

Two weight matrices, 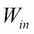 and
and 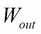 have been used for input or output respectively. While all weights of are updated at every iteration during back propagation, is only updated on the column corresponding to the current training input word.
have been used for input or output respectively. While all weights of are updated at every iteration during back propagation, is only updated on the column corresponding to the current training input word.
Weight tying (WT) consists of using only one matrix, W, for input and output embedding. Theano then computes the new derivatives with respect to these new weights and all weights in W are updated at every iteration. Fewer parameters leads to less overfitting.
In the case of Word2Vec, such a technique does not give better results for a simple reason: in the Word2Vec model, the probability of finding the input word in the context is given as:

It should be as close to zero but cannot be zero except if W = 0.
But in other applications, such as in Neural Network Language Models (NNLM) in Chapter 4, Generating Text with a Recurrent Neural Net and Neural Machine Translation (NMT) in Chapter 8, Translating and Explaining with Encoding-decoding Networks), it...