

In order to fully understand how Elasticsearch works, especially when it comes to indexing and query processing, it is crucial to understand how Apache Lucene library works. Under the hood, Elasticsearch uses Lucene to handle document indexing. The same library is also used to perform a search against the indexed documents. In the next few pages, we will try to show you the basics of Apache Lucene, just in case you've never used it.
You may wonder why Elasticsearch creators decided to use Apache Lucene instead of developing their own functionality. We don't know for sure since we were not the ones who made the decision, but we assume that it was because Lucene is mature, open-source, highly performing, scalable, light and, yet, very powerful. It also has a very strong community that supports it. Its core comes as a single file of Java library with no dependencies, and allows you to index documents and search them with its out-of-the-box full text search capabilities. Of course, there are extensions to Apache Lucene that allow different language handling, and enable spellchecking, highlighting, and much more, but if you don't need those features, you can download a single file and use it in your application.
Although I would like to jump straight to Apache Lucene architecture, there are some things we need to know first in order to fully understand it, and those are as follows:
Document: It is a main data carrier used during indexing and search, containing one or more fields, that contain the data we put and get from Lucene.
Field: It is a section of the document which is built of two parts: the name and the value.
Term: It is a unit of search representing a word from the text.
Token: It is an occurrence of a term from the text of the field. It consists of term text, start and end offset, and a type.
Apache Lucene writes all the information to the structure called inverted index. It is a data structure that maps the terms in the index to the documents, not the other way round like the relational database does. You can think of an inverted index as a data structure, where data is term oriented rather than document oriented.
Let's see how a simple inverted index can look. For example, let's assume that we have the documents with only title field to be indexed and they look like the following:
Elasticsearch Server (document 1)
Mastering Elasticsearch (document 2)
Apache Solr 4 Cookbook (document 3)
So, the index (in a very simple way) could be visualized as shown in the following figure:
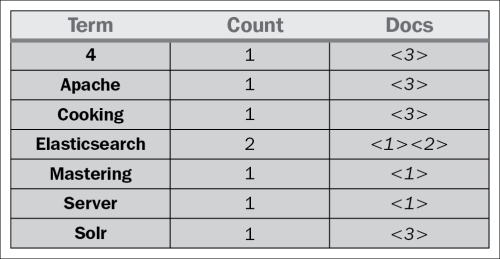
As you can see, each term points to the number of documents it is present in. This allows for a very efficient and fast search such as the term-based queries. In addition to this, each term has a number connected to it: the count, telling Lucene how often it occurs.
Each index is divided into multiple write once and read many time segments. When indexing, after a single segment is written to disk, it can't be updated. For example, the information about deleted documents is stored in a separate file, but the segment itself is not updated.
However, multiple segments can be merged together in a process called segments merge. After forcing, segments are merged, or after Lucene decides it is time for merging to be performed, segments are merged together by Lucene to create larger ones. This can be I/O demanding; however, it is needed to clean up some information because during that time some information that is not needed anymore is deleted, for example the deleted documents. In addition to this, searching with the use of one larger segment is faster than searching against multiple smaller ones holding the same data. However, once again, remember that segments merging is an I/O demanding operation and you shouldn't force merging, just configure your merge policy carefully.
Note
If you want to know what files are building the segments and what information is stored inside them, please take a look at Apache Lucene documentation available at http://lucene.apache.org/core/4_10_3/core/org/apache/lucene/codecs/lucene410/package-summary.html.
Of course, the actual index created by Lucene is much more complicated and advanced, and consists of more than the terms their counts and documents in which they are present. We would like to tell you about a few of those additional index pieces because even though they are internal, it is usually good to know about them as they can be very handy.
A norm is a factor associated with each indexed document and stores normalization factors used to compute the score relative to the query. Norms are computed on the basis of index time boosts and are indexed along with the documents. With the use of norms, Lucene is able to provide an index time-boosting functionality at the cost of a certain amount of additional space needed for norms indexation and some amount of additional memory.
Term vectors are small inverted indices per document. They consist of pairs—a term and its frequency—and can optionally include information about term position. By default, Lucene and Elasticsearch don't enable term vectors indexing, but some functionality such as the fast vector highlighting requires them to be present.
With the release of Lucene 4.0, the library introduced the so-called codec architecture, giving developers control over how the index files are written onto the disk. One of the parts of the index is the posting format, which stores fields, terms, documents, terms positions and offsets, and, finally, the payloads (a byte array stored at an arbitrary position in Lucene index, which can contain any information we want). Lucene contains different posting formats for different purposes, for example one that is optimized for high cardinality fields like the unique identifier.
As we already mentioned, Lucene index is the so-called inverted index. However, for certain features, such as faceting or aggregations, such architecture is not the best one. The mentioned functionality operates on the document level and not the term level and because Elasticsearch needs to uninvert the index before calculations can be done. Because of that, doc values were introduced and additional structure used for faceting, sorting and aggregations. The doc values store uninverted data for a field they are turned on for. Both Lucene and Elasticsearch allow us to configure the implementation used to store them, giving us the possibility of memory-based doc values, disk-based doc values, and a combination of the two.
Of course, the question arises of how the data passed in the documents is transformed into the inverted index and how the query text is changed into terms to allow searching. The process of transforming this data is called analysis.
Analysis is done by the analyzer, which is built of tokenizer and zero or more filters, and can also have zero or more character mappers.
A tokenizer in Lucene is used to divide the text into tokens, which are basically terms with additional information, such as its position in the original text and its length. The result of the tokenizer work is a so-called token stream, where the tokens are put one by one and are ready to be processed by filters.
Apart from tokenizer, Lucene analyzer is built of zero or more filters that are used to process tokens in the token stream. For example, it can remove tokens from the stream, change them or even produce new ones. There are numerous filters and you can easily create new ones. Some examples of filters are as follows:
ASCII folding filter: It removes non ASCII parts from tokens
Synonyms filter: It is responsible for changing one token to another on the basis of synonym rules
Multiple language stemming filters: These are responsible for reducing tokens (actually the text part that they provide) into their root or base forms, the stem
Filters are processed one after another, so we have almost unlimited analysis possibilities with adding multiple filters one after another.
The last thing is the character mappings, which is used before tokenizer and is responsible for processing text before any analysis is done. One of the examples of character mapper is the HTML tags removal process.
We may wonder how that all affects indexing and querying when using Lucene and all the software that is built on top of it. During indexing, Lucene will use an analyzer of your choice to process the contents of your document; different analyzers can be used for different fields, so the title field of your document can be analyzed differently compared to the description field.
During query time, if you use one of the provided query parsers, your query will be analyzed. However, you can also choose the other path and not analyze your queries. This is crucial to remember because some of the Elasticsearch queries are being analyzed and some are not. For example, the prefix query is not analyzed and the match query is analyzed.
What you should remember about indexing and querying analysis is that the index should be matched by the query term. If they don't match, Lucene won't return the desired documents. For example, if you are using stemming and lowercasing during indexing, you need to be sure that the terms in the query are also lowercased and stemmed, or your queries will return no results at all.
Some of the query types provided by Elasticsearch support Apache Lucene query parser syntax. Because of this, it is crucial to understand the Lucene query language.
A query is divided by Apache Lucene into terms and operators. A term, in Lucene, can be a single word or a phrase (group of words surrounded by double quote characters). If the query is set to be analyzed, the defined analyzer will be used on each of the terms that form the query.
A query can also contain Boolean operators that connect terms to each other forming clauses. The list of Boolean operators is as follows:
AND: It means that the given two terms (left and right operand) need to match in order for the clause to be matched. For example, we would run a query, such as apache
ANDlucene, to match documents with both apache and lucene terms in a document field.OR: It means that any of the given terms may match in order for the clause to be matched. For example, we would run a query, such as apache
ORlucene, to match documents with apache or lucene (or both) terms in a document field.NOT: It means that in order for the document to be considered a match, the term appearing after the
NOToperator must not match. For example, we would run a query luceneNOTElasticsearch to match documents that contain lucene term, but not the Elasticsearch term in the document field.
In addition to these, we may use the following operators:
+: It means that the given term needs to be matched in order for the document to be considered as a match. For example, in order to find documents that match lucene term and may match apache term, we would run a query such as +lucene apache.
-: It means that the given term can't be matched in order for the document to be considered a match. For example, in order to find a document with lucene term, but not Elasticsearch term, we would run a query such as +lucene -Elasticsearch.
When not specifying any of the previous operators, the default OR operator will be used.
In addition to all these, there is one more thing: you can use parenthesis to group clauses together for example, with something like the following query:
ElasticsearchAND(masteringORbook)
Of course, just like in Elasticsearch, in Lucene all your data is stored in fields that build the document. In order to run a query against a field, you need to provide the field name, add the colon character, and provide the clause that should be run against that field. For example, if you would like to match documents with the term Elasticsearch in the title field, you would run the following query:
title:Elasticsearch
You can also group multiple clauses. For example, if you would like your query to match all the documents having the Elasticsearch term and the mastering book phrase in the title field, you could run a query like the following code:
title:(+Elasticsearch +"mastering book")
The previous query can also be expressed in the following way:
+title:Elasticsearch +title:"mastering book"
In addition to the standard field query with a simple term or clause, Lucene allows us to modify the terms we pass in the query with modifiers. The most common modifiers, which you will be familiar with, are wildcards. There are two wildcards supported by Lucene, the ? and * terms. The first one will match any character and the second one will match multiple characters.
Note
Please note that by default these wildcard characters can't be used as the first character in a term because of performance reasons.
In addition to this, Lucene supports fuzzy and proximity searches with the use of the ~ character and an integer following it. When used with a single word term, it means that we want to search for terms that are similar to the one we've modified (the so-called fuzzy search). The integer after the ~ character specifies the maximum number of edits that can be done to consider the term similar. For example, if we would run a query, such as writer~2, both the terms writer and writers would be considered a match.
When the ~ character is used on a phrase, the integer number we provide is telling Lucene how much distance between the words is acceptable. For example, let's take the following query:
title:"mastering Elasticsearch"
It would match the document with the title field containing mastering Elasticsearch, but not mastering book Elasticsearch. However, if we would run a query, such as title:"mastering Elasticsearch"~2, it would result in both example documents matched.
We can also use boosting to increase our term importance by using the ^ character and providing a float number. Boosts lower than one would result in decreasing the document importance. Boosts higher than one will result in increasing the importance. The default boost value is 1. Please refer to the Default Apache Lucene scoring explained section in Chapter 2, Power User Query DSL, for further information on what boosting is and how it is taken into consideration during document scoring.
In addition to all these, we can use square and curly brackets to allow range searching. For example, if we would like to run a range search on a numeric field, we could run the following query:
price:[10.00 TO 15.00]
The preceding query would result in all documents with the price field between 10.00 and 15.00 inclusive.
In case of string-based fields, we also can run a range query, for example name:[Adam TO Adria].
The preceding query would result in all documents containing all the terms between Adam and Adria in the name field including them.
If you would like your range bound or bounds to be exclusive, use curly brackets instead of the square ones. For example, in order to find documents with the price field between 10.00 inclusive and 15.00 exclusive, we would run the following query:
price:[10.00 TO 15.00}
If you would like your range bound from one side and not bound by the other, for example querying for documents with a price higher than 10.00, we would run the following query:
price:[10.00 TO *]