

Spark ML is a nickname for the DataFrame-based MLLib API. Spark ML is the primary library now, and the RDD-based API has been moved to maintenance mode.
Let's first understand some of the basic concepts in Spark ML. Before that, let's quickly go over how the learning process works. Following are the steps:
- A machine learning algorithm is provided a training dataset along with the right hyperparameters.
- The result of training is a model. The following figure illustrates the model building by applying machine learning algorithm on training data with hyperparameters:
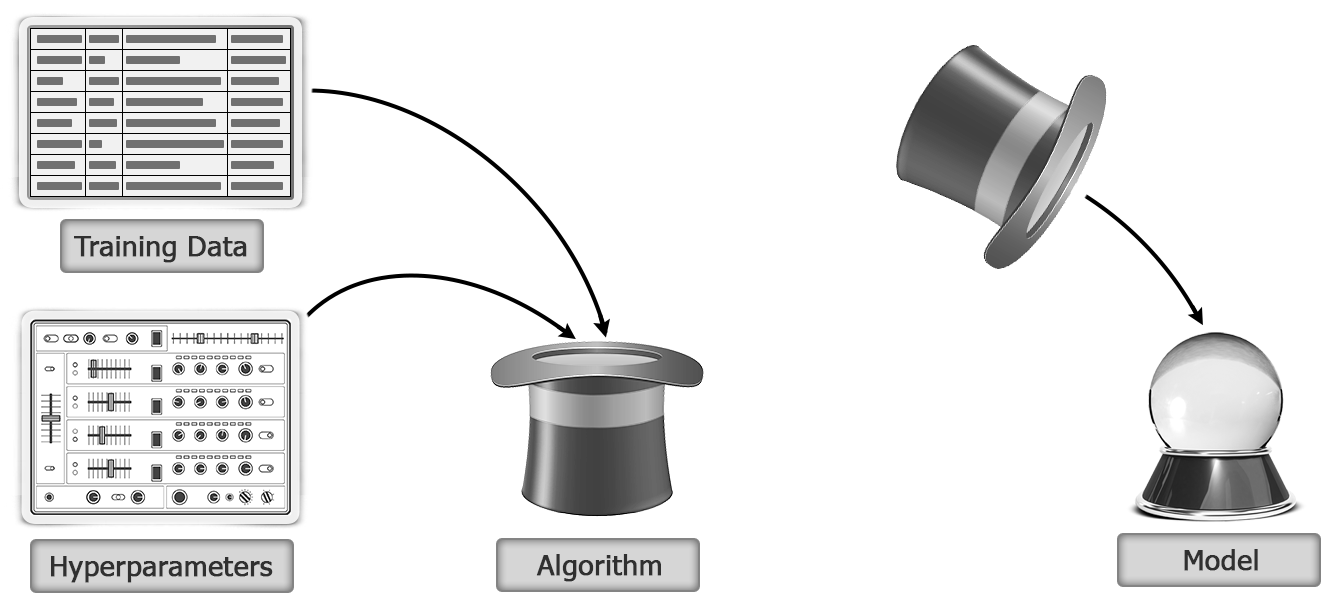
- The model is then used to make predictions on test data as shown here:

In Spark ML, an estimator is provided as a DataFrame (via the fit method), and the output after training is a Transformer:
Now, the Transformer takes one DataFrame as input and outputs another transformed (via the transform method) DataFrame. For example, it can take a DataFrame with the test data and enrich this DataFrame with...