-
Book Overview & Buying

-
Table Of Contents

Test Driven Machine Learning
By :
Test Driven Machine Learning
By:
Overview of this book
Machine learning is the process of teaching machines to remember data patterns, using them to predict future outcomes, and offering choices that would appeal to individuals based on their past preferences.
Machine learning is applicable to a lot of what you do every day. As a result, you can’t take forever to deliver your first iteration of software. Learning to build machine learning algorithms within a controlled test framework will speed up your time to deliver, quantify quality expectations with your clients, and enable rapid iteration and collaboration.
This book will show you how to quantifiably test machine learning algorithms. The very different, foundational approach of this book starts every example algorithm with the simplest thing that could possibly work. With this approach, seasoned veterans will find simpler approaches to beginning a machine learning algorithm. You will learn how to iterate on these algorithms to enable rapid delivery and improve performance expectations.
The book begins with an introduction to test driving machine learning and quantifying model quality. From there, you will test a neural network, predict values with regression, and build upon regression techniques with logistic regression. You will discover how to test different approaches to naïve bayes and compare them quantitatively, along with how to apply OOP (Object-Oriented Programming) and OOP patterns to test-driven code, leveraging SciKit-Learn.
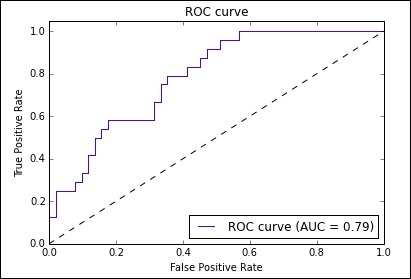
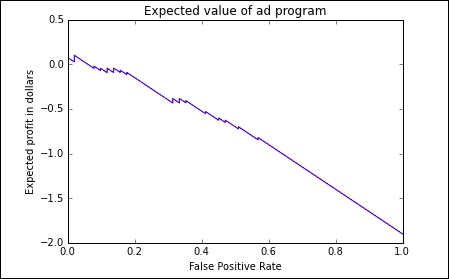
Finally, you will walk through the development of an algorithm which maximizes the expected value of profit for a marketing campaign by combining one of the classifiers covered with the multiple regression example in the book.
Table of Contents (11 chapters)
Preface

 Free Chapter
Free Chapter
1. Introducing Test-Driven Machine Learning
2. Perceptively Testing a Perceptron
3. Exploring the Unknown with Multi-armed Bandits
4. Predicting Values with Regression
5. Making Decisions Black and White with Logistic Regression
6. You're So Naïve, Bayes
7. Optimizing by Choosing a New Algorithm
8. Exploring scikit-learn Test First
9. Bringing It All Together
Index