

So far, we have only used built-in functions to operate on DataFrame columns. While these are often sufficient, we sometimes need greater flexibility. Spark lets us apply custom transformations to every row through user-defined functions (UDFs). Let's assume that we want to use the equation that we derived in Chapter 2, Manipulating Data with Breeze, for the probability of a person being male, given their height and weight. We calculated that the decision boundary was given by:
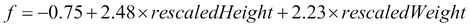
Any person with f > 0 is more likely to be male than female, given their height and weight and the training set used for Chapter 2, Manipulating Data with Breeze (which was based on students, so is unlikely to be representative of the population as a whole). To convert from a height in centimeters to the normalized height, rescaledHeight, we can use this formula:
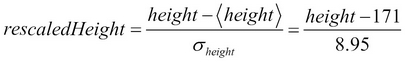
Similarly, to convert a weight (in kilograms) to the normalized weight, rescaledWeight, we can use:
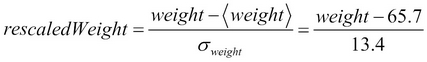
The average and standard...