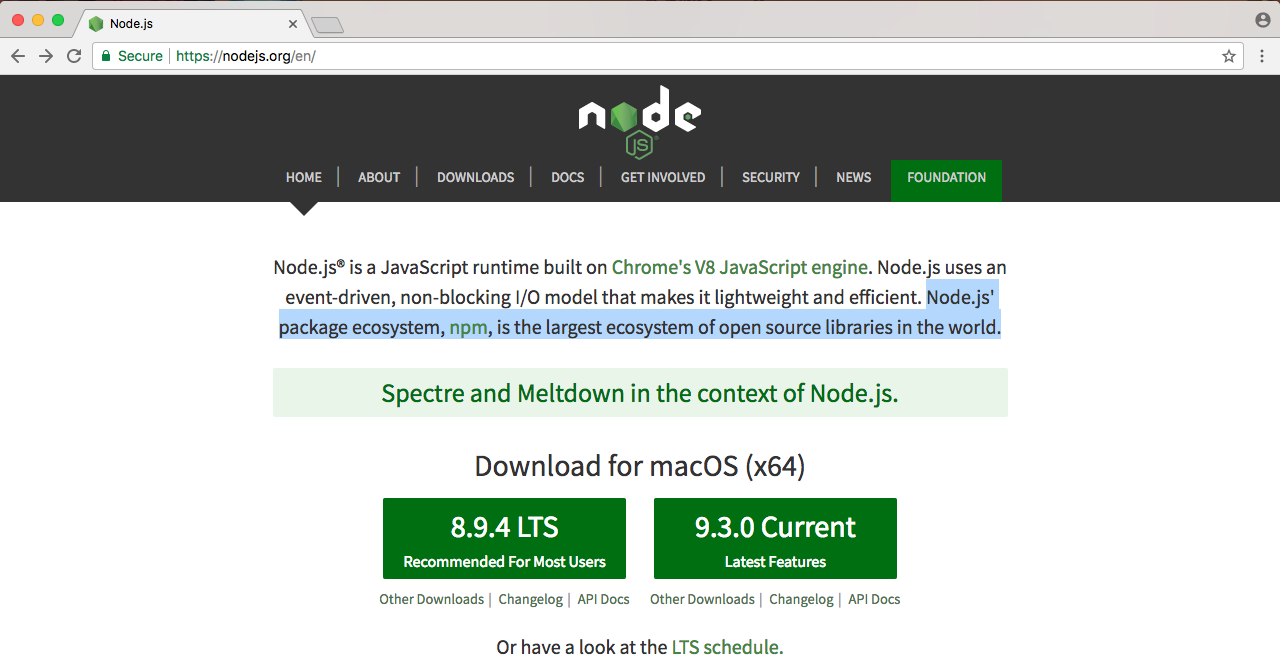
Now, if we look at the homepage of Node, we have three sentences, as shown in the following screenshot:
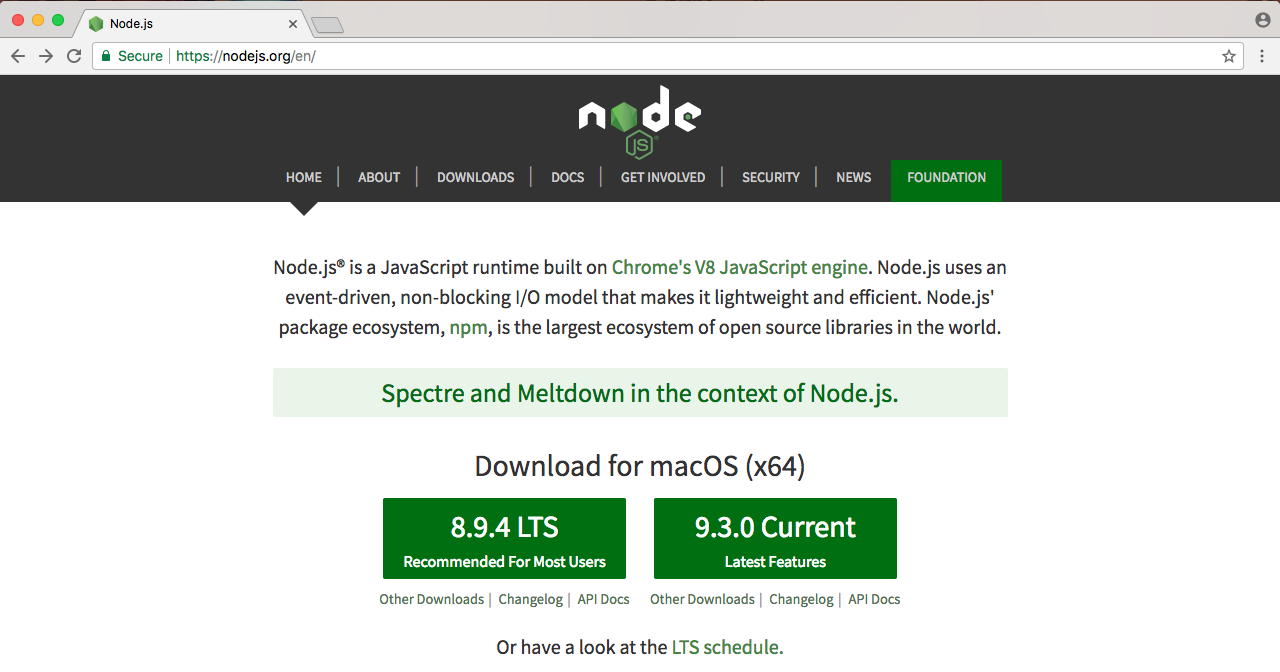
In the previous section, we addressed the first sentence. We took a look at what Node.js is. There's only three sentences in the image, so in this section, we'll take a look at the second two sentences. We'll read them now, then we'll break it down, learning exactly why Node is so great.
The first sentence, Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient; we'll explore all of this now. The second sentence we'll explore at the end of the section—Node.js' packaged ecosystem, npm, is the largest ecosystem of open source libraries in the world. Now, these two sentences have a ton of information packed into them.
We'll go over a few code examples, we'll dive into some charts and graphs, and we'll explore what makes Node different and what makes it so great.
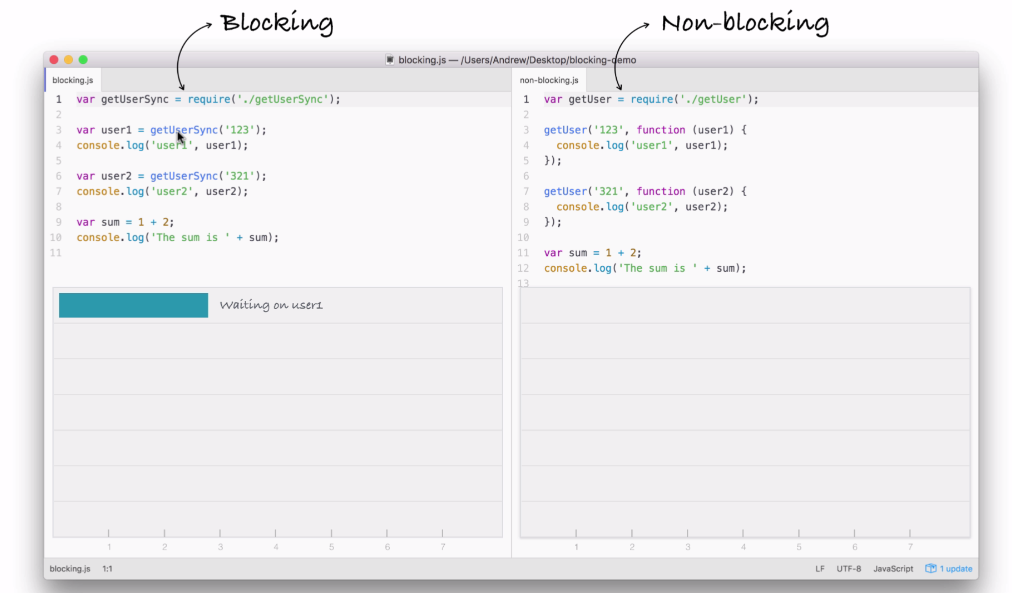
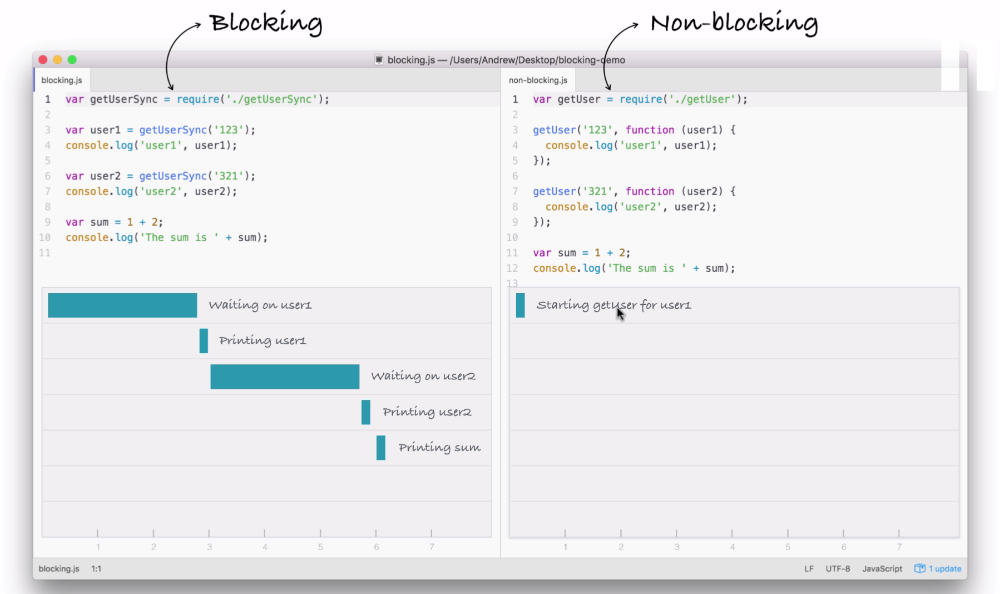
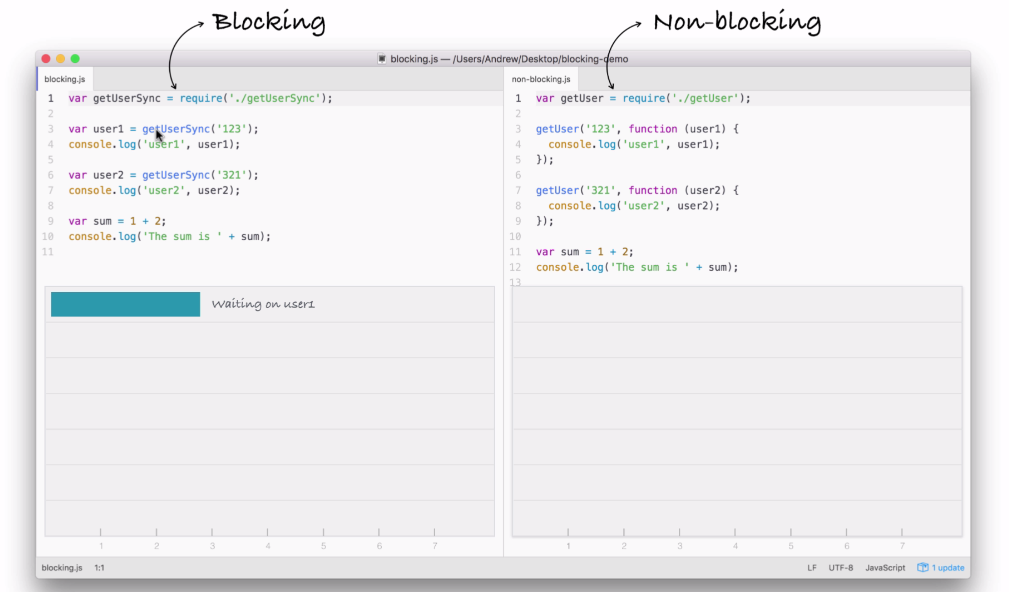
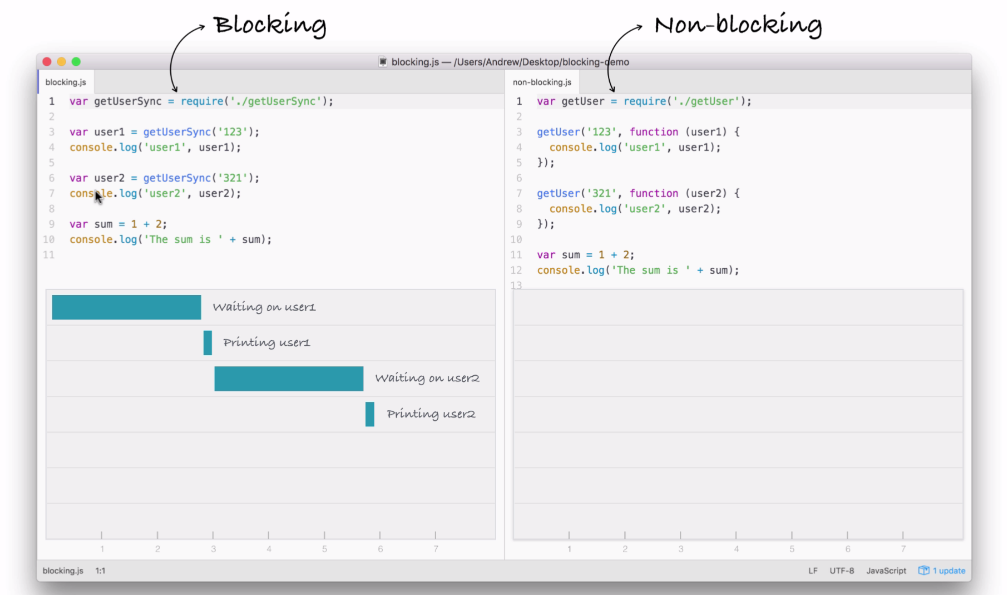
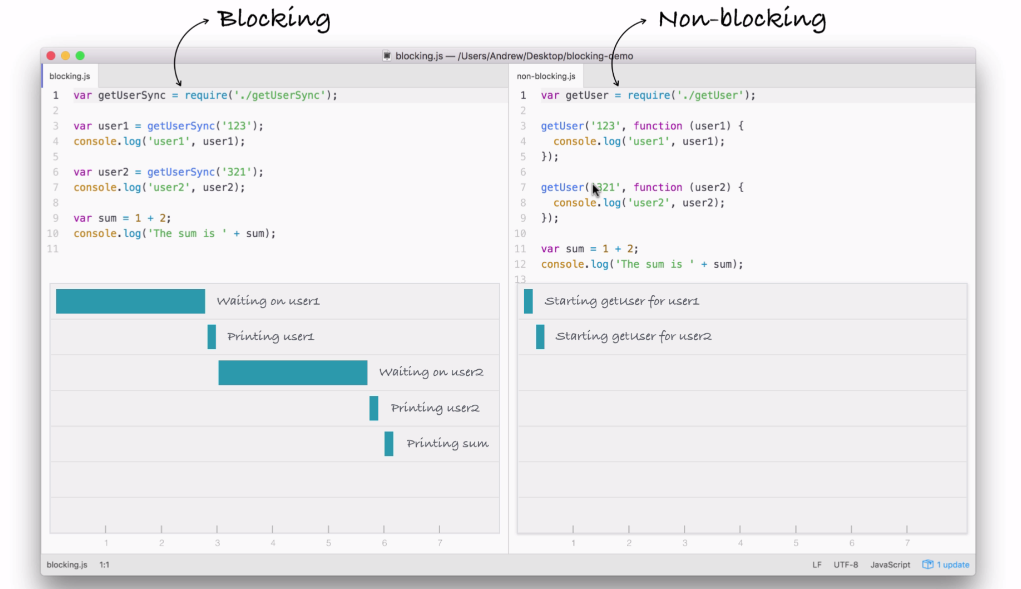
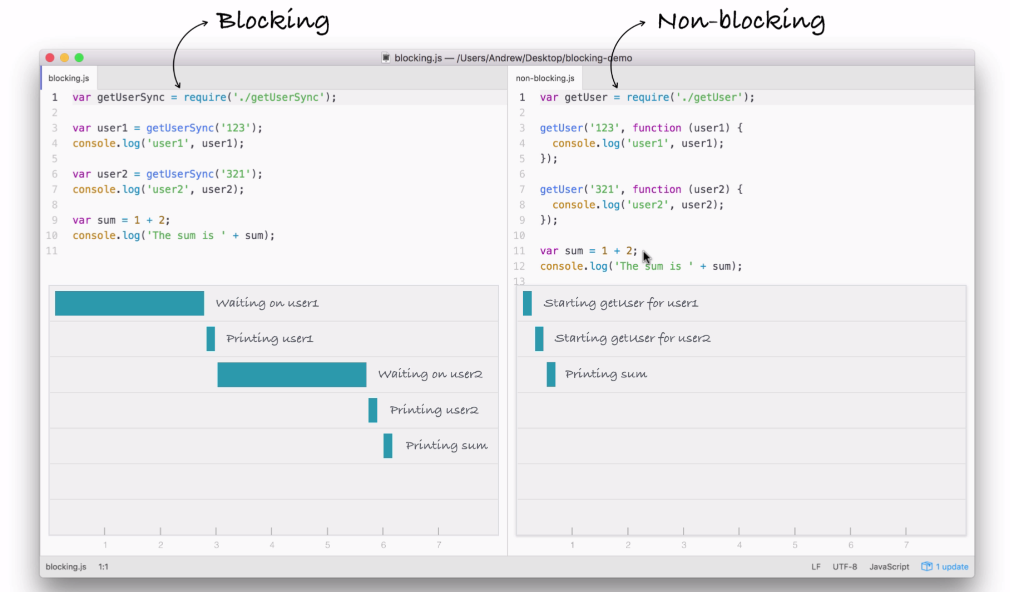
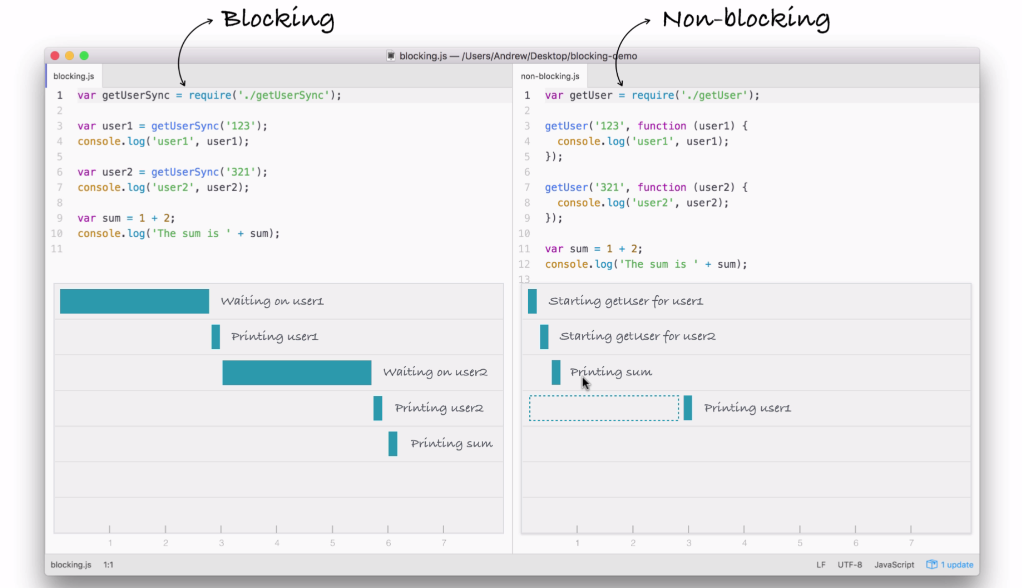
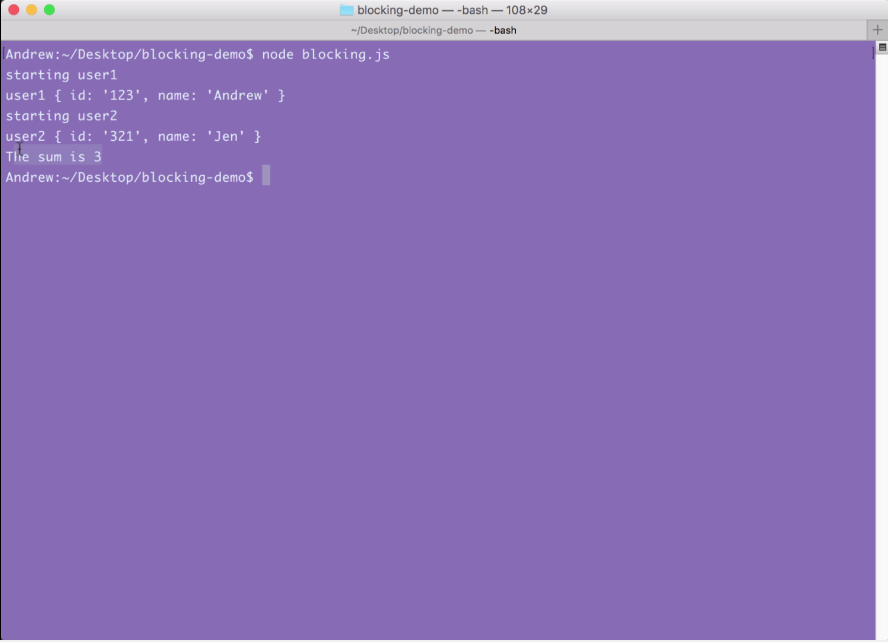
Node is an event-driven, non-blocking language. Now, what is I/O? I/O is something that your application does all of the time. When you're reading or writing to a database, that is I/O, which is short form for input/output.
This is the communication from your Node application to other things inside of the Internet of Things. This could be a database read and write request, you may be changing some files on your filesystem, or you may be making an HTTP request to a separate web server, such as a Google API for fetching a map for the user's current location. All of these use I/O, and I/O takes time.
Now, the non-blocking I/O is great. That means while one user is requesting a URL from Google, other users can be requesting a database file read and write access, they can be requesting all sorts of things without preventing anyone else from getting some work done.