

There are many paths an OpenStack troubleshooter can follow when attempting to resolve an issue. It is worth arguing that there is more than one way to approach any troubleshooting problem. Operators and administrators will need to find a methodology that works well for them and the context in which they operate. With this in mind, I would like to share a methodology that I have found useful when working with OpenStack, specifically the following methodologies:
Services: Confirm that the required services are up and running.
Authentication: Ensure that authentication is properly configured.
CLI Debug: Run the CLI commands in the debug mode, looking for errors.
Execute the request against the API directly, looking for issues.
Check Logs: Check log files for traces or errors.
I have found that working through these steps when troubleshooting OpenStack will yield useful clues that will help identify, isolate, and resolve issues.
There are many tools available when troubleshooting OpenStack. In the following sections, we will cover a few of the tools that we leverage frequently. I would recommend that you add these to your toolbox if you are not already using them.
OpenStack is deployed in a Linux environment; therefore, administrators can leverage popular Linux tools when troubleshooting. If you are an experienced Linux administrator, you should be comfortable with most of these tools, and you should find that your existing Linux experience will serve you well as you troubleshoot OpenStack. In this section, we will walk you through some of the more common tools that are used. We will explain how each tool can be leveraged in an OpenStack environment specifically, but if you are interested in learning how the tools work generally, much can be learned by researching each tool on the Internet.
OpenStack runs several processes that are critical to its smooth operation. Understanding each process can be very helpful to quickly identify and resolve problems in your cluster. It is not uncommon for the source of your problems to be rooted in the fact that a process has died or not started successfully. Bringing your cluster back to health may be as simple as restarting the necessary process. As we tackle each OpenStack project, we will introduce you to the key processes for that project's service. Like any Linux process, there are several commands that we can leverage to check these processes. Some of the common commands that we will leverage are detailed in the following sections.
Hopefully, the ps command is already familiar to you as a Linux administrator. We leverage this command in OpenStack to get a snapshot of the current processes running on our host machines. The command will quickly allow us to see which OpenStack processes are running, and more importantly when troubleshooting, which OpenStack processes are not running.
We typically use the ps command with the standard -aux options and then pipe that to grep in order to find the OpenStack process we are interested in:
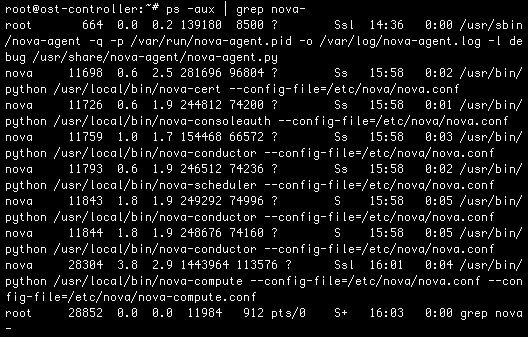
For example, the preceding code would list each of the OpenStack Nova processes, which, by convention, are prefixed with nova-. It's also worth pointing out that this command may also reveal the —log- file option set when the process was launched. This will give you the location of the log files for each process, which will be extremely valuable during our troubleshooting.
In addition to the ps command that is used to look at processes, you can also leverage the pgrep command. This command allows you to look up processes based on a pattern. For example, you can list processes based on their names:
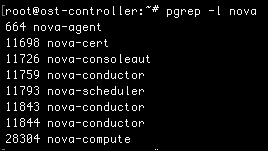
This command will list all the processes that have nova in their name. Without the -l option, the command would only list the process ID. If we want to see the process name too, we simply add -l. If you'd like to see the full-line output like we saw with ps, then you can add the -a option. With this option, you will be able to see extra attributes that are used when starting the process, including log file locations.
Along with the pgrep command, there is the pkill command. This command allows you to kill processes that match the name pattern that you provide. Take a look at the following as an example:

The preceding command would kill the process with PID 20069. This can be useful in situations where you have process hanging and you need to restart them. This is an alternative to the standard kill command.
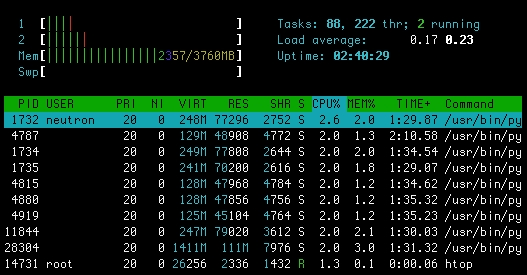
While ps and pgrep provide us with a snapshot of the running processes, top and htop will give us an interactive view of our processes. The top and htop commands are very similar, but htop provides you with a little added interface sugar, including the ability to scroll data. You may need to install htop on your servers if you decide to use it. Using either of these commands, you will be able to see the processes interactively sorted by things, such as percentage of CPU used by the process or percentage of memory. If you find your cluster in a situation where there is resource contention on the host, this tool can begin to give you an idea of which process to focus on first. The following screenshot is a sample output from htop:
It's likely you will need to troubleshoot an issue that is related to hard drives when dealing with OpenStack. You can leverage standard Linux tools to interrogate the hard drive and assist you in troubleshooting.
There will be several moments in our OpenStack journey where we will be concerned about storage and the hard drives in our cluster that provide some of that storage. The df command will be leveraged to report on the disk space used by our filesystem. We can add the -h option to make the values human readable:
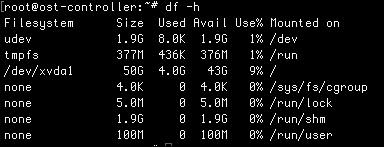
The output from this command tells us which filesystems are currently mounted and provides usage information for each, such as the size of the filesystem, the amount used, and the amount available. The command also tells us the mount point for each filesystem.
In addition to df, we will leverage fdisk. The fdisk command allows us to work with the disk partition tables. This may become necessary when troubleshooting OpenStack Block Storage or working with images in OpenStack. Take the following code as an example:
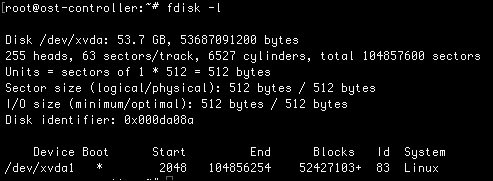
The preceding command will list the partition table. From the list, you can see the details about the disk, including its name and size. You can also see which partitions correspond to the disk. In addition to listing the partition table, you can also modify the partitions.
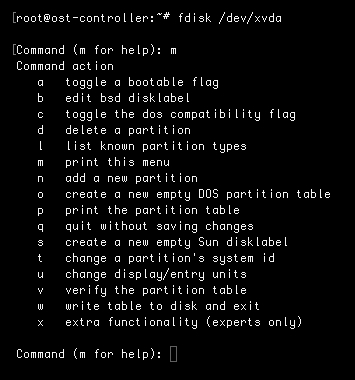
This command will allow you to change the partition table for the disk named /dev/xvda. After running this command, type m to see the menu of commands. Using this menu, you can create new partitions, delete existing ones, or change existing partitions.
As we will discover later in this book, there are some use cases where you can't use fdisk. In those situations, we will look to another partitioning tool named parted. This tool also allows us to work with partitions. With parted, we can create, resize, copy, move, and delete partitions. The parted tool allows you to work with many different types of filesystems as compared to fdisk.
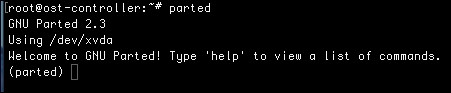
The preceding command will start the parted tool. Once the tool starts, you can type help in the prompt to see a list of menu items. Some of the functionalities listed include makefs, to make filesystems; and makepart, to make a partition; or makepartfs, to make both at the same time.
