

Running a company with a DevOps culture is all about adopting the right culture for developers and the operations team to work together. For that, DevOps culture precognizes implementing several engineering best practices by relying on tools and technologies that you will discover throughout the book.
Adopting a DevOps culture
The origin of DevOps
DevOps is a new movement that officially started in 2009 in Belgium, when a group of people met at the first DevOpsDays conference, organized by Patrick Debois, to talk about how to apply some agile concepts to infrastructure.
Agile methodologies transformed the way software is developed. In a traditional waterfall model illustrated in the following diagram, a Product team comes up with specifications, a Design team then creates and defines a certain user experience and user interface, the engineering team then starts implementing the requested product or feature and hands off the code to a QA team, which tests and makes sure that the code behaves correctly according to the design specifications. Once all the bugs are fixed, a Release team packages the final code that can be handed off to the Technical Operations Team, which deploys the code and monitors the service over time:

The increasing complexity of developing certain software and technologies showed some limitations with this traditional waterfall pipeline.
The agile transformation addressed some of these issues, allowing for more interaction between the designers, developers, and testers. This change increased the overall quality of the products as these teams now had the opportunity to iterate more on product development; but apart from this, you would still be in a very classical waterfall pipeline:
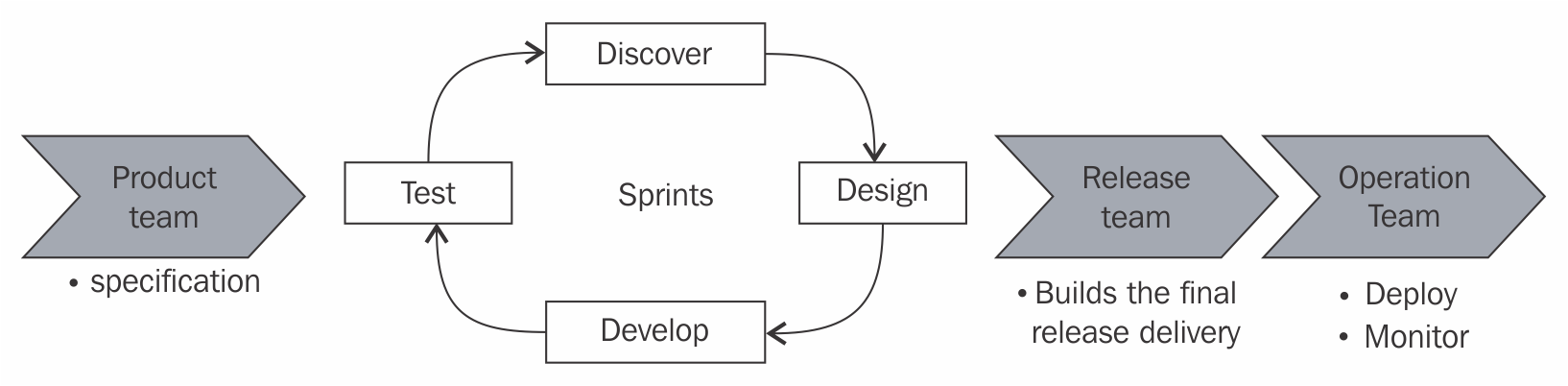
All the agility added by this new process didn't extend past the QA cycles, and it was time to modernize this aspect of the software development life cycle. This foundational change to the agile process, which allows for more collaboration between the designers, developers, and QA teams, is what DevOps was initially after, but very quickly the DevOps movement started rethinking how developers and operations teams could work together.
The developers versus operations dilemma
In a non-DevOps culture, developers are in charge of developing new products and features and maintaining the existing code, but ultimately they are rewarded when their code is shipped. The incentive is to deliver as quickly as possible.
On the other hand, operations teams, in general, have the responsibility to maintain the uptime of production environments. For these teams, change is evil. New features and services increase the risk of having an outage, and therefore it is important to move with caution.
To minimize the risks of having outages, operations teams usually need to schedule any deployment ahead of time so that they can stage and test any production deployment and maximize their chances of success. It is also very common for the enterprise type of software companies to schedule maintenance windows and, in these cases, this means production changes can only be made a few times a quarter.
Unfortunately, a lot of times deployments won't succeed, and there are many possible reasons for that.
Too much code changing at once
There is a certain correlation that can be made between the size of the change and the risk of introducing critical bugs in the product, as the following diagram demonstrates:

Differences in the production environment
It is often the case that the code produced by developers works fine in a development environment but not in production. A lot of the time, that is because the production environment might be very different from other environments and some unforeseen errors may occur. The common mistakes are that in a development environment, services are collocated on the same servers or there isn't the same level of security, so services can communicate with one another in development but not in production. Another issue is that the development environment might not run the same versions of a certain library, and therefore the interface to communicate with them might differ. The development environment may be running a newer version of a service that has new features that production doesn't have yet, or it's simply a question of scale. The dataset used in development isn't as big as that used in production, and scaling issues might crop up once the new code is out in production.
Communication
The last dilemma relates to bad communication.
As Melvin Conway wrote in How Do Committees Invent? (proposing what is now called Conway's law (http://www.melconway.com/research/committees.html)):
"organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations."
In other words, the product you are building reflects the communication of your organization. A lot of the time, problems don't come from the technology but from the people and organization surrounding the technology. If there is any dysfunction among your developers and operations in the organization, this will show.
In a DevOps culture, developers and operations have a different mindset. They help to break down the silos that surround those teams by sharing responsibilities and adopting similar methodologies to improve productivity. They automate everything and use metrics to measure their success.
Key characteristics of a DevOps culture
As we just said, a DevOps culture relies on a certain number of principles: source control everything, automate everything, and measure everything.
Source control everything
Revision control software has been around for many decades now, but too often only the product code is checked on. When practicing DevOps, not only is the application code checked but also its configuration, tests, documentation, and all the infrastructure automation needed to deploy the application in all environments, and everything goes through the regular review process.
Automate testing
Automated software testing predates the history of DevOps, but it is a good starting point. Too often, developers focus on implementing features and forget to add a test to their code. In a DevOps environment, developers are responsible for adding proper testing to their code. QA teams can still exist; however, similar to other engineering teams, they work on building automation around testing.
This topic could deserve its own book, but in a nutshell, when developing code, keep in mind that there are four levels of testing automation to focus on to successfully implement DevOps:
- Unit test: This is to test the functionality of each code block and function.
- Integration testing: This is to make sure that services and components work together.
- User interface testing: This is often the most challenging one to implement successfully.
- System testing: This is end-to-end testing. Let's take an example of a photo-sharing application. Here, the end-to-end testing could involve opening the homepage, signing in, uploading a photo, adding a caption, publishing the photo, and then signing out.
Automate infrastructure provisioning and configuration
In the last few decades, the size of the average infrastructure and complexity of the stack has skyrocketed. Managing infrastructure on an ad hoc basis, as was once possible, is very error-prone. In a DevOps culture, the provisioning and configuration of servers, networks, and services in general are all done through automation. Configuration management is often what the DevOps movement is known for; however, as you all know now, it is just a small piece of a big puzzle.
Automate deployment
As you will know, it is easier to write software in small chunks and deploy these new chunks as soon as possible to make sure that they are working. To get there, companies practicing DevOps rely on continuous integration and continuous deployment pipelines.
Whenever a new chunk of code is ready, the continuous integration pipeline kicks off. Through an automated testing system, the new code is run through all the relevant tests available. If the new code shows no obvious regression, the code is considered valid and can be merged to the main code base. At that point, without further involvement from the developer, a new version of the service (or application) that includes those new changes will be created and handed off to a system called a continuous deployment system.
The continuous deployment system will take the new builds and automatically deploy them to the different environments available. Depending on the complexity of the deployment pipeline, this might include a staging environment, an integration environment, and sometimes a preproduction environment but ultimately, if everything goes as planned without any manual intervention, this new build will get deployed to production.
One misunderstood aspect about practicing continuous integration and continuous deployment is that new features don't have to be accessible to users as soon as they are developed. In this paradigm, developers rely heavily on feature flagging and dark launches. Essentially, whenever you develop new code and want to hide it from the end users, you set a flag in your service configuration to describe who gets access to the new feature and how. At the engineering level, by dark launching a new feature that way, you can send production traffic to the service but hide it from the UI to see the impact it has on your database, or on performance, for example. At the product level, you can decide to enable the new feature for only a small percentage of your users to see if the new feature is working correctly and if the users who have access to the new feature are more engaged than the control group, for example.
Measure everything
Measure everything is the last major principle that DevOps-driven companies adopt. As W. Edwards Deming said: "If you can't measure it, you can't manage it" DevOps is an ever-evolving process that feeds off those metrics to assess and improve the overall quality of the product and the team working on it.
From a tooling and operating standpoint, here are some of the metrics most organizations look at:
- Check how many builds a day are pushed to production.
- Check how often you need to roll back production in your production environment (this is indicated when your testing hasn't caught an important issue).
- The percentage of code coverage.
- Frequency of alerts resulting in paging the on-call engineers for immediate attention.
- Frequency of outages.
- Application performance.
- Mean time to resolution (MTTR), which is the speed at which an outage or a performance issue can be fixed.
At the organizational level, it is also interesting to measure the impact of shifting to a DevOps culture. While it is a lot harder to measure, you can consider the following points:
- The amount of collaboration across teams
- Team autonomy
- Cross-functional work and team efforts
- Fluidity in the product
- Happiness among engineers
- Attitude toward automation
- Obsession with metrics
As you just saw, having a DevOps culture means, first of all, changing the traditional mindset that developers and operations are two separate silos and make both teams collaborate more during all phases of the software development life cycle.
In addition to a new mindset, DevOps culture requires a specific set of tools geared toward automation, deployment, and monitoring:

http://www.pwc.com/us/en/technology-forecast/2013/issue2/features/cios-agility-stability-paradox.html
Amazon with AWS offers a number of services of the PaaS and SaaS types that will let us do just that.