

The premise for using Beam (and Apex) is that you are processing some massive datasets and/or data streams, so massive that they cannot be processed by conventional means on a single machine. You will need a fleet of computers and a programming model that somewhat automatically scales out to saturate all of your computers.
In Beam, you organize your processing into a directed graph called a pipeline. You may illustrate it something like this:
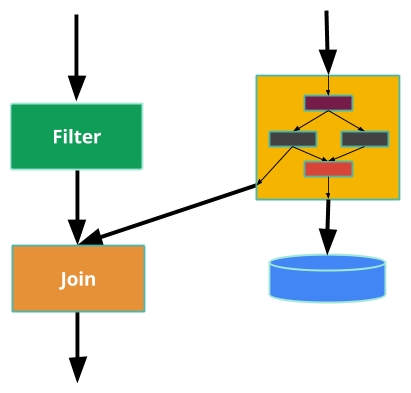
The boxes are parallel computations that are called PTransforms. Note how one of the boxes contains a small subgraph—almost all PTransforms are actually encapsulated subgraphs, including both Join and Filter. The arrows represent your data flowing from one PTransform to another as a PCollection. A PCollection can be bounded as with a classic static dataset like a massive collection of logs or a database snapshot. In this case, it is finite and you know it. However, a PCollection can just as easily...