

The Teradata database provides various effective ways to improve the performance of a query. Indexes are the most important part of designing the database structure. Indexes not only provide an effective way to store data, but also help in determining effective access paths to data.
The commonly used indexes in Teradata are:
- Unique/non-unique primary index (UPI/NUPI)
- Unique/non-unique secondary index (USI/NUSI)
- Partitioned primary index (PPI)
- Join index (JI)
Think of an index as a two-field table: one contains a value, and the other a pointer to instances of that value in a data table:
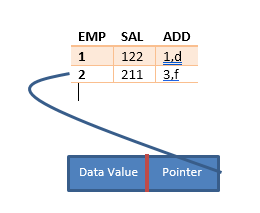
Teradata is the relation database management system, RDBMS, which uses hashing to distribute rows across the AMPs; the value is added into an entity called a row hash, which is used as the pointer. The row hash is addressed to the value in the table. The Teradata RDBMS uses this row hash address as a retrieval index.
The following are characteristics of indexes:
- An index is used not only to distribute...