-
Book Overview & Buying

-
Table Of Contents

Learning Apache Spark 2
By :
Learning Apache Spark 2
By:
Overview of this book
Apache Spark has seen an unprecedented growth in terms of its adoption over the last few years, mainly because of its speed, diversity and real-time data processing capabilities. It has quickly become the preferred choice of tool for many Big Data professionals looking to find quick insights from large chunks of data. This book introduces you to the Apache Spark framework, and familiarizes you with all the latest features and capabilities introduced in Spark 2.
Starting with a detailed introduction to Spark’s architecture and the installation procedure, this book covers everything you need to know about the Spark framework in the most practical manner. You will learn how to perform the basic ETL activities using Spark, and work with different components of Spark such as Spark SQL, as well as the Dataset and DataFrame APIs for manipulating your data. Then, you will perform machine learning using Spark MLlib, as well as perform streaming analytics and graph processing using the Spark Streaming and GraphX modules respectively. The book also gives special emphasis on deploying your Spark models, and how they can be operated in a clustered mode.
During the course of the book, you will come across implementations of different real-world use-cases and examples, giving you the hands-on knowledge you need to use Apache Spark in the best possible manner.
Table of Contents (12 chapters)
Preface

 Free Chapter
Free Chapter
1. Architecture and Installation
2. Transformations and Actions with Spark RDDs
3. ETL with Spark
4. Spark SQL
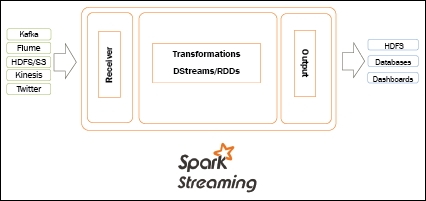
5. Spark Streaming
6. Machine Learning with Spark
7. GraphX
8. Operating in Clustered Mode
9. Building a Recommendation System
10. Customer Churn Prediction