

Data communication is probably the most important activity in a software application. When was the last time you developed an application that did not communicate with a data service?
Even what we used to call static sites are now starting to be based on generators that use data. Games and other applications that load their data with their initial download also require some form of data communication afterwards to save preferences, track usages, and keep records about everything the user is doing. With the foreseen future of the Internet of Things, where micro devices will be everywhere, the role of data communication will become more important.
Relational databases successfully deliver on reliability, consistency, and integrity for the task of storing data. Document databases give us flexibility to manage document-oriented information, and scale it horizontally. However, the current solutions we use for communicating data between multiple software applications have many problems. We came up with all sorts of interfaces between applications and data services to fill the gaps. The most popular interfaces we use today are RESTful APIs and adhoc HTTP APIs. These interfaces are especially popular for web applications, but they've seen success with mobile applications as well.
Here are some of the tasks an Application Programming Interface (API) can do:
Act as a controller between protected raw data services and software clients
Parse a client request for access rights and enforce them
Construct SQL join statements to satisfy a client request efficiently
Process raw data into structures demanded by clients
Respond with data in specific formats such as JSON or XML
RESTful APIs are widely popular and have excellent use cases, but they also have limitations and disadvantages. They come with some dependencies on browser implementations of HTTP, and different browsers have different support for HTTP methods, and different interpretation for HTTP response codes. Using only HTTP methods and response codes limits what we can do with RESTful APIs and developers usually resort to customizing and interpreting the request payload instead.
In RESTful APIs, the language we use for the request is different than the language we use for the response. There is a disconnect between the request and the response, just like there is a disconnect between a question in English and an answer to that question in Japanese. There are no standards or agreements about what request and response HTTP codes mean and implementers use different specifications, which makes working with different APIs unpredictable. This lack of standards negatively affects the learning and development process around these APIs, and makes consuming them a challenge. Without standard specifications, developers need to consult documentation to understand the approach taken by every provider, and documentation is always at the risk of becoming outdated.
To consume RESTful APIs, we use a URL to read from or write to a single resource, such as a product, a person, a post, or a comment. If we need to work with multiple resources such as a list of posts with a list of comments, we need to use multiple endpoints. Alternatively, we can develop a custom endpoint (given that we have access to do so). The clients do not have any control over the response, unless we start customizing those endpoints to support that control. For example, we can't ask a friend resource endpoint for just the name and location of a friend, we can only ask for all the information about that friend, whether we need it or not. The clients basically depend on the servers, and this fact limits their growth because it will be tied to the growth of the servers.
Some of these issues are solved by other application programming interfaces such as JSON APIs, JSend, JSON LD, and many more. GraphQL is one other alternative that is attempting to solve most of these issues.
First, a draft GraphQL RFC specification has been created. It's managed by Facebook, but it's open source on GitHub and anyone can contribute to it. All GraphQL implementers are expected to honor that specification and work with the community to update the specification when needed.
GraphQL is protocol-agnostic and does not depend on anything HTTP. We don't use HTTP methods or HTTP response codes with GraphQL. However, HTTP is one channel where we can do GraphQL communication, and it will naturally be the popular channel for web development.
The language used for a GraphQL request is directly related to the language used for the response. If we analyze a JSON response, we'll find it to be a dictionary that has keys and values. The values can themselves be nested dictionaries with their own keys and values, or with arrays of values. Since the values basically represent the data, if we strip out all the values from the JSON dictionary, we get the GraphQL query that can be used for the request. This is a simple question-to-answer relationship that's expressed naturally with the same language. Since we use a similar language to communicate between clients and servers, debugging problems become easier. Furthermore, the GraphQL specification adopts a strong type system for all GraphQL elements; any misuse can be easily detected and properly reported. Also, with GraphQL queries mirroring the shape of their response, any deviations can be detected, and these deviations would point us to the exact query fields that are not resolving correctly.
A GraphQL server can be a single endpoint that handles all the client requests, and it can give the clients the power to customize those requests at any time. Clients can ask for multiple resources in the same request and they can customize the fields needed from all of them. This way, clients can be in control of the data they fetch and they can easily avoid the problems of over-fetching and under-fetching. With GraphQL, clients and servers are independent and they can be changed without affecting each other.
These are some of the reasons that make GraphQL efficient, effective, and easy to use. However, the most important reason why GraphQL is considered a game changer is its mental model around declarative data communication.
The idea of GraphQL was born out of practical needs, and these needs were mainly centered around mobile clients. Here are some examples of these needs:
Mobile clients are smart and have evolving data requirements, and we can't have them depend on a data service. We need to give them more power and have them decide what data to consume.
We can't control the versions of mobile applications like we do on the Web. We need a way to add new features without removing the old ones, and we need a way to communicate what features are now deprecated.
Resources available for mobile clients are limited. We can't entertain the idea of multiple round-trips to the server to collect the data required by a single view, and we need to minimize any processing needed to piece together data returned by servers.
However, I'd argue that the most important need that influenced the creation of GraphQL was not mobile-specific, but rather one that applies to all platforms:
The developer experience is as important as, and maybe actually more important than, the user experience. DI/DX is becoming the new UI/UX because the former drives the latter. When it comes to data communication, this means we need to abstract the imperative steps needed to communicate an application's data requirements, and give developers a declarative language for that instead. This language should enable developers to express their applications' data requirements in a way close to how that data will actually be used in their applications.
Putting the product developers' needs first means that instead of thinking about the proper ways to expose data on the servers, we first think about the developers who build frontend applications, and the proper ways for them to express their applications' data requirements.
That's why frontend application developers will love GraphQL. From their point of view, it's a query language that allows them to ask for the data required by their applications in a simple, natural, and declarative way that mirrors the way they use that data in their applications.
The needs that influenced GraphQL are really best explained with an example. Let's imagine that we are the developers responsible for building a shiny new user interface to represent the Star Wars films and characters.
The first UI we've been tasked to build is simple: a view to show information about a single Star Wars person, for example, Darth Vader. The view should display the person's name, birth year, planet name, and the titles of all the films in which they appeared.
As simple as that sounds, we're actually dealing with three different resources here: person, planet, and film. The relation between these resources is simple and anyone can guess the shape of the data here. A person object belongs to one planet object, and it will have one or more film objects.
The JSON data for this UI could be something like:
{
"data": {
"person": {
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planet": {
"name": "Tatooine"
},
"films": [
{ "title": "A New Hope" },
{ "title": "The Empire Strikes Back" },
{ "title": "Return of the Jedi" },
{ "title": "Revenge of the Sith" }
]
}
}
}
Assuming a data service gave us this exact structure for the data, here's one possible way to represent its view with React.js:
// The Container Component:
<PersonProfile person={data.person}></PersonProfile>
// The PersonProfile Component:
Name: {person.name}
Birth Year: {person.birthYear}
Planet: {person.planet.name}
Films: {person.films.map(film => film.title)}
This is a simple example, and while our experience with Star Wars might have helped us here a bit, the relationship between the UI and the data is clear. The UI used all the keys from the assumed JSON data object.
Let's now see how we can ask for this data using a RESTful API.
We need a single person's information, and assuming that we know the id of that person, a RESTful API is expected to expose that information with an endpoint like:
/people/{id}
This request will give us the name, birth year, and other information about the person. A good API will also give us the ID of this person's planet, and an array of IDs for all the films in which this person appeared.
Tip
Instead of IDs, RESTful APIs will usually give us the ready URLs that we need to follow to fetch more information about the resource. I am using IDs in the following examples to simplify the concept.
The JSON response for this request could be something like:
{
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planetId": 1,
"filmIds": [1, 2, 3, 6],
*** other information we do not need for this view ***
}
Then to read the planet's name, we ask:
/planets/1
And to read the film titles, we ask:
/films/1 /films/2 /films/3 /films/6
Once we have all six responses from the server, we can combine them to satisfy the data needed by our view.
Besides the fact that we had to do six round trips to satisfy a simple data need for a simple UI, our approach here was imperative. We gave instructions for how to fetch the data and how to process it to make it ready for the view.
Note
A RESTful API for Star Wars data is currently hosted at http://swapi.co/. Go ahead and try to construct our data person object there; the field names might be a bit different, but the API endpoints should be the same. You will need to do exactly six API calls. Furthermore, you will have to over-fetch information that the view does not need.
Of course, this is just one implementation of a RESTful API for this data. There could be better implementations that will make this view easier to implement. For example, if the API server implemented nested resources and understood the relation between a person and a film, we could read the films data with:
/people/{id}/films
However, API developers don't usually implement nested resource endpoints by default, and we would need to ask them to create these custom endpoints for us when we need them. That's the reality of scaling this type of API, we just add custom endpoints to efficiently satisfy the growing clients' needs. Managing custom endpoints like these without a structure around them would be a challenge.
Let's now look at the GraphQL approach. GraphQL on the server embraces the custom endpoints idea and takes it to its extreme. The server will be a single endpoint that replies to all data requests, and the interface channel does not matter. If we use an HTTP interface, HTTP methods and response codes would not matter either.
Let's assume we have a single GraphQL endpoint exposed over HTTP at /graphql. Since we want to ask for the data we need in a single round-trip, we'll need a way to express our complete data requirements for the server. We do this with a GraphQL query:
/graphql?query={...}
A GraphQL query is just a string, but it will have to include all the pieces of the data that we need, and this is where the declarative power comes in.
In English, here's how we declare our data requirement: we need a person's name, birth year, their planet's name, and the titles of all their films.
In GraphQL, this translates to:
{
person(ID: ...) {
name
birthYear
planet {
name
}
films {
title
}
}
}
Read the English-expressed requirements one more time and compare it to the GraphQL query. It's as close as it can get. Now compare this GraphQL query with the original JSON data that we started with:
{
"data": {
"person": {
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planet": {
"name": "Tatooine"
},
"films": [
{ "title": "A New Hope" },
{ "title": "The Empire Strikes Back" },
{ "title": "Return of the Jedi" },
{ "title": "Revenge of the Sith" }
]
}
}
}
The GraphQL query has the exact structure of the JSON data, except without all the values parts. If we think of this in terms of a question-answer relation, the question is the answer statement without the answer part.
If the answer statement is:
The closest planet to the Sun is Mercury.
A good representation of the question is the same statement without the answer part:
(What is) the closest planet to the Sun?
The same relation applies to a GraphQL query. Take a JSON response, remove all the answer parts (which are the values), and you'll get a GraphQL query very suitable to represent a question for that JSON response.
Now compare the GraphQL query with the React UI we defined for the data. Everything in the GraphQL query is used in the UI, and every variable used in the UI appears in the GraphQL query. This is the great mental model of GraphQL. The UI knows the exact data it needs, and extracting that requirement is fairly easy. Coming up with a GraphQL query is simply the task of extracting what's used as variables directly from the UI. Also, if we invert this model, it would still hold the power. If we have a GraphQL query, we know exactly how to use its response in the UI, because the query will be the same structure as the response. We don't need to inspect the response to know how to use it, and we don't need any documentation for the API; it's all built in.
A GraphQL API for Star Wars data is hosted at https://github.com/graphql/swapi-graphql. Go ahead and try to construct our data person object there. There are a few minor differences that we'll explain later, but here's the official query you can use against this API to read our data requirement for the view (with Darth Vader as an example):
{
person(personID: 4) {
name
birthYear
homeworld {
name
}
filmConnection {
films {
title
}
}
}
}
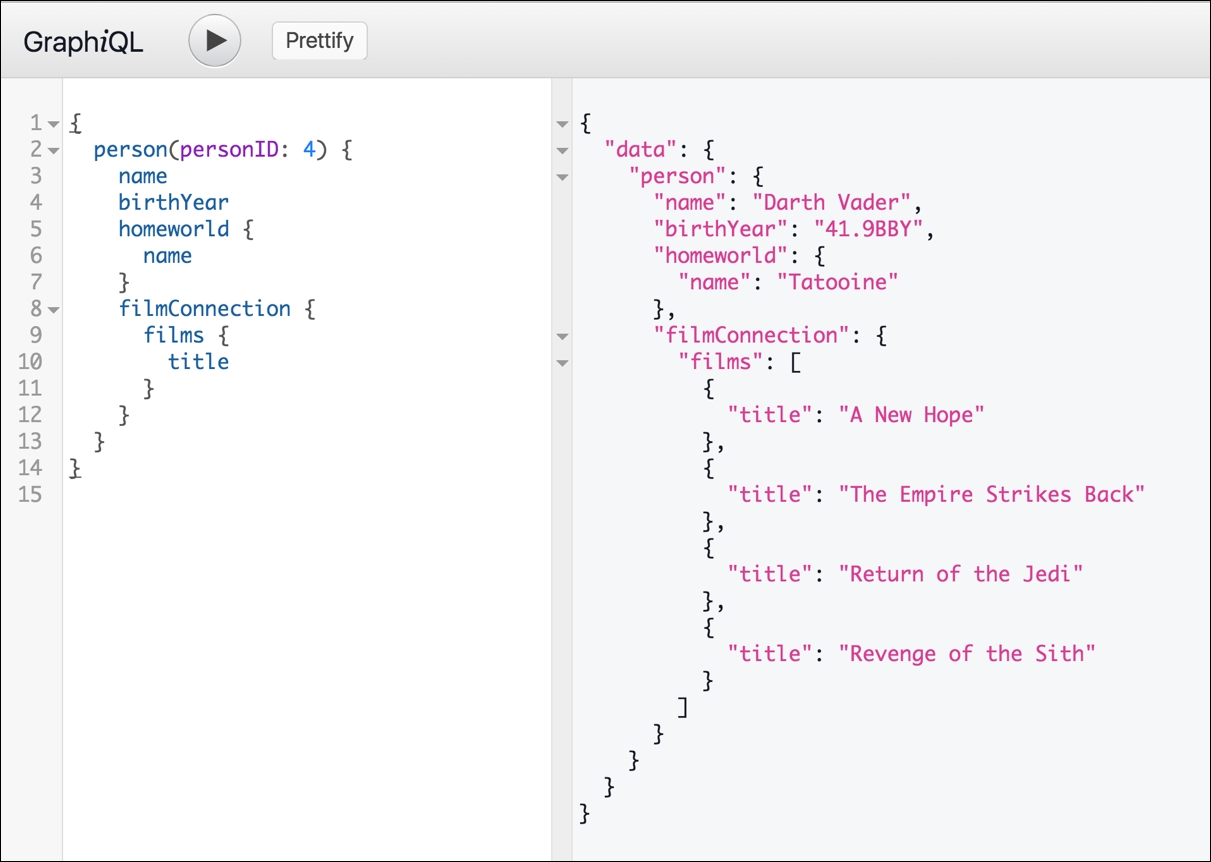
This request gives us a response structure very close to what our views used, and remember, we are getting all of this data in a single server round-trip. We'll explore the GraphiQL editor that you see in this API later in the chapter.