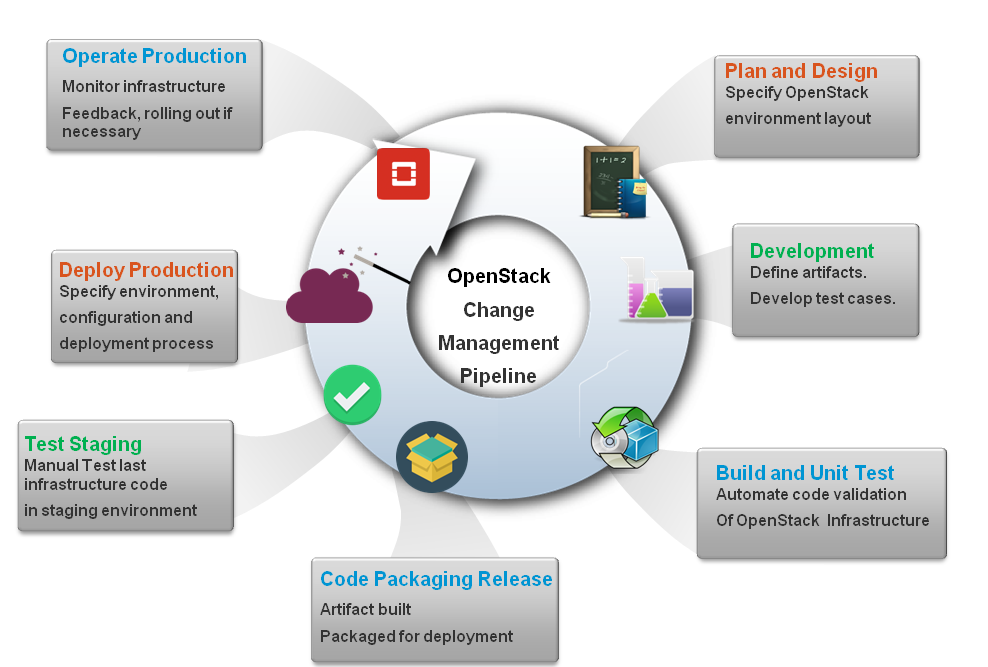
The next wizard will guide you through a simple OpenStack setup in a local virtualized environment. As described in the previous section, we will distribute different service roles for each virtual machine. Note that a test environment should reflect a logical design of a proper production setup. In this example, several services have been encapsulated into a single node while this approach should be refined more. As a start, and for the sake of simplicity, the common services of OpenStack and the infrastructure will be distributed as follows:
- Cloud controller: This will run most of the OpenStack services, including computing services (excluding the hypervisor computing service, nova-compute), object and block storage, image, identity, dashboard, and network services. In addition, common shared infrastructure services will be installed in the same host, including database, message queueing, and load balancing services.
- Compute node: It will simply run the compute service nova-compute and network agents.
- Ansible deployment host: This will store the OSA playbook's repository and Ansible daemons.

Automating the operating system installation saves a lot of time, and eventually, the usage of Vagrant empowers the automation of tests. When getting more involved in extending the code of the OpenStack infrastructure, automating tests using local virtualized infrastructure might catch problems quickly. For the rest of the setup, we will rely on the Vagrant file that defines the nodes in our OpenStack environment. Let's start by defining the Ansible Deployment Host.
To start with, create a new Vagrant file named Vagrantfile:
Vagrant.configure(2) do |config|
config.vm.box = "ubuntu/trusty64"
First, we define the operating system version that will be used for the whole deployment test environment. As we discussed previously, the Linux flavor selected for OSA is Ubuntu.
The next chunk of the Vagrant file defines the Ansible Deployment host that is assigned as a adh variable as well as the hostname:
# Ansible Deployment Host
config.vm.define :adh do |adh|
adh.vm.hostname= "adh"
adh.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--memory", "1024"]
vb.customize ["modifyvm", :id, "--cpus", "2"]
vb.customize ["modifyvm", :id, "--nicpromic2", "allow-all"]
end
end
The next section of the Vagrant file will define the Cloud Controller node name, its customized resources, and network setup:
# Cloud Controller Host
config.vm.define :cc do |cc|
cc.vm.hostname= "cc"
cc.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--memory", "3072"]
vb.customize ["modifyvm", :id, "--cpus", "3"]
vb.customize ["modifyvm", :id, "--nicpromic2", "allow-all"]
end
end
The last part of the Vagrant file defines the Compute Node name, its customized resources, and network setup:
# Compute Node
config.vm.define :cn do |cn|
cn.vm.hostname= "cn"
cn.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--memory", "4096"]
vb.customize ["modifyvm", :id, "--cpus", "4"]
vb.customize ["modifyvm", :id, "--nicpromic2", "allow-all"]
end
end
end
It is recommended to run the Vagrant file part by part. This will help us diagnose any configuration issue or syntax error during the vagrant run. To do this, it is possible to comment the Cloud Controller and Compute Node code blocks in the Vagrant file:
- We can start by running the first Ansible Deployment Host block and running the following command line:
# vagrant up
This will download the Ubuntu image and create a new virtual machine named adh.
- The first virtual machine should be up and running with the Ubuntu image installed:
# vagrant ssh
- Next step requires you to download and install the required utilities as mentioned in the previous section, including the Git, NTP, and SSH packages as follows:
ubuntu@adh: $ sudo apt-get install aptitude build-essential git ntp ntpdate openssh-server python-dev sudo
- We will use the latest stable master branch of the OSA repository:
ubuntu@adh: $ git clone
https://github.com/openstack/openstack-ansible.git /opt/openstack-ansible
To use a previous OpenStack release, instruct your Git command line to clone the openstack-ansible repository from the desired branch of the OpenStack release code name:
$ git clone -b stable/OS_RELEASE
https://github.com/openstack/openstack-ansible.git /opt/openstackansible where OS_RELEASE refers to the OpenStack release name. Please note that openstack-ansible repository does not include all the previous OpenStack releases and keeps at maximum the four latest releases.
- A file located at /etc/openstack_deploy/openstack_user_config.yml will need to tweak it a bit in order to reflect the customized environment setup described previously. We will need to specify the network IP ranges and nodes that will be running services attached to their interfaces:
- First, specify that CIDRs will be used for our OpenStack test environment:
---
cidr_networks:
management: 172.16.0.0/16
tunnel: 172.29.240.0/22
used_ips:
- 172.16.0.101,172.16.0.107
- 172.29.240.101,172.29.240.107
The tunnel network defined in the cidr_networks stanza defines a tunneled network using VXLAN by tenant or project in OpenStack.
-
- We can add a new section to specify where the common infrastructure services, such as the database and messaging queue, will be running. For the sake of simplicity, they will run on the same Cloud Controller node, as follows:
# Shared infrastructure parts
shared-infra_hosts:
controller-01:
ip: 172.16.0.101
-
- The next part will instruct Ansible to run the rest of the OpenStack services and APIs in the Cloud Controller machine as follows:
# OpenStack infrastructure parts
os-infra_hosts:
controller-01:
ip: 172.16.0.101
-
- Optionally, network and storage services can run on the same Cloud Controller node as follows:
# OpenStack Storage infrastructure parts
storage-infra_hosts:
controller-01:
ip: 172.16.0.101
# OpenStack Network Hosts
network_hosts:
controller-01:
ip: 172.16.0.101
-
- Add the following section to instruct Ansible to use the Compute Node to run the nova-compute service:
# Compute Hosts
compute_hosts:
compute-01:
ip: 172.16.0.104
-
- The last part of our initial configuration setup for the test environment will include specifying where to wrap the OpenStack cluster behind the load balancer. For this purpose, HAProxy will be used and installed in the Cloud Controller node, as follows:
haproxy_hosts:
haproxy:
ip: 172.16.0.101
- Next, we can edit another simple file that describes specific OpenStack configuration options located at /et/openstack_deploy/user_variables.yml. For now, we will need to configure Nova to use qemu as a virtualization type. We can also adjust the allocation ratio for both RAM and CPU, as follows:
--------
## Nova options
nova_virt_type: qemu
nova_cpu_allocation_ratio: 2.0
nova_ram_allocation_ratio: 1.0
--------
- The final configuration file that we need to edit is /etc/openstack-deploy/user_secrets.yml. This is where root users passphrases for services such as database and compute will be stored once they are created in Keystone. The following script will enable us to generate a random passphrase and store for later use in future setup:
# scripts/pw-token-gen.py --file /etc/openstack-deploy/user_secrets.yml
- Now we have our development machine in place with the required preconfigured files. We can continue running the rest of the vagrant file to prepare the Cloud Controller and Compute Node hosts. To do this, uncomment the Cloud Controller and Compute Node and run the following command line:
# vagrant up
- The OSA exposes a bootstrap script that allows you to download the right version of Ansible and generate a wrapper openstack-ansible script that will load the OpenStack user variable:
# scripts/bootstrap-ansible.sh
- Once completed successfully, the openstack-ansible script will be used to run the playbooks. The first run will install and configure the containers in the mentioned nodes described in /etc/openstack_deploy/openstack_user_config.yml. The first playbook will be running is setup-hosts.yml, located under /opt/deploy-openstack/playbooks:
# openstack-ansible setup-hosts.yml
This will identify the target hosts, validate network configurations, and create loopback volumes for use per LXC container.
- The next playbook run should instruct Ansible to install HAProxy in the Cloud Controller node by running haproxy-install.yml:
# openstack-ansible haproxy-install.sh
- If the previous step has been completed with no failure, it means that Ansible did not face any connectivity issue to reach the nodes. Then, we can easily proceed to run the next playbook that will configure LXC containers to install common OpenStack services, such as database and messaging queue services. By default, Galera and RabbitMQ will be installed. OSA provides a playbook named setup-infrastructure.yml to make this happen, as follows:
# openstack-ansible setup-infratructure.yml
- The next step will configure LXC containers and install the OpenStack core services across the Cloud Controller and Compute Node as follows. The playbook to run is named setup-openstack.yml:
# openstack-ansible setup-openstack.yml
- Once completed, it is possible to list all the service containers using the following command line from the Ansible Deployment Host:
# lxc-ls --fancy
- From the previous output, identify the container prefixed as utility_container-XXX. This is a particular container that includes the OpenStack client command lines. Use the lxc-attach tool to connect the Cloud Controller utility container as follows:
# lxc-attach --name cc_utility_container-55723a11
----
* Documentation: https://help.ubuntu.com/
Last login: Mon Sep 12 22:56:33 2016 from 172.29.236.100
root@utility-container-55723a11:~#
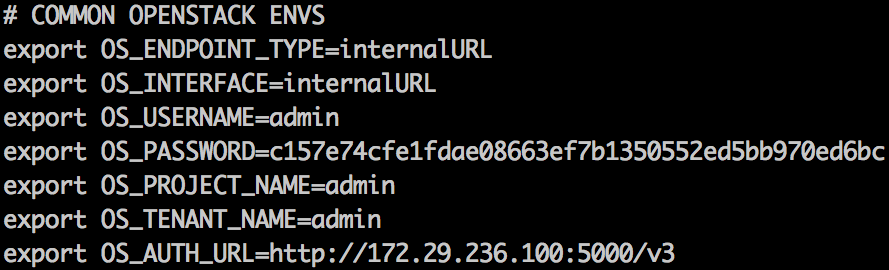
- Now propagate the OpenStack credentials in the environment and also use the generated username/password for admin to access the Horizon dashboard:
root@utility-container-55723a11:~# cat openrc
root@utility-container-55723a11:~# source openrc
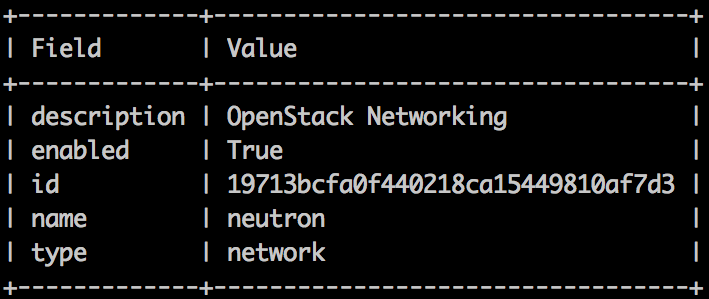
- Run a test OpenStack API query to check the availability of services. For example, we can check the status of the network service as follows:
root@utility-container-55723a11:~# openstack service show neutron
- Another setup validation of our test environment is to check the type of virtualization that has been configured in the compute container. To do so, point to the nova-api-os-compute-container-XXXX container and check the libvirt stanza in the /etc/nova/nova.conf file:
[libvirt]
....
use_virtio_for_bridges = True
cpu_mode = host-model
virt_type = qemu
....
- You can always connect to the OpenStack dashboard by pointing the browser to the Cloud Controller's exposed IP address. The username and password reside in the environment file openrc:
The lxc-* tool provides several commands with great features. A good practice when a container does not function properly because of file corruption, for example, a simple step that will just destroy and recreate it again by running the problematic playbook service. You can use the following command line to stop a container:
# lxc-stop --name <container-name>
To completely destroy a container, use the following command line:
# lxc-destroy --name <container-name>, this will destroy a container.