

For our first application, we are going to build the base for a news aggregation site. News aggregation sites, such as Drudge Report (http://www.drudgereport.com/), are both popular and profitable.
News aggregation sites rely on a human editor to cull top stories from around the web and link to them on their homepage. We are going to attempt to usurp the need for pesky humans and automate the selection of articles via data scraping and parsing.
We will focus on workflow as much as actual code. Workflow is of paramount importance, and by following these simple steps we will end up with cleaner, more concise, and maintainable code.
It's important to acknowledge that we are dealing with live data. By the time you read this, the top story will have changed and page structure may have changed with it, hence the importance of workflow. You need to be able to adapt to your data.
The first thing we need to do is identify our sources. For the sake of this quick start, we will limit this to one source. What if we could pull the top headline off The New York Times? Their website receives over 30 million unique visitors a month and does over 100 million in advertising a year. That should be a good start for our news aggregation site. The New York Times homepage is shown in the following screenshot:
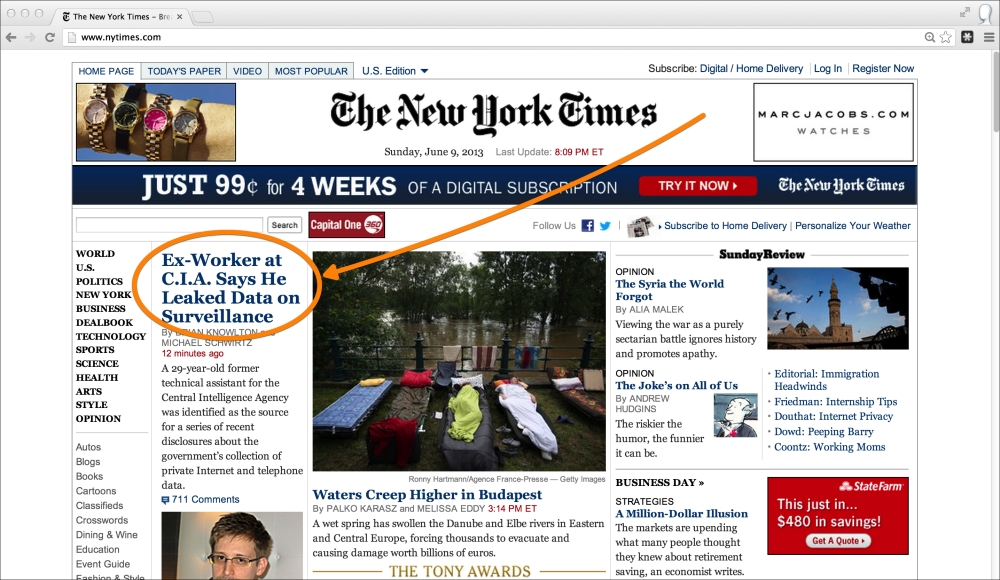
Our goal is to parse the following two pieces of information off The New York Times homepage:
The text for the top headline
The URL that the top headline links to
With our goals in sight, it's time to turn our attention to the Document Object Model (DOM). The DOM is the standard convention used for representing objects in HTML. Put a little simpler, the DOM is the HTML structure.
We need to determine the structure of the top news heading. Just by looking at the page, we can see that it has slightly larger text. This is promising, as it indicates it likely has its own CSS style. We can investigate further by inspecting the headline in Chrome Developer Tools. Right-click on the headline in Chrome and select Inspect Element. This will load the element inside the tools.
Viewing the source and inspecting the headline in Chrome is shown in the following screenshot:
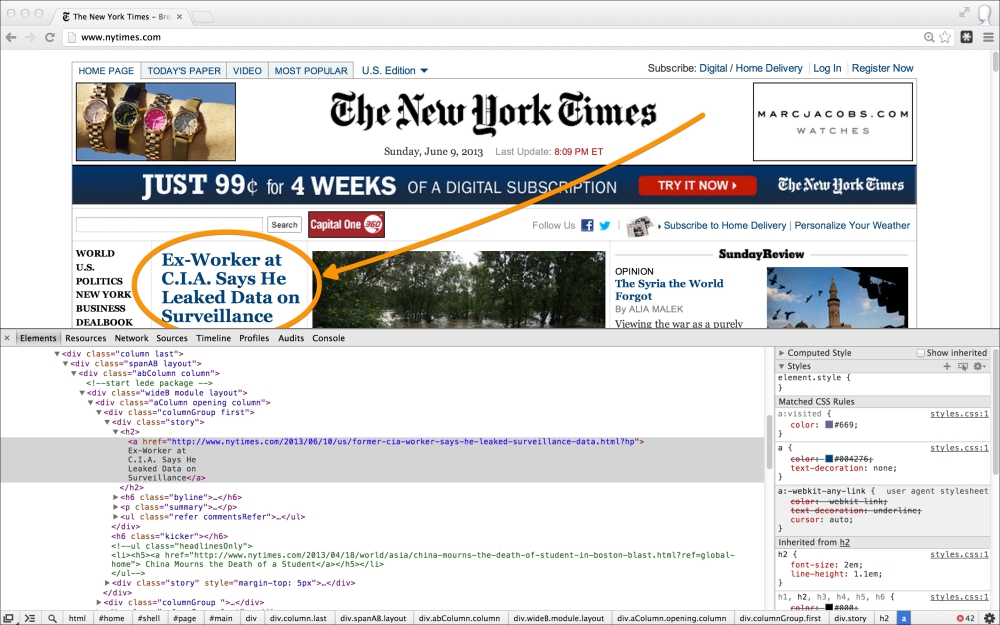
Look at the HTML source; the top heading is wrapped inside an <a> anchor link tag within a <h2> heading:
<h2> <a href="http://www.nytimes.com/2013/06/10/us/former-cia-worker-says-he-leaked-surveillance-data.html?hp"> Ex-Worker at C.I.A. Says He Leaked Data on Surveillance</a> </h2>
Quickly scanning the remainder of the source, this appears to be the only <h2> present. This means we should not need a greater degree of specificity.
Our goal in analyzing the DOM is to determine a selector we can use to target the headline. The Nokogiri parser works by passing a selector and returning matched elements or nodes. Nokogiri supports two types of selectors: XPath and CSS.
XPath is a language designed for selecting nodes in an XML document. XPath works by representing an XML document as a tree that allows you to select nodes with different levels of specificity by navigating further and further down branches or nodes.
The XPath language looks a lot like the standard file path syntax in a *nix file system. The standard example XPATH selector is /A/B/C, where C is a child of B, which is a child of A. So you are selecting all C elements nested within B elements nested within A elements.
CSS is the language used to style HTML documents. CSS selectors are how one targets a part of the HTML document for styling. CSS selectors make use of a similar tree-like selection pattern with a few exceptions. HTML objects often contain a class or ID. In the case when you are using a class, you prepend the name with a period. In the case you are using an ID, you prepend the name of the ID with a hash mark.
Lucky for us, our goal is only to select the <a> anchor link inside the <h2> tag, which we believe to be the only one on the page.
The XPATH selector for this element is //h2/a
The CSS selector for this element is h2 a
We are going to use the CSS selector for this application as they are significantly faster to search for in Nokogiri. There is also a lot of additional selection power with the support for CSS3.
While the selections used in this application are very basic, if you would like to learn more about selectors, you can read the W3C CSS specification which contains the complete set of rules regarding valid CSS selectors http://www.w3.org/TR/CSS21/syndata.html#value-def-identifier.
Tip
If you prefer a more visual approach to identifying selectors, try out the free Selector Gadget bookmarklet http://selectorgadget.com/. Selector Gadget allows you to click elements and instantly see CSS and XPath selectors.
We now have a goal and a hypothesis about how we can reach that goal. Our hypothesis is that we can extract the headline for the top New York Times story by looking for the first <a> anchor link contained within the first and only <h2> heading.
We will use IRB, the interactive Ruby shell, to test our theory and explore coding strategies. IRB is an excellent way to play with new code and gems. If you have not used IRB before, it is a REPL that comes bundled with Ruby. A read-eval-print loop (REPL) is an interactive shell that allows you to enter an expression which is evaluated and the result displayed.
To launch the Ruby REPL IRB, simply type from the command line:
$ irb
This will launch and you should get back a prompt that looks something like:
2.0.0p195 :001 >
The first thing we need to do is scrape the page. Scraping the page is a very easy task in Ruby. We will make use of OpenURI (http://www.ruby-doc.org/stdlib-2.0/libdoc/open-uri/rdoc/OpenURI.html), which is part of the Ruby Standard Library, meaning it comes bundled with Ruby. OpenURI makes it easy to open a URL as though it was a local file. We will need to import it with a require statement:
> require 'open-uri'
If this works successfully, we should receive a response of:
=> true
Now, we'll load the HTML source into a variable using OpenURI:
> data = open('http://nytimes.com')Assuming a good network connection, this will return back Tempfile with the HTML source. It should look something like this:
=> #<Tempfile:/var/folders/l9/2p_x8hqj4b737c40lbpb99zw0000gn/T/open-uri20130610-37901-xaavtx>
We can treat this new data object like any other file. For example, we can check that we successfully scraped the source by looping through and printing each line as follows:
> data.each_line { |line|
> p line
> }This returns the complete HTML source of the page confirming we have successfully scraped the New York Times homepage. To see more things that we can do with our data object, we can call data.methods.
The next step is to parse our data object and for this we need Nokogiri. Because we have already installed the gem, we can import it with a simple require statement:
> require 'nokogiri'
Similar to when we required open-uri, we should get a response back:
=> true
With Nokogiri loaded we can create a Nokogiri::HTML::Document from our data object:
> doc = Nokogiri::HTML(data)
Tip
We could also combine the scraping with this step by expressing our doc variable as doc = Nokogiri::HTML (open http://nytimes.com).
This will respond with the complete Nokogiri node set which looks very similar to the HTML source.
We can now use our previous CSS selector to take advantage of Nokogiri's at_css method. The at_css method searches for the first node matching the CSS selector. Our other option would be to use the css method which returns a NodeSet with all instances matching the CSS selector.
Since this selector only occurs once in our source, sticking with the at_css method should be fine:
> doc.at_css('h2 a')This returns a Nokogiri XML Element node that matches our selector. If we look hard enough, we should see the headline within the response:
=> #<Nokogiri::XML::Element:0x3ff4161ab84c name="a" attributes=[#<Nokogiri::XML::Attr:0x3ff4161ab7e8 name="href" value="http://www.nytimes.com/2013/06/10/us/former-cia-worker-says-he-leaked-surveillance-data.html?hp">] children=[#<Nokogiri::XML::Text:0x3ff4161ab3b0 "\nEx-Worker at\nC.I.A. Says He\nLeaked Data on\nSurveillance">]>
We can now make use of another Nokogiri method, content, to extract the text from the node.
> doc.at_css('h2 a').content
=> "\nEx-Worker at\nC.I.A. Says He\nLeaked Data on\nSurveillance"Tip
Press the up arrow on your keyboard to cycle through your IRB history. This makes it especially easy to append another method on your last call.
And there we have the top headline from The New York Times. \n are line feeds marking new lines in the source. Because we now have a Ruby string, we can use the gsub method to clean it up with a simple search and replace. We can chain that to a strip method and remove any extra whitespace surrounding the string:
> doc.at_css('h2 a').content.gsub(/\n/," ").strip
=> "Ex-Worker at C.I.A. Says He Leaked Data on Surveillance"Goal one complete! We now have the parsed text from the top headline stored in a variable.
That leaves the URL for the headline. The URL is located within the href attribute of the link. Nokogiri provides a get_attribute method which can easily extract the contents of an attribute:
> doc.at_css('h2 a').get_attribute('href')
=> "http://www.nytimes.com/2013/06/10/us/former-cia-worker-says-he-leaked-surveillance-data.html?hp"And there we have the link.Tip
You can also access an attribute using the [:attr-name] shortcut, for example doc.at_css('h2 a')[:href].
You should see there is certain fluidity between research and explore. You analyze the DOM and come up with theories about which selectors you can use and then test those theories in the REPL.
You could just write code in a text editor and execute, but you don't get the same instantaneous feedback. Additionally, you will often find your resulting text or value requires some additional cleanup like we performed with the gsub and strip method. The REPL is a great place to play with these kinds of operations and investigate options.
Tip
If you like working within IRB, there is another project out there that is essentially a turbo-charged version called Pry (http://pry.github.com). It's a little advanced, so proceed with caution, but there's no reason you cannot have both running on your system.
We have our goal and our hypothesis. We've shown our hypothesis to be true. We have some sample code to execute our hypothesis. Now, it's time to write our Ruby script:
# include the required libraries
require 'open-uri'
require 'nokogiri'
# scrape the web page
data = open('http://nytimes.com')
# create a Nokogiri HTML Document from our data
doc = Nokogiri::HTML(data)
# parse the top headline and clean it up
ny_times_headline = doc.at_css('h2 a').content.gsub(/\n/," ").strip
# parse the link for the top headline
ny_times_link = doc.at_css('h2 a').get_attribute('href')
# output the parsed data
p ny_times_headline
p ny_times_linkLet's give it a shot. Fire up your terminal and run:
$ ruby quickstart.rb
You should see the current top headline and link from The New York Times:
"Ex-Worker at C.I.A. Says He Leaked Data on Surveillance" "http://www.nytimes.com/2013/06/10/us/former-cia-worker-says-he-leaked-surveillance-data.html?hp"
Excellent! Our script is working. There is one more part we need to address for this to be a proper Ruby application and that is dependency management.
Our application requires a dependency, the Nokogiri gem. Our program only has one dependency. It is not a huge deal to expect another developer to look at the source and manually install Nokogiri, but to be a good citizen in the Ruby community we should manage our dependencies.
Bundler is the standard for managing dependencies in Ruby. To get started, create a file called Gemfile in the same directory as your script.
We now need to add two lines to our Gemfile.
source 'http://rubygems.org' gem 'nokogiri'
The first line tells the bundler where to look for the gem. The second line tells bundler which gem to install. If you wanted to add another dependency, you could simply add another gem line:
gem 'another_required_gem'
With our gem file in place, you, or anyone else can install all required dependencies within the directory by running:
$ bundle install Fetching gem metadata from https://rubygems.org/......... Fetching gem metadata from https://rubygems.org/.. Resolving dependencies... Using mini_portile (0.5.0) Using nokogiri (1.6.0) Using bundler (1.3.5) Your bundle is complete!
Our dependency management is working!
Technically we aren't done. We have our Ruby script that uses Nokogiri to extract a link to the top headline, but our broader goal was to create a news aggregation website. The easiest way to do this is with Sinatra (http://www.sinatrarb.com/). Sinatra provides a simple web wrapper for our script.
The Sinatra homepage is shown in the following screenshot:

Sinatra is a Ruby gem. Rather than installing it from the command line, let's add it to our Gemfile:
source 'http://rubygems.org' gem 'nokogiri' gem 'sinatra'
To get all our dependencies installed, from the command line run:
$ bundle install Your bundle is complete!
Sinatra is now installed.
This is not a Sinatra tutorial, but I think Sinatra is easy enough that you can follow along with the following commented source to see how the simple interaction with Sinatra and Nokogiri works:
# include the required libraries
require 'open-uri'
require 'nokogiri'
# add sinatra to the list
require 'sinatra'
# scrape the web page
data = open('http://nytimes.com')
# create a Nokogiri HTML Document from our data
doc = Nokogiri::HTML(data)
# parse the top headline and clean it up
ny_times_headline = doc.at_css('h2 a').content.gsub(/\n/," ").strip
# parse the link for the top headline
ny_times_link = doc.at_css('h2 a').get_attribute('href')
# create a HTML string we can send to the browser
# this first line is throw away wrapping the name of our newly launched service
# inside a h1 tag
html = "<h1>Nokogiri News Service</h1>"
# here we append a link to the previous HTML using our parsed data
html += "<h2>Top Story: <a href=\"#{ny_times_link}\">#{ny_times_headline}</a></h2>"
# this tells sinatra to respond to a request for the root document
get '/' do
# send our HTML to the browser
html
end We can now spin up our web server by running the following script:
$ ruby quickstart_extend.rb [2013-06-10 19:09:46] INFO WEBrick 1.3.1 [2013-06-10 19:09:46] INFO ruby 1.9.3 (2012-04-20) [x86_64-darwin12.2.1] == Sinatra/1.4.3 has taken the stage on 4567 for development with backup from WEBrick [2013-06-10 19:09:46] INFO WEBrick::HTTPServer#start: pid=6159 port=4567
This tells us the WEBrick server, which Sinatra is based on, has launched and is running on port 4567. This means we can access our site at http://localhost:4567.
Our running news aggregation site is shown in the following screenshot:
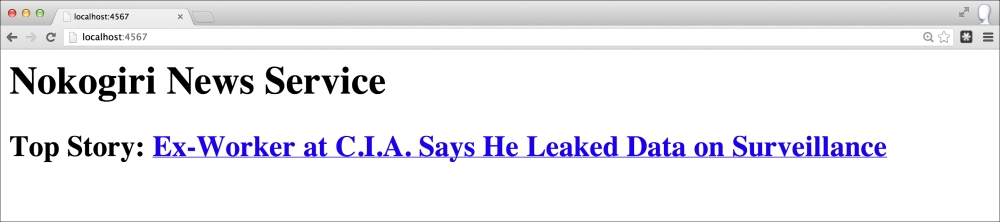
If we look at our final Sinatra-enabled Nokogiri script without the comments, it is 12 lines long! In those 12 little lines, we scrape the homepage of The New York Times, parse the top headline and link, construct a HTML document, spin up a web server, and respond to a get request at the root with our dynamic news service. That's why people like Ruby, and Nokogiri is one of the most downloaded gems.
Don't stop here, extend further and add additional sources. Read through the following top features to get more ideas on how to use the excellent Nokogiri gem.