

In this section, we will look at how Apex applications are specified by the user. Apex applications can be written in a number of ways, using different APIs. We will introduce the Java-based lower-level compositional API, the more recently added high-level stream API, and the ability to define pipelines with SQL.
Later in this book, we will also look at how applications developed with Apache Beam can be executed with the Apex engine. Each of these varied source specifications are ultimately translated into a logical Apex Directed Acyclic Graph (DAG), which is then provided to the Apex engine for execution.
An Apex application is represented by a DAG, which expresses processing logic as operators (vertices) and streams (edges). Streams are unbounded sequences of pieces of data, also called events or tuples. The logic that can be executed is arranged in the DAG in sequence or in parallel.
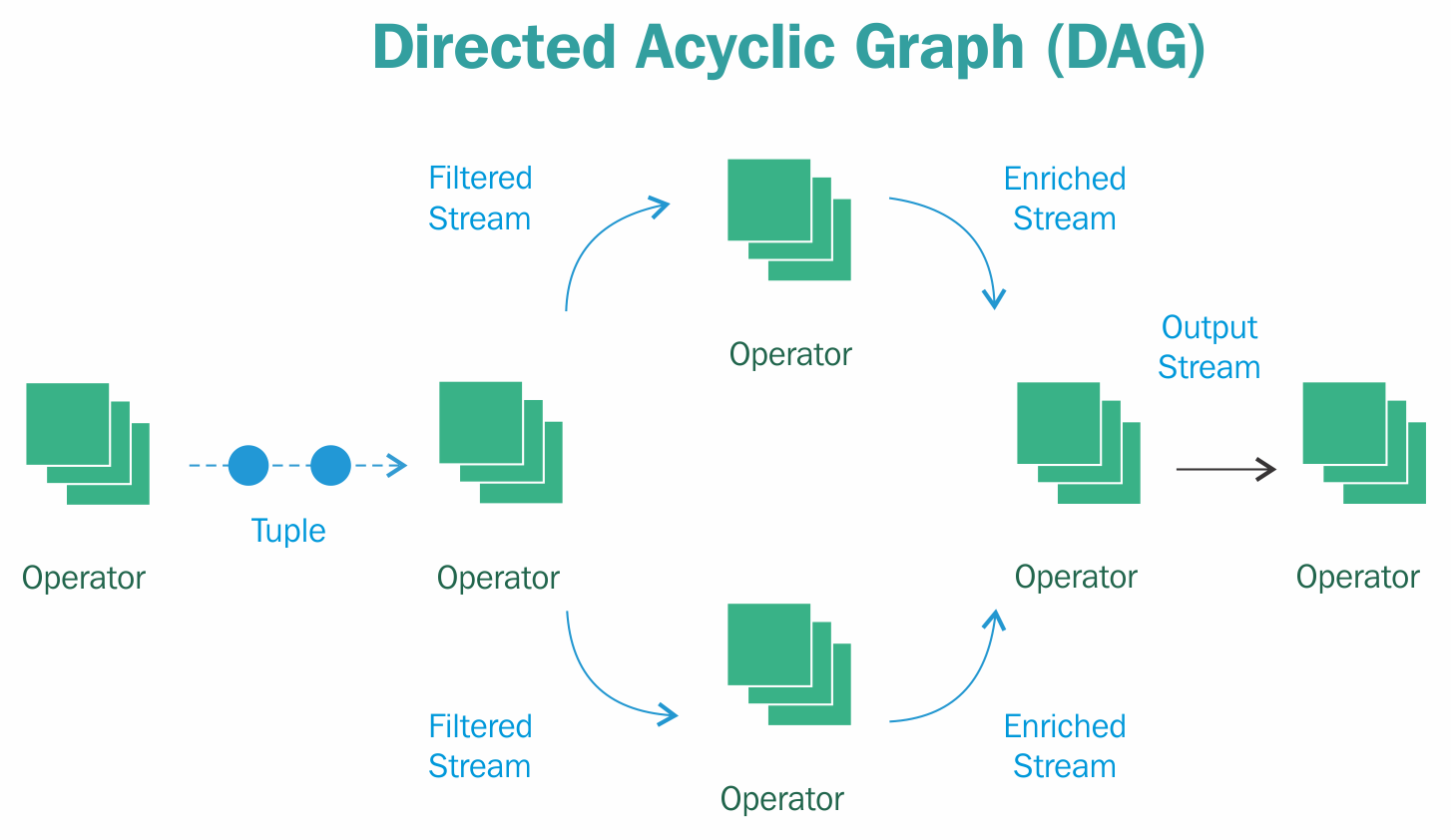
The resulting graph must be acyclic, meaning that any given tuple is processed only once by an operator. An exception to this is iterative processing, also supported by Apex, whereby the output of an operator becomes the input of a predecessor (or upstream operator), introducing a loop in the graph as far as the streams are concerned. This construct is frequently required for machine learning algorithms.
The concept of a DAG is not unique to Apex. It is widely used, for example to represent the history in revision control systems such as Git. Several projects in the Hadoop ecosystem use a DAG to model the processing logic, including Apache Storm, Apache Spark, and Apache Tez. Apache Beam pipelines are represented as a DAG of transformations and each of the streaming engines that currently offer Beam runners also have a DAG as their internal representation.
Operators are the functional building blocks that can contain custom code specific to a single use case or generic functionality that can be applied broadly. The Apex Malhar library (to be introduced later) contains reusable operators, including connectors that can read from various sources, provide filtering or transformation functionality, or output to various destinations:
The flow of data is defined through streams, which are connections between ports. Ports are the endpoints of operators to receive data (input ports) or emit data (output ports). Each operator can have multiple ports and each port is connected to at most one stream (ports can also be optional, in which case they don't have to be connected in the DAG). We will look at ports in more detail when discussing operator development. For now, it is sufficient to know that ports provide the type-safe endpoints through which the application developer specifies the data flow by connecting streams. The advantage of using ports versus just a single process and emit method on the operator is that the type of tuple or record is explicit and, when working with a Java IDE, the compiler will show type mismatches as compile errors.
In the following subsections, we will introduce the different APIs that Apex offers to develop applications. Each of these representations is eventually translated into the native DAG, which is the input required by the Apex engine to launch an application.
The low-level DAG API is defined by the Apex engine. Any application that runs on Apex, irrespective of the original specification format, will be translated into this API. It is sometimes also referred to as compositional, as it represents the logical DAG, which will be translated into a physical plan and mapped to the execution layer by the Apex runtime.
The following is the Word Count example application, briefly introduced in the Stream Processing section earlier written with the DAG API:
LineReader lineReader = dag.addOperator("input", new LineReader());
Parser parser = dag.addOperator("parser", new Parser());
UniqueCounter counter = dag.addOperator("counter", new UniqueCounter());
ConsoleOutputOperator cons = dag.addOperator("console", new
ConsoleOutputOperator());
dag.addStream("lines", lineReader.output, parser.input);
dag.addStream("words", parser.output, counter.data);
dag.addStream("counts", counter.count, cons.input); The developer implements a method that is provided with a DAG handle by the engine (in this case, dag) through which operators are added and then connected with streams.
As mentioned, the Apex library provides many prebuilt operators. Operators can also be custom and encapsulate use case specific logic, or they can come from a library of an organization to share reusable logic across applications.
The DAG API is referred to as low level because many aspects are explicit. The developer identifies the operators and is aware of the ports for stream connections. In the case of larger applications, the wiring code can become more challenging to navigate. At the same time, the DAG API offers the most flexibility to the developer and is often used in larger projects that typically involve significant operator development and customization and where the complexity of wiring the DAG is normally not a concern.
The high-level Apex Stream Java API provides an abstraction from the lower level DAG API. It is a declarative, fluent style API that is easier to learn for someone new to Apex. Instead of identifying individual operators, the developer works with methods on the stream interface to specify the transformations.
The API will internally keep track of the operator(s) needed for each of the transformations and eventually translate it into the lower level DAG. The high-level API is part of the Apex library and outside of the Apex engine.
Here is the Word Count example application written with the high-level API (using Java 8 syntax):
StreamFactory.fromFolder("/tmp")
.flatMap(input -> Arrays.asList(input.split(" ")), name("Words"))
.window(new WindowOption.GlobalWindow(),
new
TriggerOption().accumulatingFiredPanes().withEarlyFiringsAtEvery(1))
.countByKey(input -> new Tuple.PlainTuple<>(new KeyValPair<>(input, 1L)),
name("countByKey"))
.map(input -> input.getValue(), name("Counts"))
.print(name("Console"))
.populateDag(dag); Windowing is supported and stateful transformations can be applied to a windowed stream, as shown with countByKey in the preceding code listing. The individual windowing options will be explained later in the Windowing and time section, as they are applicable in a broader context.
In addition to the transformations that are directly available through the Stream API, the developer can also use other (possibly custom) operators through the addOperator(..) and endsWith(..) methods. For example, if output should be written to JDBC, the connector from the library can be integrated using these generic methods instead of requiring the stream API to have a method like toJDBC.
The ability to add additional operators is important, because not all possible functionality can be baked into the API and larger projects typically require customizations to operators or additional operators that are not part of the Apex library. Additionally, there are many connectors available as part of the library, each with its own set of dependencies and, sometimes, these dependencies and connectors may conflict. In this situation it isn't practical or possible to add a method for each connector to the API. Instead, the developer needs to be able to plug-in the required connector and use it along with the generally applicable transformations that are part of the Stream API.
It is also possible to extend the Stream API with custom methods to provide new transformations without exposing the details of the underlying operator. An example for this extension mechanism can be found in the API unit tests.
Note
For readers interested to explore the API further, there is a set of example applications in the apex-malhar repository at https://github.com/apache/apex-malhar/tree/master/examples/highlevelapi.
The Stream API is relatively new and there are several enhancements planned, including expansion of the set of windowed transforms, watermark handling, and custom trigger support. The community is also discussing expanding the language support to include a native API for Scala and Python.
SQL is widely used for data transformation and access, not only with traditional relational databases but also in the Apache big data space with projects like Hive, Drill, Impala, and several others. They all let the user process bounded data at rest using familiar SQL syntax without requiring other programming skills. SQL can be used for ETL purposes but the most common use is for querying data, either directly or through the wide range of SQL compatible BI tools.
Though it has been in use in the Hadoop space for years, SQL is relatively new in the stream processing area as a declarative approach to specify a streaming application. Apex is using Apache Calcite for its SQL support, which has already been adopted by many other big data processing frameworks. Instead of every project coming up with its own declarative API, Calcite aims to make SQL the common language. Calcite accepts standard SQL, translates it into relational algebra, facilitates query planning and optimization to physical plan and allows for integration of any data source that can provide collections of records with columns (files, queues, and so on).
There are different use cases for Calcite, including ETL, lookups, search, and so on. With unbounded data sources, the processing of SQL becomes continuous and it is necessary to express windows on the stream that define boundaries at which results can be computed and emitted. Calcite provides streaming SQL extensions to support unbounded data (https://calcite.apache.org/docs/stream.html).
The initial SQL support in Apex covers select, insert, inner join, where clause and scalar functions. Endpoints (sources and sinks) can be files, Kafka or streams that are defined with the DAG API (fusion style) and CSV is supported as a data format.
Here is a simple example to illustrate the translation of SQL into an Apex DAG:
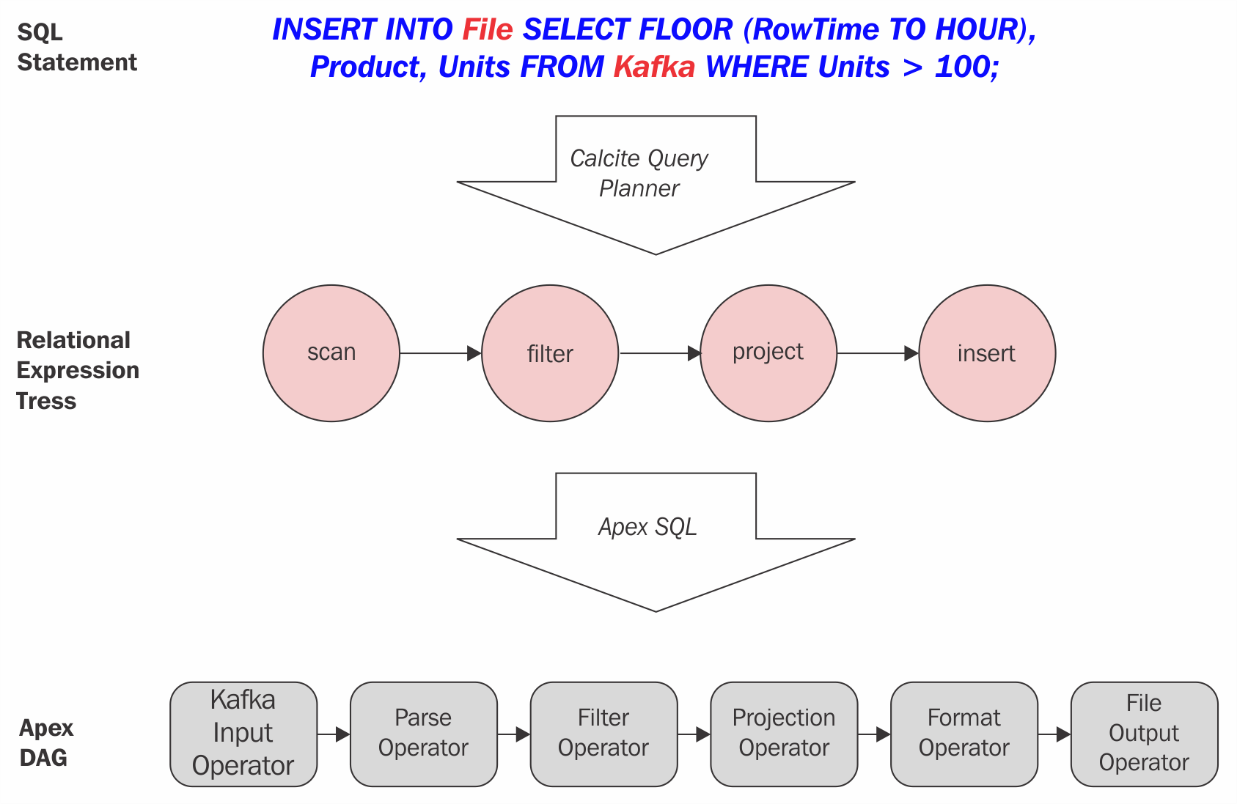
Translation of SQL into Apex DAG
Note
For more information, you can visit http://apex.apache.org/docs/malhar/apis/calcite/.
The community is working on the support for windowed transformations (required for aggregations), which will be based on the scalable window and accumulation state management of the Apex library (refer to Chapter 3, The Apex Library).
Another way of assembling applications without writing Java code is through JSON.
This format can be created manually, but it could also be used to generate the DAG from a different frontend, like a visual tool. Here is the word count written in JSON:
{
"displayName": "WordCountJSON",
"operators": [
{ "name": "input", ... }, { "name": "parse", ... },
{
"name": "count",
"class": "com.datatorrent.lib.algo.UniqueCounter",
"properties": { "com.datatorrent.lib.algo.UniqueCounter": { "cumulative":
false } }
},
{ "name": "console", ... } ],
"streams": [
{ "name": "lines",
"sinks": [ { "operatorName": "parse", "portName": "input" } ],
"source": { "operatorName": "input", "portName": "output" }
},
{ "name": "words", ... },
{ "name": "counts", ... }
]
} Just like applications that are written in Java, the JSON files will be included in the application package, along with the operator dependencies. Upon launch of the application, the Apex client will parse these files and translate them into a native DAG representation.
Streams of unbounded data require windowing to establish boundaries to process data and emit results. Processing always occurs in a window and there are different types of windows and strategies to assign individual data records to windows.
Often, the relationship of data processed and time is explicit, with the data containing a timestamp identifying the event time or when an event occurred. This is usually the case with streaming sources that emit individual events. However, there are also cases where time can be derived from a container. For example, when data arrives batched in hourly files, time may be derived from the file name instead of individual records. Sometimes, data may arrive without any timestamp, and the processor at the source needs to assign a timestamp based on arrival time or processing time in order to perform stateful windowed operations.
The windowing support provided by the Apex library largely follows the Apache Beam model. It is flexible and broadly applicable to different use cases. It is also completely different from and not to be confused with the Apex engine's native arrival time based streaming window mechanism.
The streaming window is a processing interval that can be applied to use cases that don't require handling of out-of-order inputs based on event time. It assumes that the stream can be sliced into fixed time intervals (default 500 ms), at which the engine performs callbacks that the operator can use to (globally) perform aggregate operations over multiple records that arrived in that interval.
The intervals are aligned with the internal checkpointing mechanism and suitable for processing optimizations such as flushing files or batching writes to a database. It cannot support transformation and other processing based on event time, because events in the real world don't necessarily arrive in order and perfectly aligned with these internal intervals. The windowing support provided by the Apex library is more flexible and broadly applicable, including for processing based on event time with out-of-order arrival of events.
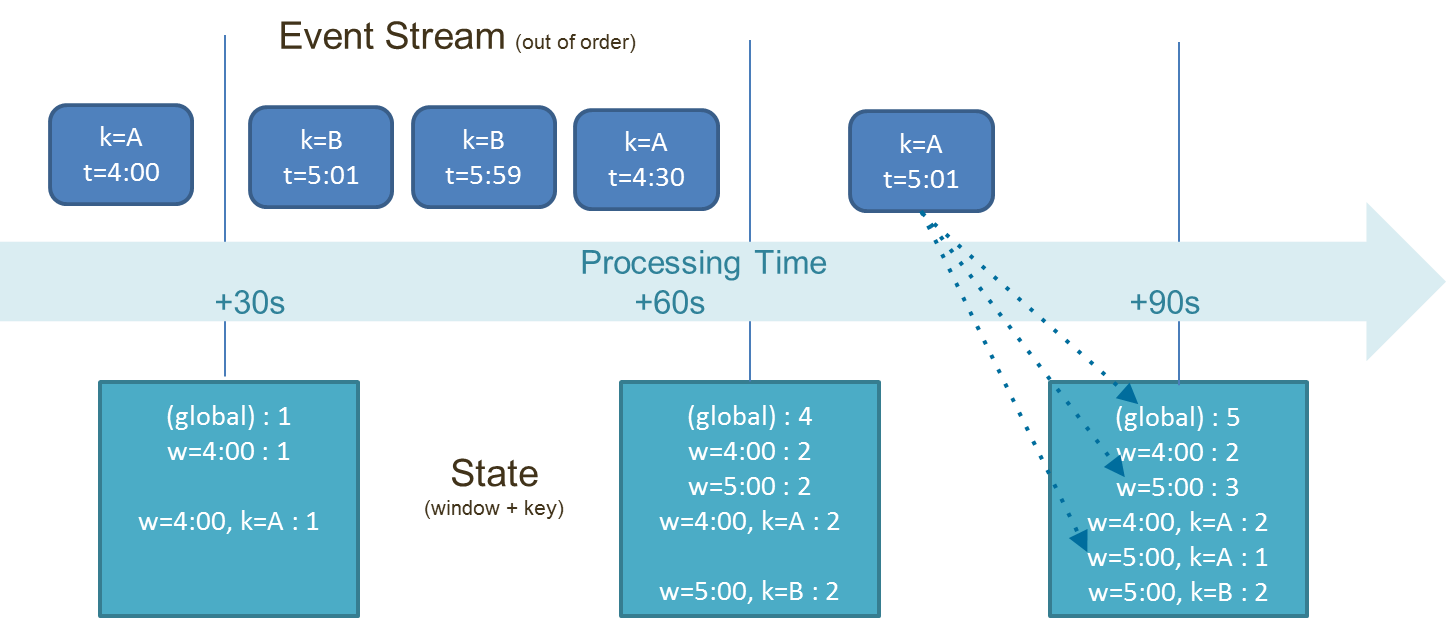
The preceding example shows a sequence of events, each with a timestamp (t) and key (k) and their processing order. Note the difference between processing and event time. It should be possible to process the same sequence at different times with the same result. That's only possible when the transformations understand event time and are capable maintaining the computational state (potentially multiple open windows at the same time with high key cardinality). The example shows how the state tracks multiple windows (w). Each window has an associated timestamp (4:00 and 5:00 and global for a practically infinite window) and accumulates its own counts regardless of processing time based on the timestamps of the events (and optionally by key).