

Apache Solr can utilize HDFS to index and store its indices on the Hadoop system. It does not utilize MapReduce-based framework for indexing. The following diagram shows the interaction pattern between Solr and HDFS. You can read more details about Apache Hadoop at http://hadoop.apache.org/docs/r2.4.0/.
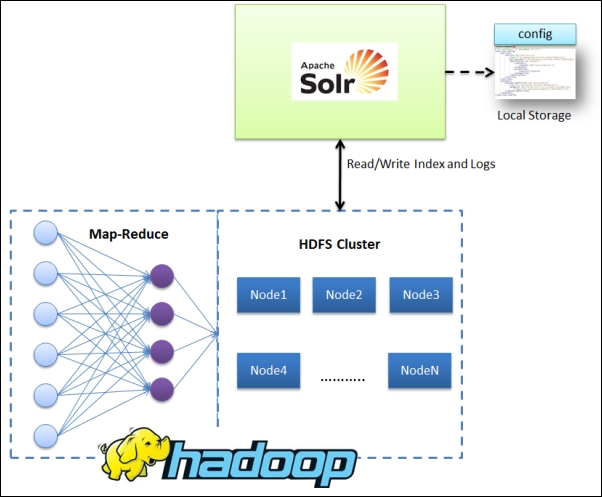
Let's understand how this can be done:
To start with, the first and most important task is getting Apache Hadoop set up on your machine (proxy node configuration) or setting up a Hadoop cluster. You can download the latest Hadoop tarball or ZIP from http://hadoop.apache.org. The newer generation Hadoop uses advanced MapReduce (also known as yarn).
Based on the requirement, you can set up a single node (http://hadoop.apache.org/docs/r<version>/hadoop-project-dist/hadoop-common/SingleCluster.html) or a cluster setup (http://hadoop.apache.org/docs/r<version>/hadoop-project-dist/hadoop-common/ClusterSetup.html).
Typically, you will be required to set up the Hadoop...