

Over the past decade, users have come to expect software to be highly intelligent when searching data. It is no longer enough to simply make searches case-insensitive, look for keywords as substrings, or other such basic SQL tricks.
Today, when a user searches the product catalog on an e-commerce site, he or she expects keywords to be evaluated across all the data points. Whether a term matches the model number of a computer or the ISBN of a book, the search should still find all the possibilities. To help the user sort through a large number of results, the search should be smart enough to somehow rank them by relevance.
A search should be able to parse words and understand how they might be connected. If you search for the word development, then the search should somehow understand that this is related to developer, even though neither of the words is a substring of the other.
Above all else, a search should be nice. When we post something in an online forum and mistake the words "there", "they're", and "their", people might only criticize our grammar. By contrast, a search should simply understand our typos and be cool about it! A search is at its best when it pleasantly surprises us, seeming to understand the real gist of what we're looking for better than we understood it ourselves.
The purpose of this book is to introduce and explore Hibernate Search, a software package for adding modern search functionality to our own custom applications, without having to invent it from scratch. Because coders usually learn best by looking at real code, this book revolves around an example application. We will stick with this application as we progress through the book, fleshing it out as new concepts are introduced in each chapter.
The true brain behind this search functionality is Apache Lucene, an open source software library for indexing and searching data. Lucene is an established Java project with a rich history of innovation, although it has been ported to other programming languages as well. It is widely adopted across a variety of industries, with high-profile users ranging from Disney to Twitter.
Lucene is often discussed interchangeably with Apache Solr, a related project. From one perspective, Solr is a standalone search server based on Lucene. However, the dependency relationship can flow both ways. Solr subcomponents are often bundled along with Lucene to enhance its functionality when embedded in other applications.
Note
Hibernate Search is a thin wrapper around Lucene and optional Solr components. It extends the core Hibernate ORM, the most widely adopted object/relational mapping framework for Java persistence.
The following diagram shows the relationship between all of these components:
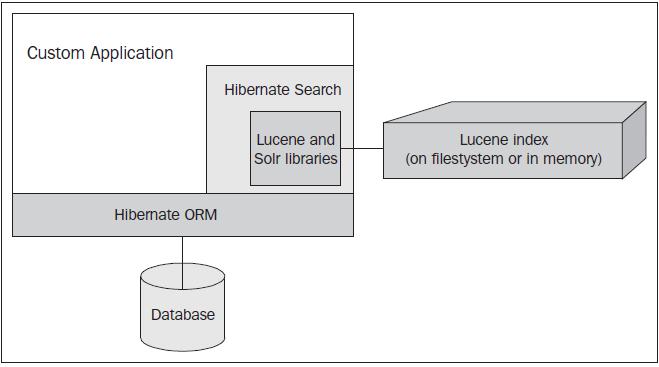
Ultimately, Hibernate Search serves two roles:
First, it translates Hibernate data objects into information that Lucene can use to build search indexes
Going in the other direction, it translates the results of Lucene searches into a familiar Hibernate format
From a programmer's perspective, he or she is mapping data with Hibernate in the usual way. Search results come back in the same form as normal Hibernate database queries. Hibernate Search hides most of the low-level plumbing with Lucene.
Chapter 1, Your First Application, dives straight away into creating a Hibernate Search application, an online catalog of software apps. We will create one entity class and prepare it for searching, then write a web application to perform searches, and display the results. We will walk through the steps for setting up the application with a server, a database, and a build system, and learn how to go about replacing any of those components with other options.
Chapter 2, Mapping Entity Classes, adds more entity classes to the example application, which are annotated to demonstrate the foundational concepts of Hibernate Search mapping. By the end of this chapter, you will understand how to map the most common entity classes for use with Hibernate Search.
Chapter 3, Performing Queries, expands the example application's queries, to make use of the new mappings. By the end of this chapter, you will understand the most common Hibernate Search query use cases. By this point, the example application will have enough functionality to resemble many production uses of Hibernate Search.
Chapter 4, Advanced Mapping, explains the relationship between Lucene and Solr analyzers, and how to configure an analyzer for more advanced searches. It also covers adjusting a field's weight in the Lucene index, and determines at runtime whether to index an entity at all. By the end of this chapter, you will understand how to fine tune entity indexing. You will have a taste of the Solr analyzer framework, and a grasp of how to explore its functionality on your own. The example application will now support searches that ignore HTML tags, and that find matches for related words.
Chapter 5, Advanced Querying, dives deeper into the querying concepts introduced in Chapter 3, Performing Queries, explaining how to get faster performance through projections and results transformation. Faceted searching is explored, as well as an introduction to the native Lucene API. By the end of this chapter, you will have a much more robust understanding of the querying functionality offered by Hibernate Search. The example marketplace application will now use more lightweight, projection-based searches, and have support for organizing the search results by category.
Chapter 6, System Configuration and Index Management, covers Lucene index management, and provides a survey of the advanced configuration options. This chapter dives into some of the more common options in detail, and provides enough background for us to explore others independently. By the end of this chapter, you will be able to perform standard management tasks on the Lucene index used by Hibernate Search, and we will understand the scope of additional functionality available to Hibernate Search through configuration options.
Chapter 7, Advanced Performance Strategies, focuses on improving the runtime performance of Hibernate Search applications, through code as well as server architecture. By the end of this chapter, you will be able to make informed decisions about how to scale a Hibernate Search application as necessary.
To use the example code covered in this book, you need a computer with a Java Development Kit version 1.6 or higher installed. You should also preferably have Apache Maven installed, or a Java IDE, such as Eclipse, which offers Maven embedded as a plugin.
The target audience for this book are Java developers who wish to add the search functionality to their applications. The discussion and code examples assume a basic understanding of Java programming. Prior knowledge of Hibernate ORM, the Java Persistence API (JPA 2.0), or Apache Maven would be helpful, but is not required.
In this book, you will find a number of styles of text that distinguish between different kinds of information. Here are some examples of these styles, and an explanation of their meaning.
Code words in text are shown as follows: "The id field is annotated with both @Id and @GeneratedValue".
A block of code is set as follows:
public App(String name, String image, String description) {
this.name = name;
this.image = image;
this.description = description;
}When we wish to draw your attention to a particular part of a code block, the relevant lines or items are set in bold:
@Column(length=1000)
@Field
private String description;Any command-line input or output is written as follows:
mvn archetype:generate -DgroupId=com.packpub.hibernatesearch.chapter1 -DartifactId=chapter1 -DarchetypeArtifactId=maven-archetype-webapp
Feedback from our readers is always welcome. Let us know what you think about this book—what you liked or may have disliked. Reader feedback is important for us to develop titles that you really get the most out of.
To send us general feedback, simply send an e-mail to <[email protected]>, and mention the book title through the subject of your message.
If there is a topic that you have expertise in and you are interested in either writing or contributing to a book, see our author guide on www.packtpub.com/authors.
Now that you are the proud owner of a Packt book, we have a number of things to help you to get the most from your purchase.
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
Although we have taken every care to ensure the accuracy of our content, mistakes do happen. If you find a mistake in one of our books—maybe a mistake in the text or the code—we would be grateful if you would report this to us. By doing so, you can save other readers from frustration and help us improve subsequent versions of this book. If you find any errata, please report them by visiting http://www.packtpub.com/support, selecting your book, clicking on the errata submission form link, and entering the details of your errata. Once your errata are verified, your submission will be accepted and the errata will be uploaded to our website, or added to any list of existing errata, under the Errata section of that title.
Piracy of copyright material on the Internet is an ongoing problem across all media. At Packt, we take the protection of our copyright and licenses very seriously. If you come across any illegal copies of our works, in any form, on the Internet, please provide us with the location address or website name immediately so that we can pursue a remedy.
Please contact us at <[email protected]> with a link to the suspected pirated material.
We appreciate your help in protecting our authors, and our ability to bring you valuable content.
You can contact us at <[email protected]> if you are having a problem with any aspect of the book, and we will do our best to address it.