

Before I started to write this chapter (or maybe before beginning to write this book) I thought about how to deal with this subject. Firstly, because I would guess this was one of your expectations. Secondly, because this is a subject that is present in almost every literature, and I do not want to (and do not intend to) inflame this discussion.
The truth is that the discussion towards the theory versus practice, and until now in my life, I have favored the practical side. Therefore, I investigated, searched many different sources where I could read more about the subject, and maybe bring to this book a summary of everything that has been written until now on this subject.
Much that I have found at the beginning of my research showed me a clear separation between database design and data modeling. However, in the end, my conclusion was that both concepts have more similarities than divergences. And, to reach this conclusion, I had as stating point a fact mentioned by C.J. Date in An Introduction to Database Systems, Pearson Education.
In it, C.J. Date says that he prefers not to use the term data modeling because it could be refer to the term data model, and this relation may cause a little confusion. C.J. Date reminds us that the term data model has two meanings in the literature. The first is that a data model is a model of data in general, the second is that a data model is a model of persistent data relating to a specific enterprise. Date has chosen the first definition in his book.
As C.J. Date stated:
"We believe that the right way to do database design in a nonrelational system is to do a clean relation design first, and then, as a separate and subsequent step, to map that relational design into whatever nonrelational structures (for example. hierarchies) the target DBMS happens to support."
Therefore, talking about database design is a good start. So, C.J. Date adopted the term semantic modeling, or conceptual modeling, and defined this activity as an aid in the process of database design.
Tip
If you want to know more, you can find it in An Introduction to Database Systems, 8th Edition, Chapter 14, page 410.
Another important source that I found, which in some way complements the C.J. Date argumentation, is publications made by Graeme Simsion on The Data Administration Newsletter, http://www.tdan.com and in the book Data Modeling: Theory and Practice, Technics Publications LLC. Graeme Simsion is a data modeler, author of two data modeling books, and a researcher at Melbourne University.
In the vast majority of publications Simsion addresses the database design and data modeling subjects and concludes that data modeling is a discipline of database design and, consequently, the data model is the single and most important component of the design.
We notice that, unlike C.J. Date, Graeme Simsion uses the term data modeling.
In one of this publications, Simsion brings us an important fact regarding the data modeling concepts as a part of the process of database design. He talks about the stages of database design and tries to explain it by using some historic facts, and by a research with people who are directly involved with data modeling.
From the historic point of view, he mentioned the importance of 3-schema architecture on the evolution of data modeling concepts.
To understand this evolution, we have to go back in time to 1975. In that year, the Standards Planning and Requirements Committee of the American National Standards Institute also known as ANSI/SPARC/X3 Study Group on Data Base Management Systems, led by Charles Bachman, published a report proposing a DBMS architecture.
This report introduced an abstract architecture of DBMS that would be applicable for any data model—that is, a way that multiples the user's views and perceives the data.
The 3-schema architecture was developed to describe a final product, a database, not the process to design one. However, as previously mentioned, the 3-schema architecture introduced concepts that directly impact on the database design process including data modeling. In the next section we will go through the 3-schema architecture concepts to better understand data modeling concepts.
The ANSI-SPARC architecture proposed using three views (or three schemas) in order to:
Hide the physical storage implementation from the user
Ensure that the DBMS will give users access to the same data consistently, which means all users have with their own view
Allow the database administrator to change something in the physical level without affecting the user's view
The external level, also known as the user view, details how each particular user sees the database. This level allows each user to view the data in a different way. For that reason, it is also the appropriate level to keep information about a user's specific requirements. The external schema describes how a database is structured for different user views. So, we can have many external schemas for a database.
The conceptual level, despite being considered by many as the most important level, was the last level to arise in the architecture. This level aims to show how a database is logically structured. We can say that it is an abstract view of the data stored within the database.
The conceptual level acts as a layer between the user view and the database implementation. Therefore, in this level, details about the physical implementation and particularities about user views are not considered.
Once conceptual level is here, the database administrator has an important role in this architecture level where we have a database global view. It is their responsibility to define the logical structure.
A very interesting thing about the conceptual level is that we have to keep in mind that this level is independent from hardware or software. The conceptual schema defines the logical data structure as well as the relationships between the data in the database.
The internal level represents how the data is stored. This schema defines physical storage structures such as indexes, data fields, and representations. There is only one internal schema for a database, but it is possible that there are many internal schemas for a conceptual schema.

The ANSI/SPARC/X3 database architecture
The introduction of the concepts demonstrated by Charles Bachman and the ANSI/SPARC/X3 members were very meaningful. They brought a new way to see the database and introduced concepts that helped to develop the data modeling discipline.
As we stated before, data modeling can no longer be seen as a separate process. It is a stage in the database design process and a step that has to be done together with a business analysis. As the final result of the modeling process, we should have the logical data model.
This modeling process raises the controversial question of which approach we use. The core of this discussion deals with what is academic or what we see in practice.
To Matthew West and Julian Fowler, one way to see the modeling process is shown in the following diagram:

The data modeling process
Graeme Simsion has an entire article about this discussion. The article shows how the academic view of the modeling process is different than the real-life view. Both give names to the modeling stages, which are quite different.
During the writing process of this chapter, I am trying to present not only the Simsion research but also everything I have been through since I started working with information systems, in conjunction with extensive research about the modeling concepts, along with the countless views that I saw in many other sources.
Moreover, as previously stated, and also observed by Simsion, the three schema ANSI-SPARC architecture played a key role in the formation of the base concepts we have today. With the dissemination of the relational model and the DBMS based on it, the need to support old database architectures such as hierarchical and network-based has passed. Nevertheless, the way we divide the modeling process in two stages, one reflecting concepts very close to user views and followed by an automatic translation to a conceptual schema, remained.
We can say that the stages of the data modeling process we know nowadays came from the 3-schema architecture. Not only on the concepts, but also the names we use to noun each stage.
Hence, we most commonly find three types of data models: the conceptual model, logical model, and physical model.
The conceptual model is a map of the entities and relationships with some attributes to illustrate. This is a high-level, abstract view, with the objective of identifying the fundamental concepts, very close to how users perceive the data, not focusing on a particular idea of the business.
If our audience is the business guys, that is the right model. It is frequently used to describe universal domain concepts, and should be DBMS-independent. For instance, we can mention entities such as person, store, product, instructor, student, and course.
Both in academic literature and in practice, the use of a relational notation is widely used to represent the conceptual model, even though the target implementation is not a relational DBMS. Indeed, this is a good approach to follow, as C.J. Date stated.
A common graphical representation of the conceptual model is the popular "crow's foot notation".

Crow's foot notation
It is often said that it is best practice to limit the conceptual model to printing on one page. The conceptual model can be a diagram or just a document describing everything you have identified.
The logical model is the one that will be more business-friendly. This model should also be DBMS-independent, and is derived from the conceptual model.
It is common to describe business requirements in this model. Consequently, at this time, the data modeler will focus more on the project's scope. Details such as cardinality and nullability of relationship attributes with data types and constraints are mapped on this model too. As well as the conceptual model, is common to use a relational notation to represent the logical model. A data modeler has to work more on the logical model. This is because the logical model is where the modeler will explore all his possibilities and different ideas.
Generally, the logical model is a graphical presentation. The most widely used is the entity-relationship (ER) model, presented by Peter Chen in 1976. The ER model has a graphical notation that fits all the needs of a logical model.
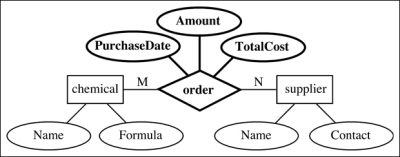
An entity-relationship diagram
The physical model is a model where we have more detailed and less generic information about the data. In this model, we should know which technology should be used. Here, we can include tables, column names, keys, indexes, security roles, validation rules, and whatever detail you as a data modeler think is necessary.
Just to make the connection to the three-schema architecture clear, the physical model is in some way linked to the internal level on the architecture because it is in this level that we deal with how the stored data is represented to the user. The goal of this stage is to have an implemented database.