

The first step in running and using a container on your server or laptop is to search and pull a Docker image from the Docker registry using the docker search command.
Let's search for the web server container. The command to do so is:
$ docker search httpd
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
httpd ... 1569 [OK]
hypriot/rpi-busybox-httpd ... 40
centos/httpd 15 [OK]
centos/httpd-24-centos7 ... 9
Alternatively, we can go to https://hub.docker.com/ and type httpd in the search window. It will give us something similar to the docker search httpd results:
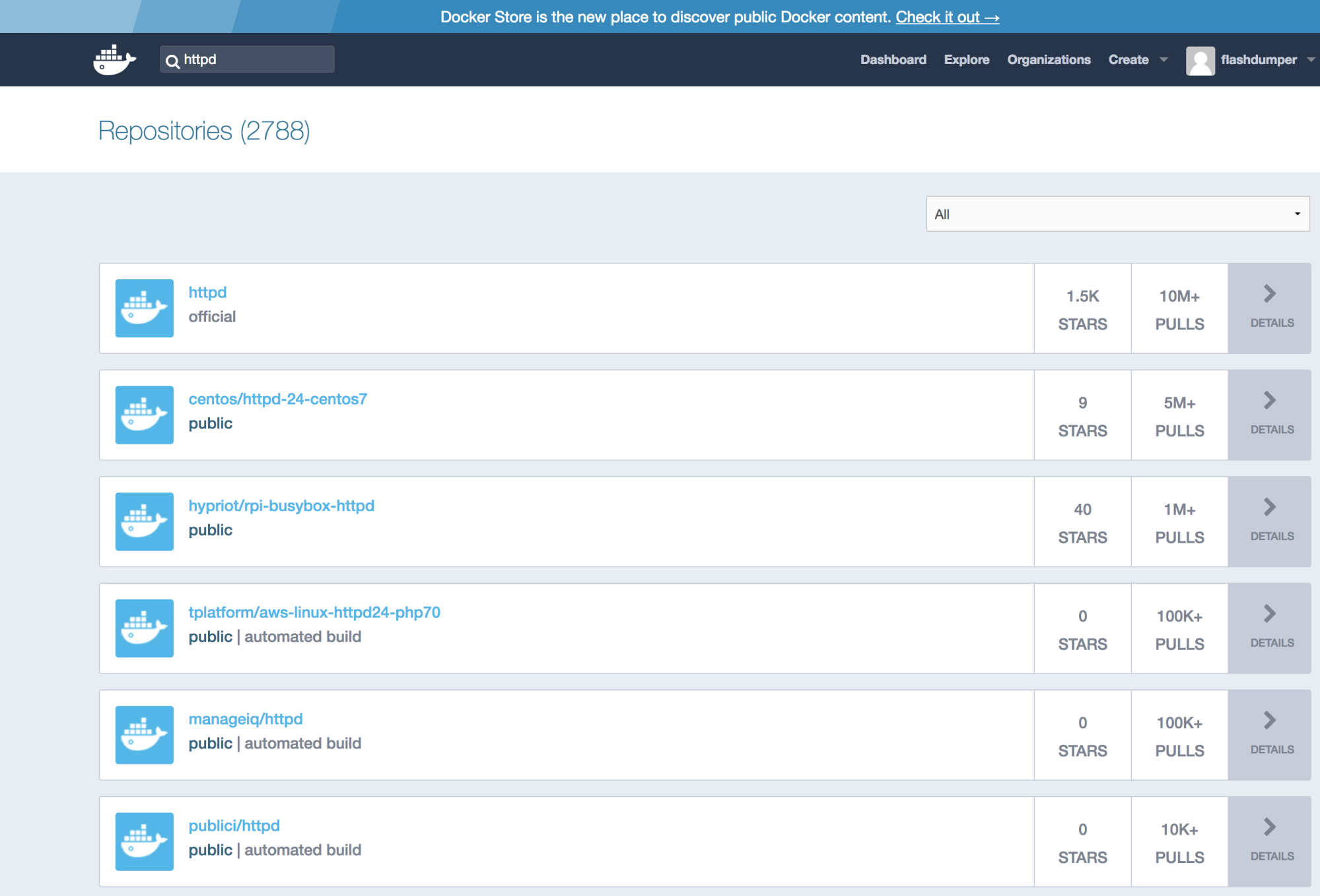
Once the container image is found, we can pull this image from the Docker registry in order to start working with it. To pull a container image to your host, you need to use the docker pull command:
$ docker pull httpd
The output of the preceding command is as follows:
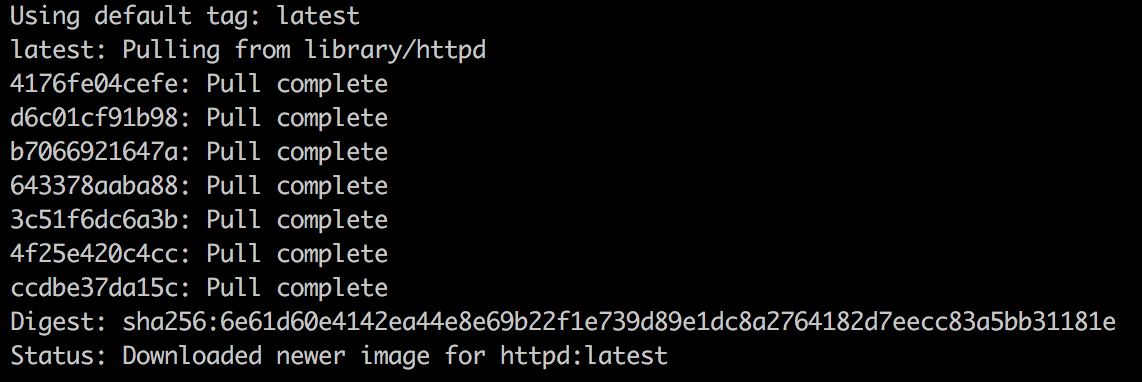
Note that Docker uses concepts from union filesystem layers to build Docker images. This is why you can see seven layers being pulled from Docker Hub. One stacks up onto another, building a final image.
By default, Docker will try to pull the image with the latest tag, but we can also download an older, more specific version of an image we are interested in using different tags. The best way to quickly find available tags is to go to https://hub.docker.com/, search for the specific image, and click on the image details:
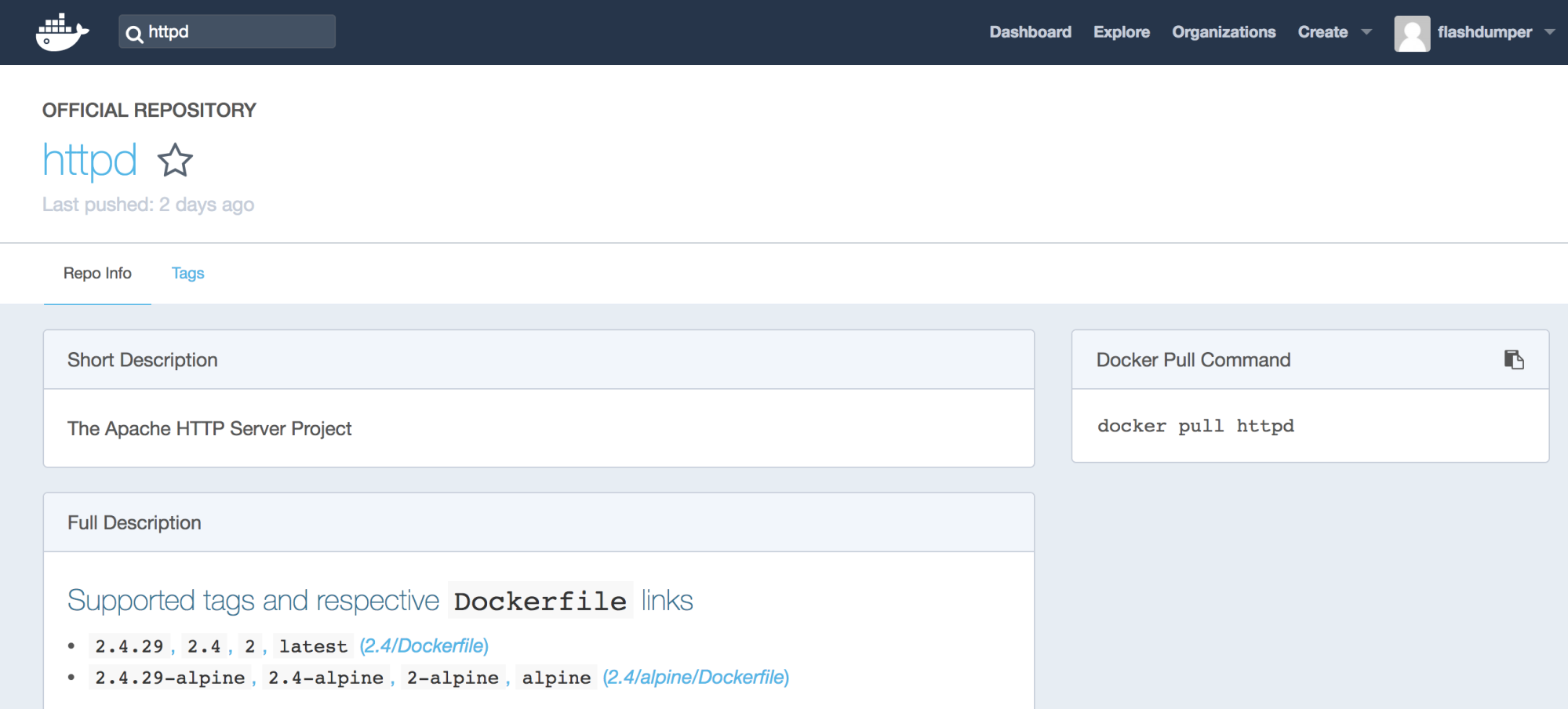
There we are able to see all the image tags available for us to pull from Docker Hub. There are ways to achieve the same goal using the docker search CLI command, which we are going to cover later in this book.
$ docker pull httpd:2.2.29
The output of the preceding code should look something like the following:
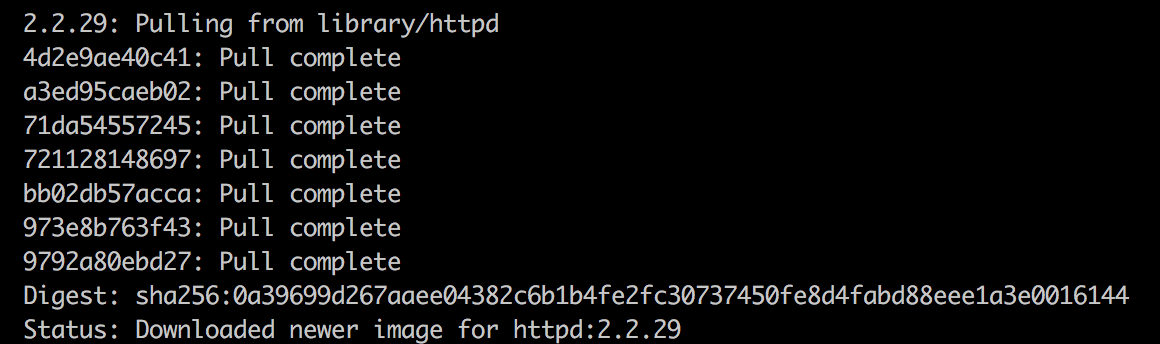
You may notice that the download time for the second image was significantly lower than for the first image. It happens because the first image we pulled (docker:latest) has most layers in common with the second image (httpd:2.2.29). So there is no need to download all the layers again. This is very useful and saves a lot of time in large environments.









