

The cornerstone of the Web as a commercial entity—the piece on which marketing and branding has relied on nearly exclusively—is the URL. While we're not yet looking at the top-level domain handling, we need to take up the reins of our URL and its paths (or endpoints).
In this chapter, we'll do just this by introducing multiple routes and corresponding handlers. First, we'll do this with a simple flat file serving and then we'll introduce complex mixers to do the routing with more flexibility by implementing a library that utilizes regular expressions in its routes.
By the end of this chapter, you should be able to create a site on localhost that can be accessed by any number of paths and return content relative to the requested path.
In this chapter, we will cover the following topics:
- Serving files directly
- Basic routing
- Using more complex routing with Gorilla
- Redirecting requests
- Serving basic errors
In the preceding chapter, we utilized the fmt.Fprintln function to output some generic Hello, World messaging in the browser.
This obviously has limited utility. In the earliest days of the Web and web servers, the entirety of the Web was served by directing requests to corresponding static files. In other words, if a user requested home.html, the web server would look for a file called home.html and return it to the user.
This might seem quaint today, as a vast majority of the Web is now served in some dynamic fashion, with content often being determined via database IDs, which allows for pages to be generated and regenerated without someone modifying the individual files.
Let's take a look at the simplest way in which we can serve files in a way similar to those olden days of the Web as shown:
package main
import (
"net/http"
)
const (
PORT = ":8080"
)
func main() {
http.ListenAndServe(PORT, http.FileServer(http.Dir("/var/www")))
}Pretty simple, huh? Any requests made to the site will attempt to find a corresponding file in our local /var/www directory. But while this has a more practical use compared to the example in Chapter 1, Introducing and Setting Up Go, it's still pretty limited. Let's take a look at expanding our options a bit.
In Chapter 1, Introducing and Setting Up, we produced a very basic URL endpoint that allowed static file serving.
The following are the simple routes we produced for that example:
func main() {
http.HandleFunc("/static",serveStatic)
http.HandleFunc("/",serveDynamic)
http.ListenAndServe(Port,nil)
}In review, you can see two endpoints, /static and /, which either serve a single static file or generate output to the http.ResponseWriter.
We can have any number of routers sitting side by side. However, consider a scenario where we have a basic website with about, contact, and staff pages, with each residing in /var/www/about/index.html, /var/www/contact.html, and /var/www/staff/home.html. While it's an intentionally obtuse example, it demonstrates the limitations of Go's built-in and unmodified routing system. We cannot route all requests to the same directory locally, we need something that provides more malleable URLs.
In the previous session, we looked at basic routing but that can only take us so far, we have to explicitly define our endpoints and then assign them to handlers. What happens if we have a wildcard or a variable in our URL? This is an absolutely essential part of the Web and any serious web server.
To invoke a very simple example, consider hosting a blog with unique identifiers for each blog entry. This could be a numeric ID representing a database ID entry or a text-based globally unique identifier, such as my-first-block-entry.
Note
In the preceding example, we want to route a URL like /pages/1 to a filename called 1.html. Alternately, in a database-based scenario, we'd want to use /pages/1 or /pages/hello-world to map to a database entry with a GUID of 1 or hello-world, respectively. To do this we either need to include an exhaustive list of possible endpoints, which is extremely wasteful, or implement wildcards, ideally through regular expressions.
In either case, we'd like to be able to utilize the value from the URL directly within our application. This is simple with URL parameters from GET or POST. We can extract those simply, but they aren't particularly elegant in terms of clean, hierarchical or descriptive URLs that are often necessary for search engine optimization purposes.
The built-in net/http routing system is, perhaps by design, relatively simple. To get anything more complicated out of the values in any given request, we either need to extend the routing capabilities or use a package that has done this.
In the few years that Go has been publicly available and the community has been growing, a number of web frameworks have popped up. We'll talk about these in a little more depth as we continue the book, but one in particular is well-received and very useful: the Gorilla web toolkit.
As the name implies, Gorilla is less of a framework and more of a set of very useful tools that are generally bundled in frameworks. Specifically, Gorilla contains:
gorilla/context: This is a package for creating a globally-accessible variable from the request. It's useful for sharing a value from the URL without repeating the code to access it across your application.gorilla/rpc: This implements RPC-JSON, which is a system for remote code services and communication without implementing specific protocols. This relies on the JSON format to define the intentions of any request.gorilla/schema: This is a package that allows simple packing of form variables into astruct, which is an otherwise cumbersome process.gorilla/securecookie: This, unsurprisingly, implements authenticated and encrypted cookies for your application.gorilla/sessions: Similar to cookies, this provides unique, long-term, and repeatable data stores by utilizing a file-based and/or cookie-based session system.gorilla/mux: This is intended to create flexible routes that allow regular expressions to dictate available variables for routers.- The last package is the one we're most interested in here, and it comes with a related package called
gorilla/reverse, which essentially allows you to reverse the process of creating regular expression-based muxes. We will cover that topic in detail in the later section.
Note
You can grab individual Gorilla packages by their GitHub location with a go get. For example, to get the mux package, going to github.com/gorilla/mux will suffice and bring the package into your GOPATH. For the locations of the other packages (they're fairly self-explanatory), visit http://www.gorillatoolkit.org/
Let's dive-in and take a look at how to create a route that's flexible and uses a regular expression to pass a parameter to our handler:
package main import ( "github.com/gorilla/mux" "net/http" ) const ( PORT = ":8080" )
This should look familiar to our last code with the exception of the Gorilla package import:
func pageHandler(w http.ResponseWriter, r *http.Request) {
vars := mux.Vars(r)
pageID := vars["id"]
fileName := "files/" + pageID + ".html"
http.ServeFile(w,r,fileName)
}Here, we've created a route handler to accept the response. The thing to be noted here is the use of mux.Vars, which is a method that will look for query string variables from the http.Request and parse them into a map. The values will then be accessible by referencing the result by key, in this case id, which we'll cover in the next section.
func main() {
rtr := mux.NewRouter()
rtr.HandleFunc("/pages/{id:[0-9]+}",pageHandler)
http.Handle("/",rtr)
http.ListenAndServe(PORT,nil)
}Here, we can see a (very basic) regular expression in the handler. We're assigning any number of digits after /pages/ to a parameter named id in {id:[0-9]+}; this is the value we pluck out in pageHandler.
A simpler version that shows how this can be used to delineate separate pages can be seen by adding a couple of dummy endpoints:
func main() {
rtr := mux.NewRouter()
rtr.HandleFunc("/pages/{id:[0-9]+}", pageHandler)
rtr.HandleFunc("/homepage", pageHandler)
rtr.HandleFunc("/contact", pageHandler)
http.Handle("/", rtr)
http.ListenAndServe(PORT, nil)
}When we visit a URL that matches this pattern, our pageHandler attempts to find the page in the files/ subdirectory and returns that file directly.
A response to /pages/1 would look like this:
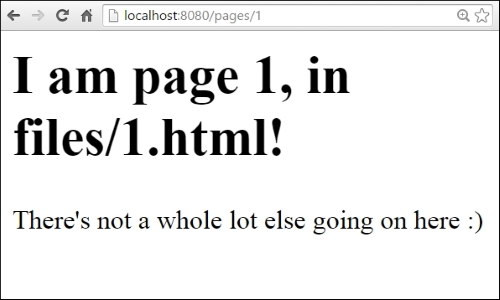
At this point, you might already be asking, but what if we don't have the requested page? Or, what happens if we've moved that location? This brings us to two important mechanisms in web serving—returning error responses and, as part of that, potentially redirecting requests that have moved or have other interesting properties that need to be reported back to the end users.
Before we look at simple and incredibly common errors like 404s, let's address the idea of redirecting requests, something that's very common. Although not always for reasons that are evident or tangible for the average user.
So we might we want to redirect requests to another request? Well there are quite a few reasons, as defined by the HTTP specification that could lead us to implement automatic redirects on any given request. Here are a few of them with their corresponding HTTP status codes:
- A non-canonical address may need to be redirected to the canonical one for SEO purposes or for changes in site architecture. This is handled by 301 Moved Permanently or 302 Found.
- Redirecting after a successful or unsuccessful
POST. This helps us to prevent re-POSTing of the same form data accidentally. Typically, this is defined by 307 Temporary Redirect. - The page is not necessarily missing, but it now lives in another location. This is handled by the status code 301 Moved Permanently.
Executing any one of these is incredibly simple in basic Go with net/http, but as you might expect, it is facilitated and improved with more robust frameworks, such as Gorilla.
At this point, it makes some sense to talk a bit about errors. In all likelihood, you may have already encountered one as you played with our basic flat file serving server, particularly if you went beyond two or three pages.
Our example code includes four example HTML files for flat serving, numbered 1.html, 2.html, and so on. What happens when you hit the /pages/5 endpoint, though? Luckily, the http package will automatically handle the file not found errors, just like most common web servers.
Also, similar to most common web servers, the error page itself is small, bland, and nondescript. In the following section, you can see the 404 page not found status response we get from Go:
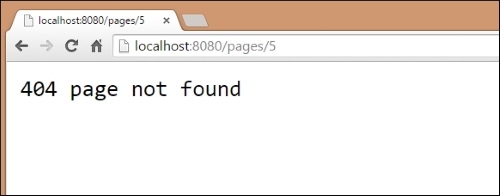
As mentioned, it's a very basic and nondescript page. Often, that's a good thing—error pages that contain more information or flair than necessary can have a negative impact.
Consider this error—the 404—as an example. If we include references to images and stylesheets that exist on the same server, what happens if those assets are also missing?
In short, you can very quickly end up with recursive errors—each 404 page calls an image and stylesheet that triggers 404 responses and the cycle repeats. Even if the web server is smart enough to stop this, and many are, it will produce a nightmare scenario in the logs, rendering them so full of noise that they become useless.
Let's look at some code that we can use to implement a catch-all 404 page for any missing files in our /files directory:
package main
import (
"github.com/gorilla/mux"
"net/http"
"os"
)
const (
PORT = ":8080"
)
func pageHandler(w http.ResponseWriter, r *http.Request) {
vars := mux.Vars(r)
pageID := vars["id"]
fileName := "files/" + pageID + ".html"_,
err := os.Stat(fileName)
if err != nil {
fileName = "files/404.html"
}
http.ServeFile(w,r,fileName)
}Here, you can see that we first attempt to check the file with os.Stat (and its potential error) and output our own 404 response:
func main() {
rtr := mux.NewRouter()
rtr.HandleFunc("/pages/{id:[0-9]+}",pageHandler)
http.Handle("/",rtr)
http.ListenAndServe(PORT,nil)
}Now if we take a look at the 404.html page, we will see that we've created a custom HTML file that produces something that is a little more user-friendly than the default Go Page Not Found message that we were invoking previously.
Let's take a look at what this looks like, but remember that it can look any way you'd like:
<!DOCTYPE html>
<html>
<head>
<title>Page not found!</title>
<style type="text/css">
body {
font-family: Helvetica, Arial;
background-color: #cceeff;
color: #333;
text-align: center;
}
</style>
<link rel="stylesheet" type="text/css" media="screen" href="http://code.ionicframework.com/ionicons/2.0.1/css/ionicons.min.css"></link>
</head>
<body>
<h1><i class="ion-android-warning"></i> 404, Page not found!</h1>
<div>Look, we feel terrible about this, but at least we're offering a non-basic 404 page</div>
</body>
</html>Also, note that while we keep the 404.html file in the same directory as the rest of our files, this is solely for the purposes of simplicity.
In reality, and in most production environments with custom error pages, we'd much rather have it exist in its own directory, which is ideally outside the publicly available part of our web site. After all, you can now access the error page in a way that is not actually an error by visiting http://localhost:8080/pages/404. This returns the error message, but the reality is that in this case the file was found, and we're simply returning it.
Let's take a look at our new, prettier 404 page by accessing http://localhost/pages/5, which specifies a static file that does not exist in our filesystem:
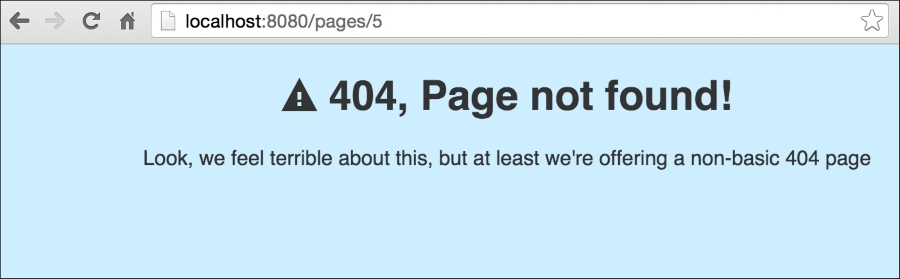
By showing a more user-friendly error message, we can provide more useful actions for users who encounter them. Consider some of the other common errors that might benefit from more expressive error pages.
We can now produce not only the basic routes from the net/http package but more complicated ones using the Gorilla toolkit. By utilizing Gorilla, we can now create regular expressions and implement pattern-based routing and allow much more flexibility to our routing patterns.
With this increased flexibility, we also have to be mindful of errors now, so we've looked at handling error-based redirects and messages, including a custom 404, Page not found message to produce more customized error messages.
Now that we have the basics down for creating endpoints, routes, and handlers; we need to start doing some non-trivial data serving.
In Chapter 3, Connecting to Data, we'll start getting dynamic information from databases, so we can manage data in a smarter and more reliable fashion. By connecting to a couple of different, commonly-used databases, we'll be able to build robust, dynamic, and scalable web applications.