

Writing code using a language supported by some interpreter that runs on the virtual machine simplifies things, as we can re-use the existing Java API directly. Most of the clients are written using "external" languages that then need to construct some wrapping layer over the HTTP protocol. This is interesting because the general approach is to try to reproduce the internal structure of the response, adding some object-oriented design and some facility class or syntactic sugar, when the language permits it. A practical example would be consuming JSON output.
The first place to start if you want to write your own client for interacting with Solr is generally writing some code to send parametric queries and consume results in XML or JSON. Constructing a request generally requires some simple composition of strings (for creating the correct URL request format) and some function calls to perform the HTTP request in itself. Consuming results can be simplified using some XML parser or DOM implementation for handling results, which is generally available for most programming languages. However, most of the languages are nowadays also offering support for a kind of direct binding to JSON due to its diffusion and simplicity.
For example, let's look at the following simple skeleton example in PHP:
$url = "http://localhost:8983/solr/paintings/select?q=*:*&rows=0&facet=on&facet.field="+field_name+"&wt=json&json.nl=map"; $content = file_get_contents($url); if($content) $result = json_decode($content,true); // handle results as an array...
In JavaScript, using jQuery style for simplicity, the preceding code looks as follows:
var url = "http://localhost:8983/solr/paintings/select?q=*:*&rows=0&facet=on&facet.field="+field_name+"&wt=json&json.nl=map"; $.getJSON(url, function(data) { var facets = data.facet_counts.facet_fields[field_name]; for(f in facets){ // handle facet f } });
Note how both these snippets construct the URL with string concatenation, and in both cases the JSON result can be parsed directly as a structured object that is generally an associative array (the specific type will depend on the language used), which is similar to the NamedList object in the Solr API. Approximately the same can be easily done in Groovy, Scala, Python, or the language that you prefer by using a third-party implementation of JSON at http://www.json.org/.
On the other hand, the XML format will probably remain the best choice if you need validation over a schema, or, for example, if you want to continue using libraries that already support it for the persistence layer.
Tip
Also note how the JavaBin serialization can be an interesting alternative format. This is intuitively useful while using a Java (or JVM compliant, via BSF) client, but there can be alternative implementations written directly using other languages to marshal the objects.
A brief introduction to the JavaBin marshalling is found on wiki: http://wiki.apache.org/solr/javabin, that also contains a two-liner example in Java.
The existing third-party clients for Solr, however, encapsulate the HTTP level as well as the parsing of a JSON or XML result. This way, they can offer a more appropriate object-oriented design to expose a simplifier and natural access to data.
The most interesting language to start with while searching for a Solr client is probably JavaScript, as it permits us to consume the Solr services directly into some kind of HTML visualization, if we need it. It is useful on the server side too if you plan to use server-side JavaScript interpreters, for example, Node.js. We already saw how it is possible to use JavaScript to consume a Solr Java object internally in an update workflow, or externally by calling the code from Java. And if we plan to use JavaScript to directly parse the XML or JSON results of some query and to construct queries too, we can do both from the client and the server side in pretty much the same way as with every service exposed on the Web, for example, the Twitter API.
If you look for some more structured libraries built on top of JavaScript, and are aware of the Solr services format, you can take a look at facetviews by Open Knowledge foundation (http://okfnlabs.org/facetview/) that supports both Solr and ElasticSearch, and ajax-solr by Evolving Web (https://github.com/evolvingweb/ajax-solr). The latter is the most known and mature HTML/JavaScript frontend for Solr, and I strongly suggest you have a look at it for your prototypes. You can easily start following the very good tutorial (https://github.com/evolvingweb/ajax-solr/wiki/reuters-tutorial) that will help you construct the same interface you can see in the demo (http://evolvingweb.github.io/ajax-solr/examples/reuters/index.html). The entire library is conceived to help you construct a Solr frontend with HTML and JavaScript, but you can, of course, use only the JavaScript part, if you plan to use it only for parsing data from / and to Solr. I have not done any tests of this, but it can be a good experimentation to do on the server side, for example, with node.js.
I have created a simple frontend for our own application that you can find in the /SolrStarterBook/test/chp06/html folder, just to give you a simple and (I hope) useful starting point. In the same directory, you will find a basic Solrstrap interface.
jcloud
is not directly designed for Solr, but I found it useful to create a funny tag cloud on the facets provided by Solr. The number of hits can be used to generate variance in the color and size of a term, for example, as in the following example named wordcloud.html:

The core code for the example in the preceding screenshot by an essential custom JavaScript that uses the jcloud and jQuery libraries is as follows:
function view(field_name, min, limit, invert){
var url = "http://localhost:8983/solr/arts/select?q=*:*...&wt=json";
$.getJSON(url, function(data) {
var facets = data.facet_counts.facet_fields[field_name];
var words = [];
for(f in facets){
search_link = "http://.../arts/select?q="+field_name+":"+f+"&wt=json";
w = {
text: normalize(f),
weight: Math.log(facets[f]*0.01),
html: {title: "search for \""+f+"\" ("+facets[f]+" documents)"},
link: search_link
},
words.push(w);
}
$("#"+field_name).jQCloud(words);
});
}
view("artist_entity", 3, 100);
...Note how the last line is simply a parameter call to the view() function. This function is internally and conceptually very similar to the structures of the code suggested before for handling facets. For every field used as a facet, the HTML part is prepared and then added to the corresponding box.
As you can imagine, the placeholder on which the data will be injected by the library is really simple:
<section id="artist_entity" class="wordcloud"><h1>artists</h1></section>
The idea behind many JavaScript libraries is to add the data formatted by a specific template with asynchronous calls at runtime.
Solrstrap
is a recent project, and aims to provide an automatic creation of faceting, built on top of an HTML5 one-page template with Boostrap, so that you only have to configure a few parameters in the companion JavaScript file. I have created a small, two-minute solrstrap.html example if you want to look at the code. The example will let you navigate through the data that is similar to the one shown in the following screenshot:

Looking at the following snippet of code, you will get an idea on the kind of configurations needed at the beginning of the JavaScript code:
var SERVERROOT = 'http://localhost:8983/solr/paintings/select/';
var HITTITLE = 'title';
var HITBODY = 'abstract';
var HITSPERPAGE = 20;
var FACETS = ['artist_entity','city_entity','museum_entity'];
...
var FACETS_TITLES = {'topics': 'subjects', 'city_entity':'cities', 'museum_entity':'museums', 'artist_entity':'artists'};For the HTML part, we will look at how the facets column template is created:
<script type="text/x-handlebars-template" id="nav-template">
<div class="facet">
<span class="nav-title" data-facetname="{{title}}">{{facet_displayname title}}</span><br>
{{#each navs}}
<a href='#' title='{{@key}} ({{this}})'>{{@key}}</a> ({{this}})<br/>
{{/each}}
</div>
</script>Also note how the code extracted from the HTML view is actually produced by a template written in JavaScript, so that it needs some reading before using it.
And finally, ajax-solr is the most structured library and has a modular design. There exists a main module that acts as an observer for Solr results, and you can plug into it some other specific module (they are called Widgets, thinking in the HTML direction) for handling suggestions while typing based on prefixed facets query, geospatial filters, or again, paged results.
We already saw what a simple example would look like. The following screenshot depicts it:
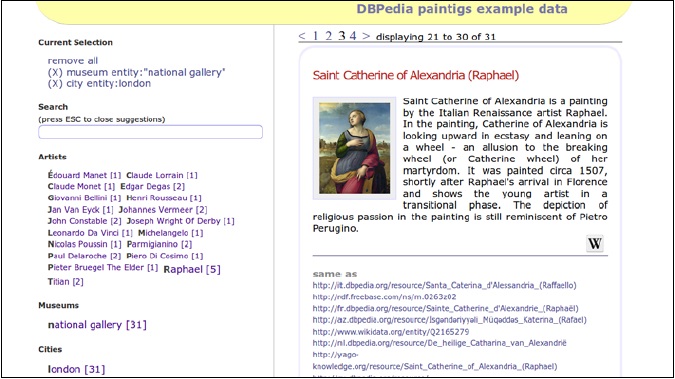
This library will require more working on the code in order to customize the behavior of different modules. The HTML placeholders will be very simple as usual:
<div class="tagcloud" id="artist_entity"></div>
A simplified version of the custom code required to use the different modules is similar to the following code:
// require.config(...);
var Manager = new AjaxSolr.Manager({
solrUrl : 'http://localhost:8983/solr/arts/'
});
Manager.addWidget(new AjaxSolr.ResultWidget({
id : 'result',
target : '#docs'
}));
var fields = [ 'museum_entity', 'artist_entity', 'city_entity' ];
for ( var i = 0, l = fields.length; i < l; i++) {
Manager.addWidget(new AjaxSolr.TagcloudWidget({
id : fields[i],
target : '#' + fields[i],
field : fields[i]
}));
}
Manager.init();
Manager.store.addByValue('q', '*:*');
var params = {
facet : true,
'facet.field' : [ 'museum_entity', 'artist_entity', 'city_entity' ],
'facet.limit' : 20,
'facet.mincount' : 1,
'f.city_entity.facet.limit' : 10,
'json.nl' : 'map'
};
for (var name in params) {
Manager.store.addByValue(name, params[name]);
}
Manager.doRequest();
As you can see in the preceding code, the main observer is the Manager object, which handles the current state of the navigation/search actions. The manager will store the parameters used inside a specific object (Manager.store), and will have methods for initializing and performing the query (Manager.init(), Manager.doRequest()). All the modules are handled by a specific widget, for example the TagCloudWidget object is registered for every field used as a facet. All the modules will be registered in the Manager object itself. In the example, we saw the TagCloudWidget and the ResultWidget classes, but there are others as well that are omitted for simplicity. The include statements for the various modules are handled in this case by the RequireJS library.
All these libraries adopt the jQuery convention, so it's really easy to bind their behavior to their HTML counterpart elements.
Solr provides a Ruby response format: http://wiki.apache.org/solr/Ruby%20Response%20Format. This is an extension of the JSON output, which is slightly adapted to be parsed correctly from Ruby.
However, if you want to use a more object-oriented client, there are some different options, and the most interesting one is probably Sunspot (http://sunspot.github.io/) which extends the Rsolr library with a DSL for handling Solr objects and services.
Sunspot permits you to index a Solr document with an ActiveRecords standard approach, and it's easy to plug it into an ORM system that is not even based on a database (for example, it can be used with filesystem objects with little code).
As for Ruby, there exists a Solr Python response, which is designed by extending the default JSON format: http://wiki.apache.org/solr/SolPython.
Sunburnt (http://opensource.timetric.com/sunburnt/index.html) is a good option if you want all the basic functionalities, and you can install it directly, for example, by using pip.
If you want to connect with Solr from a .NET application, you can look at SolrNET https://github.com/mausch/SolrNet. This library offers schema validation and a Fluent API that is easy to start from.
There is also a sample web application (https://github.com/mausch/SolrNet/blob/master/Documentation/Sample-application.md) that can be used as a starting reference for understanding how to use the basic features.
PHP is one of the most widely adopted languages for web development, and there exist several applications for frontends and CMS, as well as several popular web frameworks built with it. Solr has a PHP response format that exposes results in the usual serialization format that PHP uses for arrays, simplifying the parsing of the results.
There is also an available PECL module: http://php.net/manual/en/book.solr.php, which can be easily adopted in any site or web application development to communicate to an existing Solr instance. This module is an object-oriented library that is designed to map most of the Solr concepts as well as the independent, third-party library Solarium (http://www.solarium-project.org/).
Drupal is a widely adopted open search CMS built with a modular, power platform that permits content-type creation and management. It has been adopted for building some of the biggest portals on the Web, such as The Examiner (http://www.examiner.com/) or the White House (http://www.whitehouse.gov/) sites. When the existing Apache Solr plugin (https://drupal.org/project/apachesolr) is enabled and correctly configured, it is possible to search over the contents and use faceted search with taxonomies.
There is also a Search API Solr search module (https://drupal.org/project/search_api_solr), which actually shares default schema.xml or solrconfig.xml files with ApacheSolr. Since Drupal 8, it's possible to merge the two approaches into a single effort.
If you are using WordPress (http://wordpress.org/) for building your site, or if you are using it as a CMS for adopting a combination of modules, you should know that it is possible to replace the internal default search with an advanced search module (http://wordpress.org/plugins/advanced-search-by-my-solr-server/) that is able to communicate with an existing Solr instance.
Magento is a very popular e-commerce platform (http://www.magentocommerce.com/), built in PHP on top of the excellent Zend framework. It exists in different editions, from open source to commercial, and it offers a module for Solr that can be easily configured (http://www.magentocommerce.com/knowledge-base/entry/how-to-use-the-solr-search-engine-with-magento-enterprise-edition) to add full-text and faceted navigation over the products catalog.
There are also a few platforms that should be cited in this list, as they are designed to use Solr for document indexing, rich full-text search, or as a step in the content-enhancement process. It is important to notice that the internal workflow that we have seen in action in the update chain is one of the most discussed features for future improvements. In particular, there exist some different hypotheses for improving the update chain (http://www.slideshare.net/janhoy/improving-the-solr-update-chain), adopting a configurable and general-purpose document-processing pipeline.
Hydra is a document-processing pipeline (http://findwise.github.io/Hydra/), and is useful for improving the quality of the data extracted from free text, and then to send it to Solr.
Apache's Unstructured Information Management applications (UIMA), http://uima.apache.org/) is a framework for information-extraction from text, providing capabilities for language detection, sentence segmentation, part of speech tagging, Named Entity extraction, and more. We already know that UIMA can be integrated into an update processor chain in Solr, but it's also possible to move in the opposite direction, by integrating Solr as a UIMA CAS component (http://uima.apache.org/sandbox.html#solrcas.consumer).
Apache Stanbol is a platform designed to provide a set of components for semantic content management (http://stanbol.apache.org/). The platform offers content enhancement for textual content, reasoning over the augmented semantic contents, manipulation of knowledge models, and persistence of the augmented data.
A typical scenario would involve, for example, the indexing of a controlled vocabulary or authority file, the creation of a Solr index that can be plugged as one of the platform processors into an internal enhancement chain, and exposing the annotations of recognized, named entities by a specific RESTful service.
One of the main objectives of Stanbol services is providing semantic enhancements by recognizing and annotating the named entities for CMS contents. For example, WordLift (http://wordlift.it/) is a WordPress plugin that can be used within a common WordPress installation, helping us to add annotations for connecting our contents on the linked data cloud.
Carrot2 (http://project.carrot2.org/) is a document-clustering platform. It provides the Java API for embedding the engine into a Java application, a server that exposes REST services, and a standalone web application. We have yet used the latter for a visual exploration of the Solr results cluster. This can also be very useful for analyzing our data collection and identifying critical aspects that may require some different configuration.
Vufind (http://vufind.org/downloads.php) is an open platform for OPAC (Online Public Access Catalog), which internally includes an Solr local installation (SolrMARC, with support for MARC and OAI formats), while the web interface is mostly written in PHP.
If you are interested in handling OPAC or a similar use case, there is an old but interesting case study: http://infomotions.com/blog/2009/01/fun-with-webservicesolr-part-i-of-iii/ that explains how to use an OAI metadata harvester and index the metadata on Solr using Perl. I also suggest reading the very interesting How to Implement A Virtual Booksheld with Solr, by Naomi Dushay and Jessie Keck (http://www.stanford.edu/~ndushay/code4lib2010/stanford_virtual_shelf.pdf).
Q1. How can we write custom client code to talk to Solr?
We can write a new library with almost all the languages, wrapping the HTTP calls
We can use the SolrJ library, using Java or another JVM-supported language
We cannot use external libraries to communicate with Solr
Q2. What are the differences between an embedded Solr instance and a remote one?
If using SolrJ we can use the same API in both cases
A remote Solr instance needs to use external libraries to talk to the Solr instance on which the data is stored
An embedded Solr instance wraps the reference to a core on the same virtual machine, while the HTTP instance wraps a core on a remote virtual machine, hiding the HTTP calls
Q3. Using the Bean Scripting Framework from Apache we can use the SolrJ library with other programming languages. Is that true?
Yes, we can write our client with every language, using SolrJ and BSF
Yes, we can write our client using SolrJ, BSF, and every language which is supported on BSF
No, while we can write custom code to communicate with Solr via HTTP with every language, BSF currently supports only JavaScript