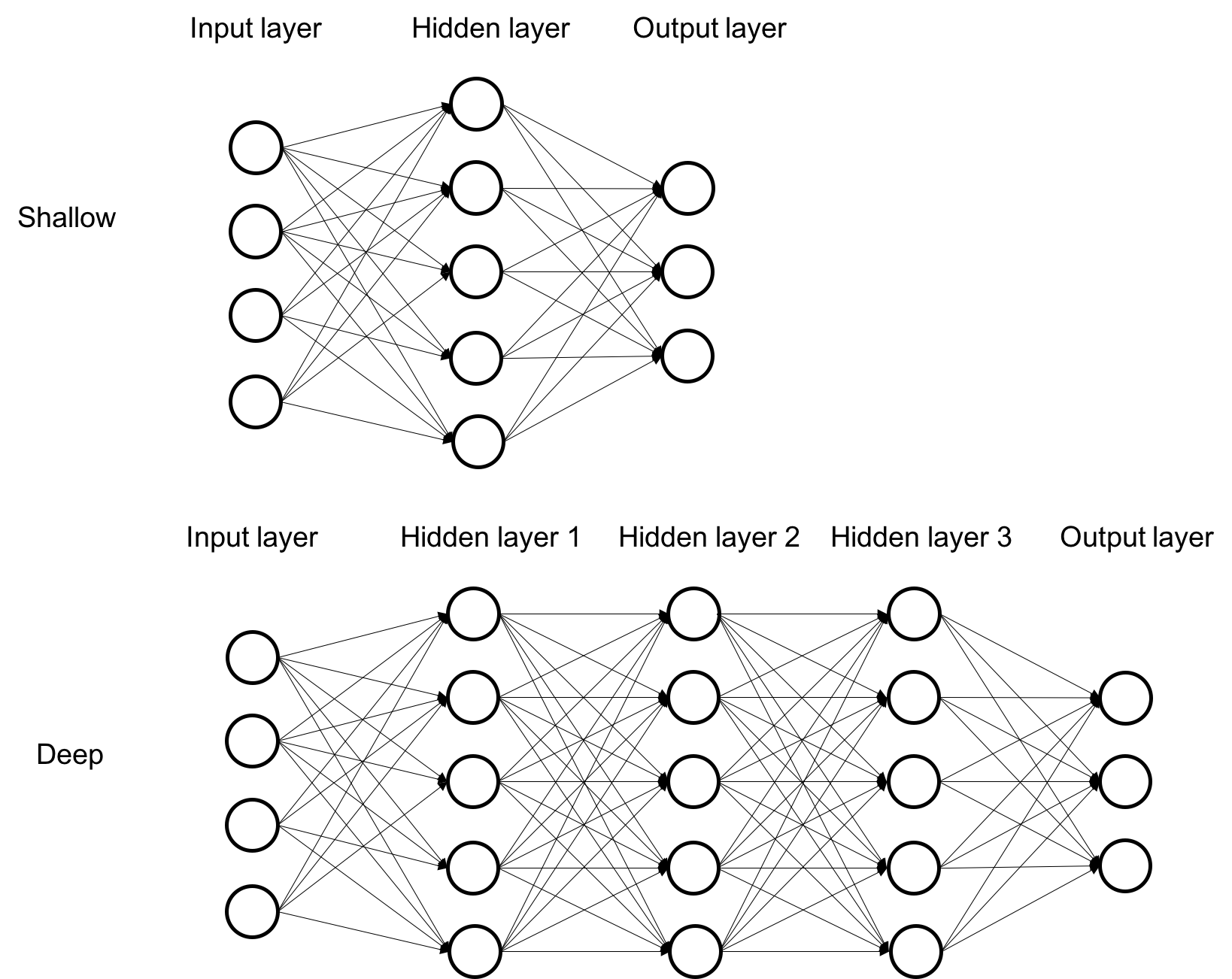
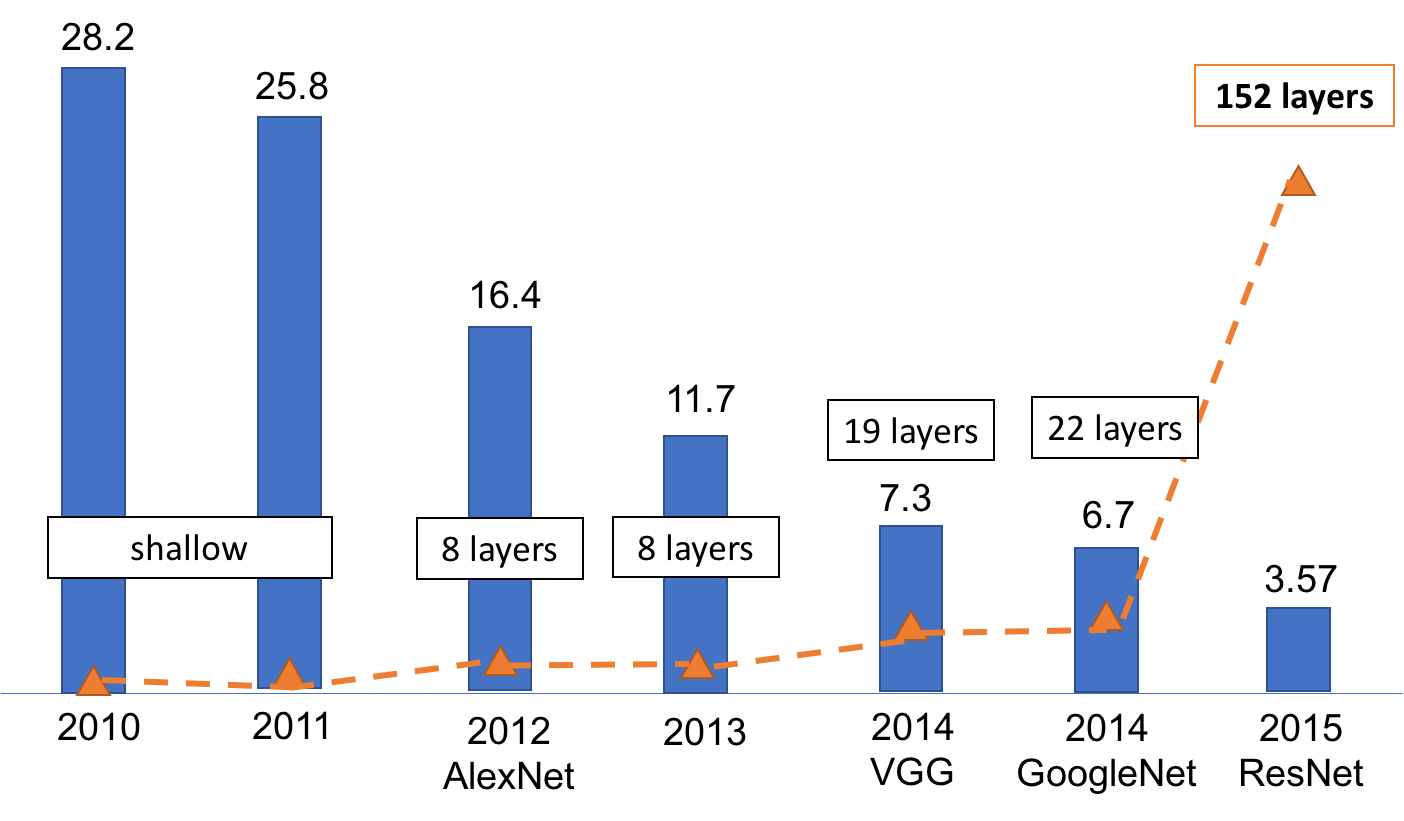
So far we discussed what is deep learning and the history of deep learning. But why is it so popular now? In this section, we talk about advantages of deep learning over traditional shallow methods and its significant impact in a couple of technical fields.
-
Book Overview & Buying

-
Table Of Contents

Deep Learning Essentials
By :
Deep Learning Essentials
By:
Overview of this book
Deep Learning a trending topic in the field of Artificial Intelligence today and can be considered to be an advanced form of machine learning.
This book will help you take your first steps in training efficient deep learning models and applying them in various practical scenarios. You will model, train, and deploy different kinds of neural networks such as CNN, RNN, and will see some of their applications in real-world domains including computer vision, natural language processing, speech recognition, and so on. You will build practical projects such as chatbots, implement reinforcement learning to build smart games, and develop expert systems for image captioning and processing using Python library such as TensorFlow. This book also covers solutions for different problems you might come across while training models, such as noisy datasets, and small datasets.
By the end of this book, you will have a firm understanding of the basics of deep learning and neural network modeling, along with their practical applications.
Table of Contents (12 chapters)
Preface
 Free Chapter
Free Chapter
Why Deep Learning?
Getting Yourself Ready for Deep Learning
Getting Started with Neural Networks
Deep Learning in Computer Vision
NLP - Vector Representation
Advanced Natural Language Processing
Multimodality
Deep Reinforcement Learning
Deep Learning Hacks
Deep Learning Trends
Other Books You May Enjoy